






L’elaborazione del linguaggio naturale (NLP) ha fatto molta strada negli ultimi anni, grazie ai progressi dell’apprendimento automatico e dell’intelligenza artificiale. Uno degli sviluppi più interessanti in questo campo è l’emergere dei Large Language Models (LLM). Questi modelli sono in grado di elaborare grandi quantità di dati testuali e di generare risposte simili a quelle umane. Hanno già dimostrato di essere molto promettenti in varie applicazioni come i chatbot, la traduzione linguistica e la creazione di contenuti. In questa sezione del blog esploreremo cosa sono gli LLM, come funzionano e il loro potenziale impatto sulla PNL.
Discuteremo anche alcune delle sfide che si presentano con l’utilizzo di questi modelli e come i ricercatori stanno lavorando per superarle. Unitevi a noi per addentrarvi nell’affascinante mondo dei Large Language Models e scoprire il loro ruolo nel plasmare il futuro dell’elaborazione del linguaggio naturale.

Cosa sono i modelli linguistici di grandi dimensioni?
I modelli linguistici di grandi dimensioni, o LLM in breve, sono un tipo di modello di apprendimento automatico che viene addestrato su enormi quantità di dati testuali. In questo modo, possono essere utilizzati per generare testi simili a quelli umani, completare vari compiti linguistici e persino comprendere meglio il linguaggio umano.
Un esempio di LLM è il modello transformer, molto utilizzato negli ultimi anni per le sue eccezionali prestazioni nella generazione di testi quasi indistinguibili da quelli scritti dall’uomo. Tuttavia, l’addestramento di modelli linguistici di grandi dimensioni non è un compito facile, poiché richiede enormi quantità di dati e risorse di calcolo.
Tuttavia, i vantaggi di sfruttare questi modelli per le applicazioni di elaborazione del linguaggio naturale (NLP) sono enormi, in quanto sono in grado di trasformare il modo in cui interagiamo con il linguaggio e le informazioni. Nelle prossime sezioni esploreremo il potenziale degli LLM in NLP, nonché le sfide e i vantaggi del loro utilizzo.
Il potenziale dei modelli linguistici di grandi dimensioni nell'elaborazione del linguaggio naturale (NLP)
I modelli linguistici di grandi dimensioni (LLM) hanno rivoluzionato il campo dell’elaborazione del linguaggio naturale (NLP), sbloccando il potenziale delle macchine di comprendere e generare un linguaggio simile a quello umano. Un esempio notevole è il modello GPT-3 (Generative Pre-trained Transformer 3) di OpenAI, in grado di generare un testo convincente e difficilmente distinguibile da quello scritto dall’uomo. I LLM vengono addestrati su enormi quantità di dati provenienti da fonti diverse, consentendo loro di apprendere le sfumature del linguaggio e il modo in cui viene utilizzato in vari contesti. Inoltre, questi modelli possono essere perfezionati per adattarsi a compiti specifici di NLP, come la traduzione linguistica, la sintesi o la sentiment analysis. Tuttavia, l’addestramento di tali modelli comporta delle sfide, dall’enorme quantità di risorse informatiche necessarie alle questioni etiche relative ai contenuti utilizzati per l’addestramento.
Sfide nell'addestramento e nella distribuzione di modelli linguistici di grandi dimensioni
Negli ultimi anni, le sfide legate all’addestramento e all’impiego di modelli linguistici di grandi dimensioni (LLM) sono state una delle principali preoccupazioni nel campo dell’elaborazione del linguaggio naturale (NLP).
- Accesso alle risorse necessarie per la formazione dei LLM a causa delle enormi quantità di dati richiesti
- Elevati costi associati alla formazione dei laureati magistrali
- La notevole potenza di calcolo richiesta per gli LLM, che può costituire un ostacolo alla loro diffusione.
- Garantire che i dati di addestramento rappresentino accuratamente i compiti che il modello dovrà svolgere.
- Manutenzione costosa degli LLM a causa della loro complessità e delle loro dimensioni, compresi gli aggiornamenti e la messa a punto periodici
- Affrontare queste sfide è fondamentale per un’implementazione di successo e per realizzare il potenziale dei LLM in NLP.
Vantaggi dello sfruttamento di modelli linguistici di grandi dimensioni per le applicazioni NLP
Uno dei principali vantaggi dell’utilizzo dei LLM è la loro capacità di generare testi con elevata precisione e fluidità. Ad esempio, il famoso modello GPT-3 è in grado di generare articoli, poesie e persino codice informatico molto simili a quelli scritti dagli esseri umani.
Un altro vantaggio dei LLM è che possono essere addestrati su grandi quantità di dati e poi utilizzati per eseguire varie attività di NLP. Ciò significa che invece di addestrare un modello separato per ogni attività, si può avere un unico modello in grado di eseguire più attività. Si tratta del cosiddetto apprendimento per trasferimento, che ha dimostrato di migliorare le prestazioni dei modelli NLP.
Fortunatamente, i recenti progressi nell’apprendimento automatico e lo sviluppo di nuove architetture LLM, come i trasformatori, hanno reso più semplice l’addestramento e l’utilizzo di LLM per applicazioni NLP. In generale, l’utilizzo degli LLM per le applicazioni NLP può portare a prestazioni migliori, a un uso più efficiente delle risorse e a un’implementazione più rapida di nuove soluzioni NLP.
A cosa servono i modelli linguistici di grandi dimensioni
Come abbiamo già detto, l’intelligenza artificiale dei LLM può elaborare e generare un linguaggio simile a quello umano. Questi modelli hanno rivoluzionato il campo dell’elaborazione del linguaggio naturale, consentendo alle macchine di comprendere e rispondere al linguaggio umano in modo più sofisticato che mai. Un esempio di LLM è
IA generativa
che utilizza tecniche di apprendimento profondo all’avanguardia per generare testi di alta qualità.
L’intelligenza artificiale generativa funziona con l’addestramento su grandi quantità di dati testuali, come libri, articoli e siti web. Il modello impara quindi a identificare schemi e relazioni tra parole, frasi e frasi. Questo gli permette di generare un nuovo testo grammaticalmente corretto, coerente e talvolta anche creativo.
Esempi
Dopo la formazione di un LLM, si gettano le basi per l’utilizzo dell’IA nelle applicazioni pratiche. Con l’ausilio di prompt per interrogare l’LLM, è possibile generare risposte attraverso l’inferenza del modello che possono assumere varie forme, come risposte a domande, testi o immagini create ex novo e contenuti riassunti. Questo processo offre un immenso potenziale di miglioramento della produttività e dell’efficienza in numerosi settori.
- Generazione del testo. La capacità di generare testo su qualsiasi argomento su cui il LLM è stato addestrato è un caso d’uso primario.
- Traduzione. Per i LLM formati su più lingue, la capacità di tradurre da una lingua all’altra è una caratteristica comune.
- Riassunto dei contenuti. Riassumere blocchi o più pagine di testo è una funzione utile delle LLM.
- Riscrivere i contenuti. Un’altra possibilità è quella di riscrivere una sezione di testo.
- Classificazione e categorizzazione. Un LLM è in grado di classificare e categorizzare i contenuti.
- Analisi del sentimento. La maggior parte degli LLM può essere utilizzata per la sentiment analysis, per aiutare gli utenti a comprendere meglio l’intento di un contenuto o di una particolare risposta.
- IA conversazionale e chatbot. I LLM possono consentire una conversazione con l’utente in modo tipicamente più naturale rispetto alle vecchie generazioni di tecnologie AI.
Diversi tipi di modelli linguistici di grandi dimensioni (LLM)
Negli ultimi anni sono diventati sempre più popolari grazie alla loro capacità di eseguire un’ampia gamma di compiti di elaborazione del linguaggio naturale, come la classificazione dei testi, l’analisi del sentiment e la traduzione automatica. Esistono diversi tipi di LLM oggi disponibili, ognuno con caratteristiche e applicazioni uniche. In questo articolo esploreremo i diversi tipi di modelli linguistici di grandi dimensioni e i loro rispettivi punti di forza e di debolezza.

1. Modelli GPT (Generative Pre-trained Transformer): sviluppato da OpenAI. Questo modello è stato apprezzato per la sua capacità di svolgere compiti come scrivere testi, rispondere a domande e persino creare poesie originali. Si tratta di un tipo di modello linguistico che utilizza un’architettura basata su trasformatori ed è pre-addestrato su enormi quantità di dati testuali. Tra gli esempi vi sono il GPT-2, il GPT-3 e, recentemente, il GPT-4. Leggete questo articolo per saperne di più sulle
differenze tra GPT-3 e GPT-4.
2. Modelli BERT (Bidirectional Encoder Representations from Transformers): Si tratta di un altro tipo di modello linguistico basato su trasformatori che viene addestrato utilizzando contesti sia da sinistra a destra che da destra a sinistra, consentendogli di comprendere il contesto in cui le parole appaiono in una frase. Gli esempi includono BERT-base e BERT-grande.
3. XLNet: Si tratta di una variante dell’architettura basata sui trasformatori che utilizza un approccio autoregressivo per generare sequenze, consentendo previsioni più accurate.
4. T5 (Text-to-Text Transfer Transformer): Si tratta di un modello linguistico sviluppato da Google in grado di eseguire diverse operazioni di elaborazione del linguaggio naturale, come riassunti, traduzioni, risposte a domande e altro.
5. RoBERTa (Robustly Optimized BERT Approach): Si tratta di una variante del modello BERT che è stata ottimizzata per ottenere migliori prestazioni in vari compiti di comprensione del linguaggio naturale.
6. ALBERT (A Lite BERT): Si tratta di una versione più piccola del modello BERT che utilizza tecniche di condivisione dei parametri per ridurre l’uso della memoria e migliorare l’efficienza dell’addestramento, pur mantenendo un’elevata precisione.
7. ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately): Si tratta di un nuovo metodo di pre-addestramento per i modelli linguistici che sostituisce alcuni token del testo in ingresso con alternative plausibili e addestra il modello a prevedere se ogni token è stato sostituito o meno.
Differenza tra GPT-3 e GPT-4
Al momento, il GPT-4 è appena stato rilasciato, quindi non è ancora possibile fare un confronto tecnologico dettagliato tra GPT-4 e GPT-3. Tuttavia, in termini di prestazioni o capacità, i progressi sono già visibili. Ecco i cambiamenti principali che possiamo notare nel GPT-4 rispetto al GPT-3:

GPT-3
GPT-4
- 175 miliardi di parametri
- Formazione su una vasta gamma di fonti, tra cui libri, articoli e siti web.
- Supporta oltre 40 lingue diverse
- Riesce a generare un testo coerente con pochi esempi
- Riesce a comprendere il contesto e a generare un testo pertinente al contesto dato.
- Ha dimostrato una notevole accuratezza nella generazione di testi
- Conoscenza limitata degli eventi successivi al 2021
- Uscita: Novembre 2022
- Varianti disponibili sul Playground OpenAI e disponibili per uso commerciale attraverso i piani tariffari OpenAI
- ca. 1.000 miliardi di parametri
- Addestrati su insiemi di dati più ampi e diversificati, comprendenti sia immagini che testi.
- Supera il GPT-3 in 24 lingue testate
- Migliori capacità di apprendimento con pochi colpi e input visivi
- Può comprendere un contesto più lungo e generare un testo più pertinente
- Maggiore accuratezza, soprattutto in caso di elevata complessità
- Conoscenza limitata degli eventi successivi al 2021
- Uscita: Marzo 2023
- Disponibile tramite abbonamento ChatGPT Plus e lista d’attesa Accesso aperto al GPT-4 tramite API OpenAI
neuroflash come esempio per le applicazioni GPT-3 e GPT-4
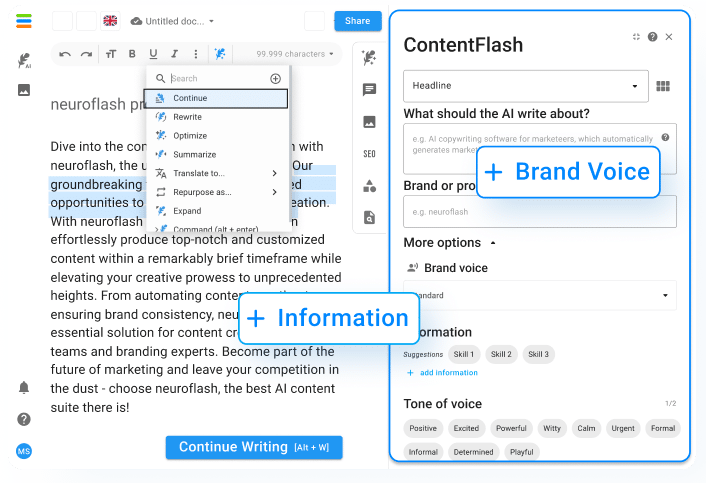
neuroflash combina sia GPT-3 che GPT-4 in molte applicazioni come la creazione di contenuti, la chat AI, la risposta alle domande e molto altro ancora. In questo modo, neuroflash consente agli utenti di creare diversi testi e documenti sulla base di un breve briefing. Con oltre 100 tipi di testo diversi, l’intelligenza artificiale di neuroflash può generare testi per qualsiasi scopo. Ad esempio, se volete creare una descrizione di un prodotto con neuroflash, dovete solo descrivere brevemente il vostro prodotto all’intelligenza artificiale e il generatore farà il resto:
Con neuroflash, potete attingere al vostro potenziale creativo e liberare il narratore che è in voi. Che si tratti di un racconto breve o di un romanzo epico, questa tecnologia all’avanguardia vi aiuterà a creare personaggi convincenti e trame avvincenti che terranno i lettori con il fiato sospeso.
ChatFlash:
Grazie alle funzionalità integrate, come i modelli di prompt pronti all’uso e le personalità, ChatFlash offre un’alternativa più efficiente a ChatGPT. alternativa a ChatGPT.
- Modelli: Lasciatevi ispirare dall’ampia selezione di modelli di testo per iniziare ancora più velocemente. Determinate il tipo di testo che volete generare con ChatFlash e otterrete subito i suggerimenti per un prompt adatto.
- Personalità: Si può specificare chi si vuole che sia la piuma magica. Con le personalità è possibile personalizzare l’ambito della chat per ottenere risultati ancora più appropriati e mirati. L’output generato da ChatFlash è strettamente legato alla personalità selezionata e si adatta al contesto della conversazione.

Flusso di lavoro Articolo di blog ottimizzato per la SEO:
Con il nostro flusso di lavoro SEO, potete essere certi che ogni articolo prodotto sarà ottimizzato per ottenere il massimo impatto. Dite addio alla frustrazione dei bassi tassi di coinvolgimento e date il benvenuto a un mondo in cui il vostro contenuto è il re.
Il nostro team di esperti si dedica a rimanere all’avanguardia quando si tratta di best practice SEO, assicurando che i nostri clienti ricevano solo il miglior servizio possibile. Sappiamo quanto sia importante per aziende come la vostra rimanere competitive in un panorama digitale in continua evoluzione, ed è per questo che ci impegniamo a fornire soluzioni all’avanguardia progettate appositamente per le vostre esigenze.
Il flusso di lavoro SEO è disponibile solo per gli utenti del piano Pro o superiore (e dei vecchi piani Power e Premium). Aggiornate subito il vostro account.

Mentre si lavora con il flusso di lavoro SEO del blog, è possibile aggiungere altri elementi, opzionali, per ottimizzare il risultato dell’articolo del blog. Questi sono i punti salienti del nuovo flusso di lavoro SEO di Contentflash:
- Generazione basata sull’inserimento di parole chiave
- Ottimizzazione SEO automatica (WDF*IDF)
- Collegato a Internet: Rilevamento in tempo reale delle domande “anche gli utenti chiedono” e creazione delle relative risposte.
- Multimedia: Integrazione di immagini Unsplash e video YouTube nell’articolo
- Suggerimenti di riferimento per l’utilizzo dei backlink
Domande frequenti
Cosa sono i modelli linguistici di grandi dimensioni nell'IA?
Sistemi avanzati di intelligenza artificiale in grado di comprendere, elaborare e generare un linguaggio naturale simile a quello umano. Questi modelli utilizzano grandi quantità di dati, tra cui testi, immagini e audio, per imparare come funziona il linguaggio umano. Sono progettati per elaborare informazioni contestuali, in modo da comprendere frasi e paragrafi nel loro insieme, anziché interpretare ogni singola parola in modo indipendente.
Uno dei modelli linguistici più famosi è il GPT-3, o Generative Pre-trained Transformer 3, sviluppato da OpenAI. Ha la capacità di generare testi coerenti e naturali e può persino scrivere saggi, racconti o poesie difficilmente distinguibili da ciò che potrebbe scrivere un essere umano.
Questi modelli hanno implicazioni potenzialmente trasformative in un’ampia gamma di settori, dalla creazione di contenuti al servizio clienti e alla comunicazione, all’istruzione e alla ricerca. Tuttavia, lo sviluppo e l’implementazione di questi strumenti suscitano anche preoccupazioni di carattere etico, in particolare per quanto riguarda questioni come la parzialità dei dati e l’uso improprio da parte di malintenzionati.
Che cos'è la teoria dei modelli linguistici di grandi dimensioni?
L’esempio più importante di modelli linguistici di grandi dimensioni è la serie GPT (Generative Pre-trained Transformer) di OpenAI, che consiste in modelli multipli addestrati su miliardi di parole provenienti da fonti internet. Questi modelli sono stati utilizzati per diversi compiti di elaborazione del linguaggio naturale, tra cui la traduzione automatica, l’analisi del sentimento e la sintesi di testi.
Il vantaggio principale dei modelli linguistici di grandi dimensioni è la loro capacità di generare testi dal suono naturale e simile a quello umano, che li rende strumenti preziosi nei settori legati alle lingue, come la creazione di contenuti e il copywriting. Tuttavia, alcuni critici sostengono che l’uso di modelli linguistici di grandi dimensioni può avere implicazioni etiche, come potenziali pregiudizi o la possibilità di essere utilizzati per scopi malevoli.
Quali sono i principali modelli linguistici di grandi dimensioni?
Esistono diversi modelli linguistici di grandi dimensioni, tra cui GPT-3, BERT, XLNet e T5.
GPT-3, o Generative Pre-trained Transformer 3, è un modello di elaborazione del linguaggio naturale sviluppato da OpenAI che utilizza l’apprendimento profondo per generare risposte simili a quelle umane alle richieste di testo. Con 175 miliardi di parametri, il GPT-3 è attualmente uno dei più grandi modelli linguistici esistenti.
BERT, o Bidirectional Encoder Representations from Transformers, è un altro modello linguistico su larga scala sviluppato da Google. È stato progettato per addestrare sistemi di apprendimento automatico per compiti di elaborazione del linguaggio naturale, tra cui la risposta a domande e la traduzione linguistica.
XLNet, un successore di BERT, è stato sviluppato dai ricercatori della Carnegie Mellon University e di Google. Utilizza un approccio all’addestramento basato sulle permutazioni, che gli consente di gestire meglio compiti linguistici complessi come le dipendenze a lungo termine e l’ambiguità sintattica.
Infine, T5, o Text-to-Text Transfer Transformer, è un modello linguistico sviluppato da Google che può essere facilmente messo a punto per una serie di compiti di elaborazione del linguaggio naturale. È in grado di eseguire compiti come la sintesi, la traduzione e la risposta alle domande ed è stato utilizzato in applicazioni che vanno dai chatbot ai motori di ricerca.
Conclusione
In sintesi, i Large Language Models rappresentano una svolta significativa nello sviluppo dell’intelligenza artificiale. Man mano che questi modelli continueranno a migliorare, probabilmente svolgeranno un ruolo sempre più importante nella nostra vita quotidiana, dai chatbot che forniscono assistenza ai clienti agli assistenti virtuali che ci aiutano a gestire i nostri impegni.
Questi modelli hanno migliorato in modo significativo le prestazioni di diverse applicazioni di elaborazione del linguaggio naturale, tra cui i chatbot, la traduzione linguistica, la classificazione dei testi e l’analisi del sentiment. Hanno inoltre consentito lo sviluppo di nuove applicazioni basate sul linguaggio, in grado di comprendere e generare contenuti linguistici simili a quelli umani con elevata precisione ed efficienza.






{kind=link}