





DeepSeek, a Chinese AI startup, has recently unveiled Janus Pro, an advanced image generator that is making significant waves in the AI community. Positioned as a formidable competitor to established models like OpenAI’s DALL-E 3 and Stability AI’s Stable Diffusion, Janus Pro offers a blend of multimodal understanding and generation capabilities. Let’s dive into!
A Leap in Multimodal AI
Janus Pro is designed to unify visual understanding and generation tasks within a single framework. By decoupling visual encoding into separate pathways, it addresses limitations found in previous models, enhancing both flexibility and performance. This architecture allows Janus Pro to excel in tasks that require both interpreting and generating visual content.
Benchmark Performance
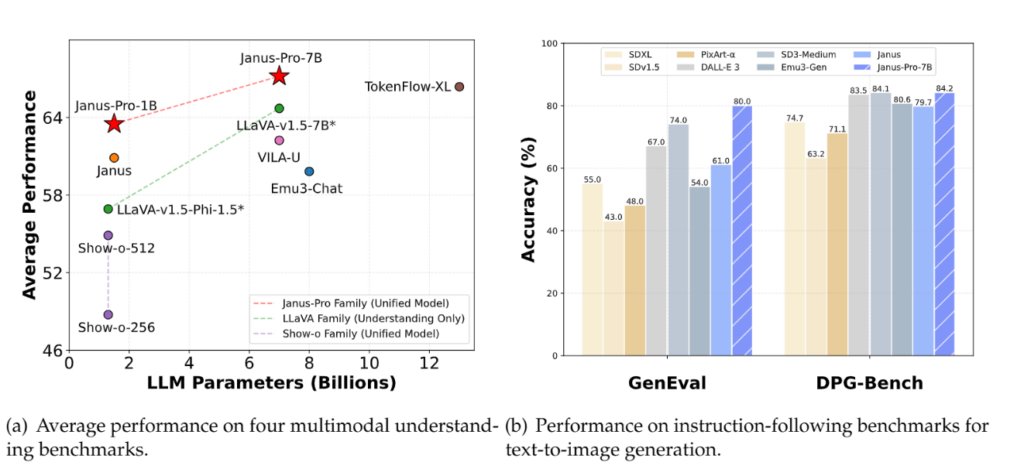
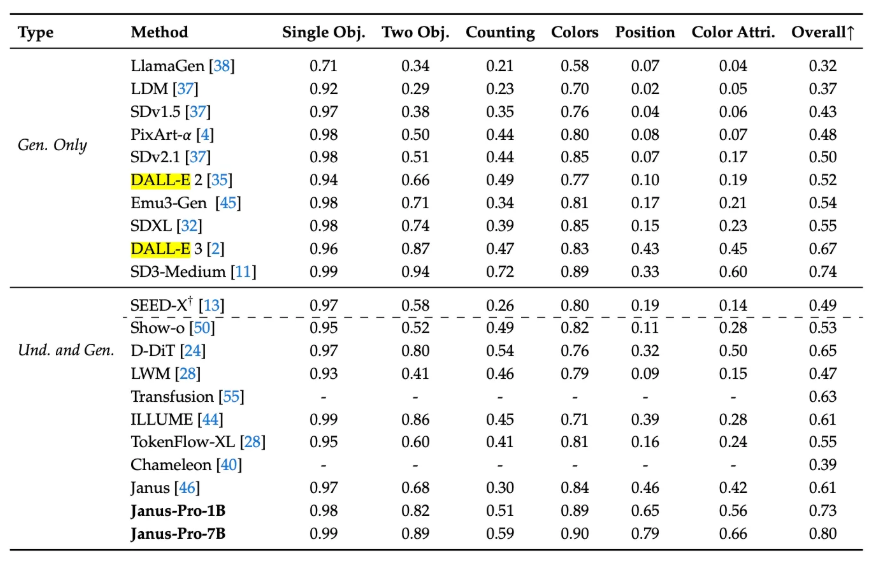
In benchmark evaluations, Janus Pro has demonstrated superior performance. On the GenEval benchmark for text-to-image generation, it achieved an 80% overall accuracy, surpassing DALL-E 3’s 67% and Stable Diffusion 3 Medium’s 74%. Additionally, on the MMBench benchmark for multimodal understanding, the 7B variant of Janus Pro scored 79.2, outperforming other models like TokenFlow-XL and MetaMorph.
Janus Pro's Encoder
At the core of Janus Pro’s architecture is its decoupled visual encoding strategy. For multimodal understanding, it utilizes the SigLIP-L vision encoder, which processes images at a resolution of 384 x 384 pixels. For image generation, Janus Pro employs a vector quantization (VQ) tokenizer, converting images into discrete representations that are then processed by an autoregressive transformer.
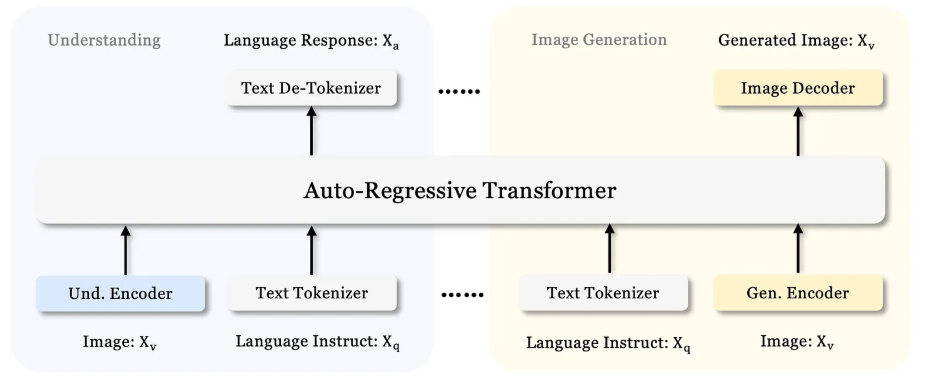
What sets Janus Pro apart is its revolutionary decoupled architecture. Unlike traditional multi-modal models that rely on a single encoder, Janus Pro employs two specialized encoders, each masterfully designed for specific tasks:
- The Understanding Encoder focuses exclusively on visual analysis, processing images to identify objects and interpret relationships within visual content.
- Meanwhile, the Generation Encoder specializes in text-to-image tasks, ensuring high-quality creative outputs with improved aesthetic appeal and compositional accuracy.
This architectural innovation isn’t just theoretical—it translates into tangible improvements in both performance and training efficiency. By allowing each encoder to focus on its specialized task, Janus Pro achieves better results while potentially requiring fewer computational resources.

Janus Pro Qualitative Results
The qualitative results demonstrate impressive performance across multiple dimensions. In the multimodal understanding tests illustrated in Figure 4, Janus-Pro demonstrates exceptional comprehension capabilities across diverse contextual inputs. The model’s performance in these scenarios highlights its sophisticated processing abilities.
The text-to-image generation results, also shown in Figure 4, reveal equally compelling capabilities. Despite operating at a relatively modest resolution of 384 × 384 pixels, Janus-Pro-7B produces highly detailed and realistic images. The model shows particular strength in handling creative and imaginative prompts, successfully translating complex semantic information into coherent visual outputs. Each generated image maintains strong fidelity to the input prompts while demonstrating sophisticated composition and detail work.
The results indicate that Janus-Pro-7B effectively bridges the gap between textual understanding and visual generation, producing outputs that are both technically accomplished and creatively authentic.
Image Description

General Knowledge
Text -to-image Generation

The Power of Synthetic Data
Perhaps one of the most fascinating aspects of Janus Pro’s development is its novel approach to training data. The model incorporates an impressive 72 million high-quality synthetic images, balanced in a 1:1 ratio with real data. This balanced approach has yielded several key benefits:
- Training efficiency has significantly improved
- Image outputs demonstrate enhanced stability
- The accuracy of prompt-to-image alignment has increased
The careful balancing of synthetic and real data represents a thoughtful solution to one of the biggest challenges in AI development: the need for massive amounts of high-quality training data.
Ethical Considerations
While Janus Pro’s capabilities are impressive, they also raise ethical questions. The model’s ability to generate highly realistic images from text prompts necessitates discussions about potential misuse, including the creation of deepfakes or misleading content. As with any powerful technology, it’s crucial to implement guidelines and safeguards to ensure responsible use.
Getting Started with Janus Pro
For those interested in exploring Janus Pro’s capabilities, the model is available on platforms like Hugging Face. Users can experiment with both multimodal understanding and text-to-image generation tasks. Additionally, resources are available to guide users on setting up and running Janus Pro locally, providing hands-on experience with this cutting-edge AI model.
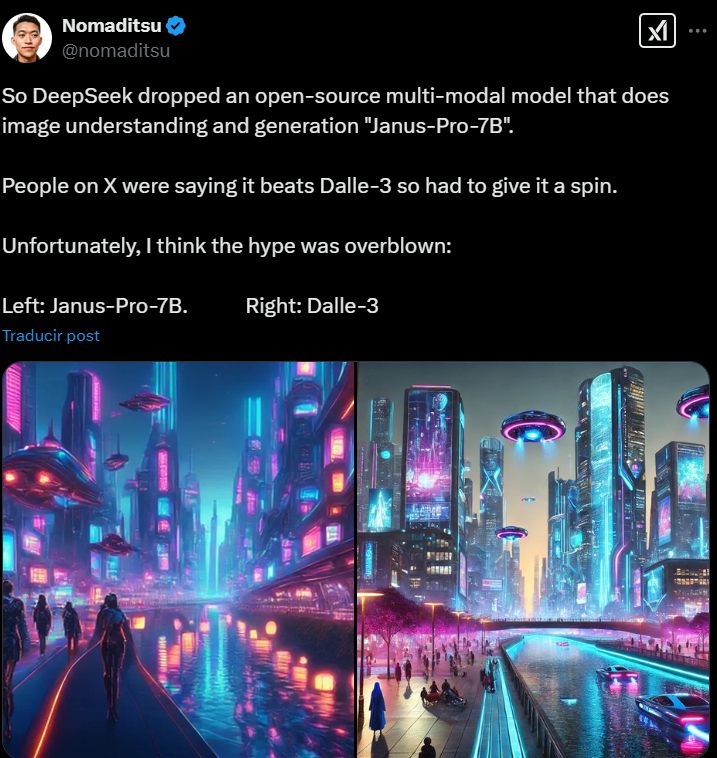
Janus Pro vs DALL·E
While both Janus Pro and DALL-E 3 are designed for text-to-image generation, they differ in architecture and performance. Janus Pro employs a decoupled architecture, separating visual encoding for understanding and generation tasks, which enhances its flexibility and performance. In benchmark evaluations, Janus Pro achieved an 80% overall accuracy in text-to-image tasks, surpassing DALL-E 3’s 67%.
Conclusion
In conclusion, Janus Pro’s innovative architecture and superior benchmark performances position it as a formidable competitor in the AI image generation field. Its decoupled visual encoding approach and advanced processing capabilities offer users a powerful tool for both understanding and generating visual content.
For a more in-depth understanding, you might find the following video insightful: DeepSeek Janus Pro Explained with Hugh Jackman.














