






Natural Language Processing (NLP) heeft de afgelopen jaren een lange weg afgelegd, dankzij de vooruitgang in machinaal leren en kunstmatige intelligentie. Een van de spannendste ontwikkelingen op dit gebied is de opkomst van grote taalmodellen (LLM’s). Deze modellen zijn in staat om enorme hoeveelheden tekstgegevens te verwerken en mensachtige antwoorden op zoekopdrachten te genereren. Ze zijn al veelbelovend gebleken in verschillende toepassingen, zoals chatbots, taalvertalingen en contentcreatie. In dit bloggedeelte zullen we onderzoeken wat LLM’s zijn, hoe ze werken en wat hun potentiële impact is op NLP.
We bespreken ook een aantal van de uitdagingen die het gebruik van deze modellen met zich meebrengt en hoe onderzoekers bezig zijn om deze te overwinnen. Duik mee in de fascinerende wereld van grote taalmodellen en ontdek hun rol in het vormgeven van de toekomst van natuurlijke taalverwerking.

Wat zijn grote taalmodellen?
Grote taalmodellen, kortweg LLM’s, zijn een type model voor machinaal leren dat wordt getraind op enorme hoeveelheden tekstgegevens. Hierdoor kunnen ze worden gebruikt om mensachtige tekst te genereren, verschillende taaltaken uit te voeren en zelfs menselijke taal beter te begrijpen.
Een voorbeeld van een LLM is het transformatormodel, dat de afgelopen jaren veel is gebruikt vanwege zijn uitzonderlijke prestaties bij het genereren van tekst die bijna niet te onderscheiden is van door mensen geschreven tekst. Het trainen van grote taalmodellen is echter geen gemakkelijke taak, omdat er enorme hoeveelheden gegevens en rekenkracht voor nodig zijn.
Toch zijn de voordelen van het gebruik van deze modellen voor natuurlijke taalverwerking (NLP) enorm, omdat ze de manier waarop we met taal en informatie omgaan kunnen veranderen. In de volgende paragrafen verkennen we het potentieel van LLM’s in NLP, evenals de uitdagingen en voordelen van het gebruik ervan.
Het potentieel van grote taalmodellen in natuurlijke taalverwerking (NLP)
Grote taalmodellen (LLM’s) hebben een revolutie teweeggebracht op het gebied van natuurlijke taalverwerking (NLP) door het potentieel te ontsluiten voor machines om niet alleen taal te begrijpen maar ook mensachtige taal te genereren. Een opmerkelijk voorbeeld hiervan is OpenAI’s GPT-3 (Generative Pre-trained Transformer 3) model, dat overtuigende tekst kan genereren die moeilijk te onderscheiden is van door mensen geschreven inhoud. LLM’s worden getraind op enorme hoeveelheden gegevens uit verschillende bronnen, waardoor ze de nuances van taal kunnen leren en hoe deze in verschillende contexten wordt gebruikt. Bovendien kunnen deze modellen worden verfijnd om ze aan te passen aan specifieke NLP-taken, zoals taalvertaling, samenvatten of sentimentanalyse. Het trainen van dergelijke modellen brengt echter uitdagingen met zich mee, van de enorme hoeveelheid benodigde rekenkracht tot de ethische kwesties rond de inhoud die voor de training wordt gebruikt.
Uitdagingen bij het trainen en inzetten van grote taalmodellen
Uitdagingen bij het trainen en implementeren van grote taalmodellen (LLM’s) zijn de afgelopen jaren een belangrijk aandachtspunt geweest op het gebied van Natural Language Processing (NLP).
- Toegang tot de nodige middelen voor het opleiden van LLM’s vanwege de enorme hoeveelheden gegevens die nodig zijn
- Hoge kosten voor het opleiden van LLM’s
- Aanzienlijke rekenkracht vereist voor LLM’s, wat een belemmering kan zijn voor wijdverspreide toepassing
- Ervoor zorgen dat de trainingsgegevens nauwkeurig de taken weergeven waarvoor het model zal worden ingezet
- Duur onderhoud van LLM’s vanwege hun complexiteit en omvang, inclusief regelmatige updates en fijnafstelling
- Het aanpakken van deze uitdagingen is cruciaal voor een succesvolle inzet en het realiseren van het potentieel van LLM’s in NLP.
Voordelen van het gebruik van grote taalmodellen voor NLP-toepassingen
Een van de belangrijkste voordelen van het gebruik van LLM’s is dat ze zeer nauwkeurig en vloeiend tekst kunnen genereren. Het beroemde GPT-3 model kan bijvoorbeeld artikelen, gedichten en zelfs computercode genereren die erg lijken op door mensen geschreven artikelen.
Een ander voordeel van LLM’s is dat ze kunnen worden getraind op grote hoeveelheden gegevens en vervolgens kunnen worden gebruikt om verschillende NLP-taken uit te voeren. Dit betekent dat je, in plaats van voor elke taak een apart model te trainen, één model kunt hebben dat meerdere taken kan uitvoeren. Dit staat bekend als transfer learning en het is aangetoond dat het de prestaties van NLP-modellen verbetert.
Gelukkig hebben recente ontwikkelingen op het gebied van machinaal leren en de ontwikkeling van nieuwe LLM-architecturen zoals Transformers het gemakkelijker gemaakt om LLM’s te trainen en te gebruiken voor NLP-toepassingen. In het algemeen kan het gebruik van LLM’s voor NLP-toepassingen leiden tot betere prestaties, efficiënter gebruik van bronnen en snellere implementatie van nieuwe NLP-oplossingen.
Waar worden grote taalmodellen voor gebruikt
Zoals we al hebben vermeld, kan de kunstmatige intelligentie van LLM’s mensachtige taal verwerken en genereren. Deze modellen hebben een revolutie teweeggebracht op het gebied van de verwerking van natuurlijke taal door machines in staat te stellen menselijke taal op een verfijndere manier te begrijpen en erop te reageren dan ooit tevoren. Een voorbeeld van een LLM is
Generatieve AI
dat geavanceerde deep learning-technieken gebruikt om tekst van hoge kwaliteit te genereren.
Generatieve AI werkt door te trainen op enorme hoeveelheden tekstgegevens, zoals boeken, artikelen en websites. Het model leert dan patronen en relaties tussen woorden, zinnen en zinnen te herkennen. Hierdoor kan het nieuwe tekst genereren die grammaticaal correct, coherent en soms zelfs creatief is.
Voorbeelden
Met een LLM is een basis gelegd voor het gebruik van AI in praktische toepassingen. Met behulp van prompts om de LLM te ondervragen, kunnen antwoorden worden gegenereerd via modelinferentie die verschillende vormen kunnen aannemen, zoals antwoorden op vragen, nieuw gemaakte tekst of afbeeldingen en samengevatte inhoud. Dit proces biedt enorme mogelijkheden voor het verbeteren van de productiviteit en efficiëntie in tal van industrieën.
- Tekst genereren. De mogelijkheid om tekst te genereren over elk onderwerp waar de LLM op getraind is, is een primaire toepassing.
- Vertaling. Voor LLM’s die in meerdere talen zijn opgeleid, is het vermogen om van de ene taal naar de andere te vertalen een veelvoorkomend kenmerk.
- Samenvatting van de inhoud. Het samenvatten van blokken of meerdere pagina’s tekst is een nuttige functie van LLM’s.
- Inhoud herschrijven. Een stuk tekst herschrijven is een andere mogelijkheid.
- Classificatie en categorisatie. Een LLM kan inhoud classificeren en categoriseren.
- Sentimentanalyse. De meeste LLM’s kunnen worden gebruikt voor sentimentanalyse om gebruikers te helpen de intentie van een stuk inhoud of een bepaalde reactie beter te begrijpen.
- Conversationele AI en chatbots. LLM’s kunnen een gesprek met een gebruiker mogelijk maken op een manier die doorgaans natuurlijker is dan oudere generaties AI-technologieën.
Verschillende soorten grote taalmodellen (LLM)
Ze zijn de afgelopen jaren steeds populairder geworden vanwege hun vermogen om een breed scala aan natuurlijke taalverwerkingstaken uit te voeren, zoals tekstclassificatie, sentimentanalyse en automatische vertaling. Er zijn tegenwoordig verschillende soorten LLM’s beschikbaar, elk met hun eigen unieke kenmerken en toepassingen. In dit artikel zullen we de verschillende typen grote taalmodellen en hun respectievelijke sterke en zwakke punten onderzoeken.

1. GPT-modellen (Generative Pre-trained Transformer): ontwikkeld door OpenAI. Dit model wordt geprezen om zijn vermogen om taken uit te voeren zoals het schrijven van tekst, het beantwoorden van vragen en zelfs het maken van originele poëzie. Dit is een type taalmodel dat een op transformatoren gebaseerde architectuur gebruikt en vooraf getraind is op grote hoeveelheden tekstgegevens. Voorbeelden zijn GPT-2, GPT-3 en sinds kort GPT-4. Lees dit artikel om meer te weten te komen over de
verschillen tussen GPT-3 en GPT-4.
2. BERT-modellen (Bidirectionele Encoder Representaties van Transformatoren): Dit is een ander type op transformatoren gebaseerd taalmodel dat wordt getraind met behulp van zowel links-naar-rechts als rechts-naar-links contexten, waardoor het de context begrijpt waarin woorden in een zin voorkomen. Voorbeelden zijn BERT-base en BERT-groot.
3. XLNet: Dit is een variant van de op transformatoren gebaseerde architectuur die een autoregressieve benadering gebruikt om sequenties te genereren, waardoor nauwkeurigere voorspellingen mogelijk zijn.
4. T5 (Text-to-Text Transfer Transformer): Dit is een taalmodel ontwikkeld door Google dat verschillende natuurlijke taalverwerkingstaken kan uitvoeren, zoals samenvatten, vertalen, vragen beantwoorden en meer.
5. RoBERTa (Robuust Geoptimaliseerde BERT-aanpak): Dit is een variant van het BERT-model dat is geoptimaliseerd voor betere prestaties op verschillende taken voor het begrijpen van natuurlijke taal.
6. ALBERT (A Lite BERT): Dit is een kleinere versie van het BERT-model dat gebruikmaakt van technieken voor het delen van parameters om het geheugengebruik te verminderen en de trainingsefficiëntie te verbeteren met behoud van een hoge nauwkeurigheid.
7. ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately): Dit is een nieuwe pre-training methode voor taalmodellen die sommige tokens in de input tekst vervangt door plausibele alternatieven en het model traint om te voorspellen of elke token al dan niet vervangen werd.
Verschil tussen GPT-3 vs GPT-4
GPT-4 is nog maar net uit, dus het is nog niet mogelijk om een gedetailleerde technologische vergelijking van GPT-4 vs GPT-3 te maken. Op het gebied van prestaties en mogelijkheden is er echter al vooruitgang te zien. Dit zijn de belangrijkste veranderingen die we kunnen zien in GPT-4 ten opzichte van GPT-3:

GPT-3
GPT-4
- 175 miljard parameters
- Getraind op diverse bronnen, waaronder boeken, artikelen en websites
- Ondersteunt meer dan 40 verschillende talen
- Kan samenhangende tekst genereren met slechts een paar voorbeelden
- Kan context begrijpen en tekst genereren die relevant is voor de gegeven context
- Heeft een indrukwekkende nauwkeurigheid laten zien bij het genereren van tekst
- Beperkte kennis van gebeurtenissen na 2021
- Vrijgave: November 2022
- Variaties beschikbaar op de OpenAI Playground en beschikbaar voor commercieel gebruik via OpenAI prijsplannen
- ca. 1 biljoen parameters
- Getraind op meer diverse en grotere datasets, inclusief afbeeldingen en tekst
- Presteert beter dan GPT-3 in 24 geteste talen
- Betere leermogelijkheden in een paar schoten plus visuele input
- Kan langere context begrijpen en betere relevante tekst genereren
- Verbeterde nauwkeurigheid, vooral bij hoge complexiteit
- Beperkte kennis van gebeurtenissen na 2021
- Vrijgave: Maart 2023
- Beschikbaar via ChatGPT Plus abonnement en wachtlijst open toegang tot GPT-4 via OpenAI API
neuroflash als voorbeeld voor GPT-3- en GPT-4-toepassingen
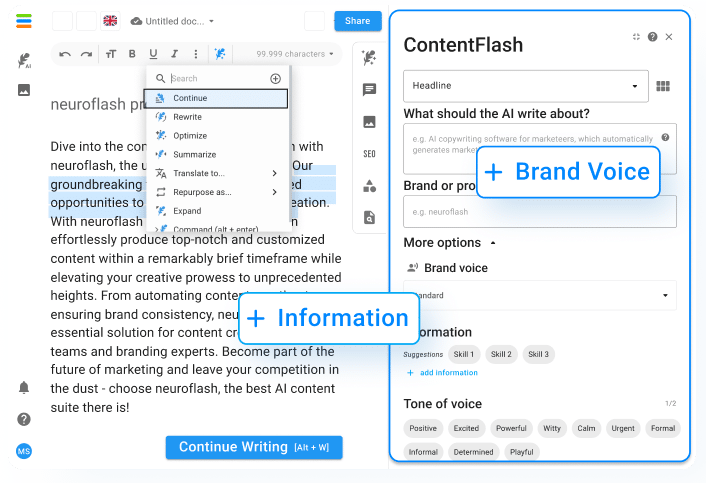
neuroflash combineert zowel GPT-3 als GPT-4 in veel toepassingen zoals het maken van content, AI-chat, het beantwoorden van vragen en nog veel meer. Daarbij stelt neuroflash zijn gebruikers in staat om verschillende teksten en documenten te laten maken op basis van een korte briefing. Met meer dan 100 verschillende tekstsoorten kan de neuroflash AI teksten genereren voor elk doel. Als je bijvoorbeeld een productbeschrijving wilt maken met neuroflash, hoef je alleen maar kort je product te beschrijven aan de AI en de generator doet de rest:
Met neuroflash kun je je creatieve potentieel aanboren en je innerlijke verhalenverteller ontketenen. Of het nu gaat om een kort verhaal of een epische roman, deze geavanceerde technologie helpt je om meeslepende personages en boeiende plots te creëren die lezers op het puntje van hun stoel houden.
ChatFlash:
Met geïntegreerde functies zoals kant-en-klare promptsjablonen en persoonlijkheden biedt ChatFlash een efficiënter alternatief voor ChatGPT.
- Sjablonen: Laat je inspireren door de grote selectie tekstsjablonen om nog sneller aan de slag te gaan. Bepaal wat voor soort tekst je wilt genereren met ChatFlash en krijg meteen suggesties voor een geschikte prompt.
- Persoonlijkheden: Je geeft aan wie je wilt dat de magische veer is. Met persoonlijkheden kun je het bereik van de chat aanpassen om nog meer geschikte en gerichte resultaten te krijgen. De uitvoer die wordt gegenereerd door ChatFlash is nauw verbonden met de geselecteerde persoonlijkheid en past zich aan de context van het gesprek aan.

Workflow SEO-geoptimaliseerd blogartikel:
Met onze SEO-workflow kun je er zeker van zijn dat elk artikel dat je produceert wordt geoptimaliseerd voor een maximale impact. Zeg vaarwel tegen de frustratie van lage engagementpercentages en hallo tegen een wereld waarin je content koning is.
Ons team van experts is toegewijd om voorop te blijven lopen als het gaat om SEO best practices, zodat onze klanten alleen de allerbeste service ontvangen. We begrijpen hoe belangrijk het is voor bedrijven als het uwe om concurrerend te blijven in een steeds veranderend digitaal landschap. Daarom zetten we ons in om geavanceerde oplossingen te bieden die speciaal zijn ontworpen met uw behoeften in gedachten.
De SEO-workflow is alleen beschikbaar voor gebruikers van het Pro-plan en hoger (en de oude Power & Premium-plannen). Upgrade je account nu.

Terwijl je met de Blog SEO workflow werkt, kun je optioneel meer elementen toevoegen om het resultaat van je Blog artikel te optimaliseren. Dit zijn de hoogtepunten van de nieuwe contentflash SEO-workflow die je gezien moet hebben:
- Genereren op basis van uw trefwoordinvoer
- Automatische SEO optimalisatie (WDF*IDF)
- Verbonden met het internet: Real-time detectie van “gebruikers stellen ook” vragen en creatie van de respectievelijke antwoorden.
- Multimedia: Integratie van Unsplash-afbeeldingen en YouTube-video’s in je artikel
- Suggesties van referenties voor het gebruik van backlinks
Veelgestelde vragen
Wat zijn grote taalmodellen in AI?
Geavanceerde kunstmatige intelligentiesystemen die natuurlijke mensachtige taal kunnen begrijpen, verwerken en genereren. Deze modellen gebruiken enorme hoeveelheden gegevens, waaronder tekst, afbeeldingen en audio, om te leren hoe menselijke taal werkt. Ze zijn ontworpen om contextuele informatie te verwerken, zodat ze zinnen en alinea’s als geheel kunnen begrijpen, in plaats van elk afzonderlijk woord afzonderlijk te interpreteren.
Een van de bekendste grote taalmodellen is GPT-3, of Generative Pre-trained Transformer 3, ontwikkeld door OpenAI. Het is in staat om samenhangende en natuurlijk klinkende tekst te genereren en kan zelfs essays, verhalen of poëzie schrijven die moeilijk te onderscheiden zijn van iets wat een mens zou kunnen schrijven.
Deze modellen hebben mogelijk transformerende gevolgen voor een groot aantal sectoren, van contentcreatie tot klantenservice en communicatie, onderwijs en onderzoek. Er zijn echter ook ethische bezwaren rond de ontwikkeling en implementatie ervan, met name rond zaken als bevooroordeelde gegevens en misbruik door slechte actoren.
Wat is de theorie van grote taalmodellen?
Het meest prominente voorbeeld van grote taalmodellen is OpenAI’s GPT-serie (Generative Pre-trained Transformer), die bestaat uit meerdere modellen die zijn getraind op miljarden woorden van internetbronnen. Deze modellen zijn gebruikt voor verschillende natuurlijke taalverwerkingstaken, waaronder automatische vertaling, sentimentanalyse en tekstsamenvattingen.
Het belangrijkste voordeel van grote taalmodellen is hun vermogen om tekst te genereren die natuurlijk en menselijk klinkt, waardoor ze waardevolle hulpmiddelen zijn in taalgerelateerde bedrijfstakken zoals contentcreatie en copywriting. Sommige critici beweren echter dat het gebruik van grote taalmodellen ethische implicaties kan hebben, zoals mogelijke vertekeningen of de mogelijkheid om gebruikt te worden voor kwaadaardige doeleinden.
Wat zijn de grote taalmodellen?
Er zijn verschillende grote taalmodellen, waaronder GPT-3, BERT, XLNet en T5.
GPT-3, of Generative Pre-trained Transformer 3, is een natuurlijk taalverwerkingsmodel ontwikkeld door OpenAI dat deep learning gebruikt om mensachtige reacties op tekstvragen te genereren. Met 175 miljard parameters is GPT-3 momenteel een van de grootste taalmodellen die er bestaan.
BERT, of Bidirectional Encoder Representations from Transformers, is een ander grootschalig taalmodel ontwikkeld door Google. Het is ontworpen om machine-leersystemen te trainen voor natuurlijke taalverwerkingstaken, waaronder het beantwoorden van vragen en het vertalen van talen.
XLNet, een opvolger van BERT, is ontwikkeld door onderzoekers van de Carnegie Mellon University en Google. Het gebruikt een permutatie-gebaseerde aanpak voor training, waardoor het beter om kan gaan met complexe taaltaken zoals lange termijn afhankelijkheden en syntactische ambiguïteit.
Ten slotte is T5, of Text-to-Text Transfer Transformer, een taalmodel ontwikkeld door Google dat gemakkelijk kan worden verfijnd voor een verscheidenheid aan natuurlijke taalverwerkingstaken. Het kan taken uitvoeren zoals samenvatten, vertalen en vragen beantwoorden, en wordt gebruikt in toepassingen variërend van chatbots tot zoekmachines.
Conclusie
In resumé betekenen grote taalmodellen een belangrijke doorbraak in de ontwikkeling van kunstmatige intelligentie. Naarmate deze modellen steeds beter worden, zullen ze waarschijnlijk een steeds belangrijkere rol gaan spelen in ons dagelijks leven – van chatbots die klantenondersteuning bieden tot virtuele assistenten die ons helpen onze agenda’s te beheren.
Deze modellen hebben de prestaties van verschillende natuurlijke taalverwerkingstoepassingen aanzienlijk verbeterd, waaronder chatbots, taalvertalingen, tekstclassificatie en sentimentanalyse. Ze hebben ook de ontwikkeling mogelijk gemaakt van nieuwe taalgebaseerde toepassingen die mensachtige taalinhoud kunnen begrijpen en genereren met hoge nauwkeurigheid en efficiëntie.






{kind=link}