





As artificial intelligence continues to evolve at a rapid pace, the development of advanced large language models (LLMs) has become a cornerstone of innovation across various industries. Among the latest breakthroughs are Gemini 2.0 vs GPT 4o—two state-of-the-art models from OpenAI and Google, respectively. While both represent the pinnacle of AI technology, they are designed with different goals in mind, making them suited for unique applications. In this blog post, we’ll dive into the key differences, benefits, limitations, and provide a final comparison to help you understand which model might be best suited for your needs.
Introducing Gemini 2.0 and Gpt-4o
Before we delve into the specifics, let’s briefly introduce these AI powerhouses.
- Gemini 2.0: Developed by Google, Gemini 2.0 is designed with a strong emphasis on code generation, logical reasoning, and precise instruction following. It’s built to tackle complex tasks and boasts impressive performance in mathematics and coding.
- GPT-4: Created by OpenAI, GPT-4 is renowned for its creative content generation, deep reasoning capabilities, and nuanced understanding of language. It excels at producing human-like text and handling a wide range of tasks, from translation to summarization.
What is Gemini 2.0 Flash?
Gemini 2.0 Flash is the latest iteration in Google’s line of advanced large language models (LLMs). Part of the Gemini family, Gemini 2.0 Flash is designed with a strong emphasis on speed, efficiency, and optimization. The term “Flash” is indicative of its low-latency processing, meaning it is built to handle high-demand applications where rapid responses are essential. It is part of Google’s Vertex AI platform, and while it is still in its experimental phase, it is already gaining traction for enterprise-level applications that require high-volume data processing or real-time analytics.

How Does Gemini 2.0 Flash Work?
Gemini 2.0 Flash is based on cutting-edge transformer architecture, the same type of neural network structure powering most of the latest LLMs. What sets Gemini 2.0 Flash apart is its specialized optimization for speed. The model is engineered to minimize processing delays while handling massive datasets or real-time queries. Unlike other models focused on creating a deeply conversational AI, Gemini 2.0 Flash prioritizes raw computational power and quick decision-making.
Key Features of Gemini 2.0 Flash:
- Speed and Efficiency: Gemini 2.0 Flash is optimized for ultra-low-latency responses, making it ideal for environments that require near-instantaneous outputs, such as financial trading or live-stream analytics.
- High-Volume Processing: It excels in large-scale data processing, handling millions of queries with minimal delay.
- Text and Image Processing: While not as fully multimodal as GPT-4o, Gemini 2.0 Flash can handle text and image inputs, making it effective for tasks like image recognition, text summarization, and data extraction.
- Versatility for Enterprise Solutions: Gemini is designed to integrate into enterprise systems, enabling businesses to extract insights and act on them faster than ever before.
Where Does Gemini 2.0 Flash Excel?
- Real-Time Data Analysis: With its focus on speed, Gemini 2.0 Flash is a top choice for scenarios that require quick, accurate analysis of data in real-time, such as financial markets, traffic monitoring, and fraud detection.
- High-Frequency Tasks: Its ability to process large volumes of information without significant delays makes it perfect for tasks that demand high throughput, like content moderation or automated reports in real-time.
- Low-Latency Applications: Gemini 2.0 Flash shines where latency is a critical factor, such as live interactions or instant decision-making systems.
What is GPT-4o?
GPT-4o is OpenAI’s groundbreaking multimodal language model designed to be a powerful, versatile AI assistant. The “o” stands for “omni,” reflecting its ambition to be an all-encompassing assistant capable of processing and understanding a variety of input types, including text, audio, and images. GPT-4o’s design is centered around creating a seamless, human-like interaction and is part of the GPT-4 family, one of the most advanced LLMs to date.
How Does GPT-4o Work?
Like other models in the GPT family, GPT-4o is based on transformer architecture, leveraging deep neural networks to process vast amounts of data. However, what sets GPT-4o apart is its ability to integrate multiple modalities—such as visual input and audio—into a single cohesive system. This allows GPT-4o to understand and respond to a wide range of user inputs, not just in text but also through images or spoken language. GPT-4o also leverages large-scale unsupervised learning from diverse datasets to enhance its understanding of language, allowing for high-level reasoning, complex problem-solving, and creative generation.
Key Features of GPT-4o:
- Multimodal Processing: GPT-4o can process text, audio, and images simultaneously, making it ideal for tasks that require a mix of inputs.
- Emotional and Contextual Understanding: It can analyze emotions in speech or text and respond accordingly, offering more natural, conversational interactions.
- Complex Reasoning: GPT-4o excels at deep reasoning, problem-solving, and generating creative content, making it suitable for tasks like writing, teaching, and complex decision-making.
- Real-Time Translation and Analysis: The model can translate text or audio in real-time, making it highly effective for cross-lingual communication and content creation.
Where Does GPT-4o Excel?
- Conversational AI: GPT-4o is perfect for chatbots or virtual assistants that require nuanced responses and the ability to interpret a variety of inputs. Its ability to switch seamlessly between text, voice, and visual input makes it highly adaptable to diverse interaction styles.
- Creative Content Generation: Whether it’s generating stories, essays, or creative problem-solving, GPT-4o can handle complex language tasks that require imagination and deep contextual understanding.
- Multimodal Applications: It stands out in applications where text, audio, and visual data need to be processed together, such as interactive storytelling, media analysis, and personalized learning systems.
- Personalized Services: Its deep understanding of context and tone makes GPT-4o an excellent choice for tasks like personalized tutoring or customized customer service.
Comparing Gemini 2.0 and Gpt-4o
1. Multimodal Capabilities
Gemini 2.0 Flash:
While Gemini 2.0 Flash is likely to handle text and images, its multimodal capabilities are not as fully developed as GPT-4o’s. It’s built for rapid processing rather than nuanced interaction across multiple media types. Thus, it excels at quickly extracting insights from text and images but does not offer the same level of integration with audio or emotional context.
Example:
Gemini 2.0 Flash might efficiently analyze a technical diagram or text, providing insights or summaries. However, if you uploaded a picture of a beach sunset and wanted an emotional interpretation, the model may not capture that aspect with the same depth as GPT-4o.

GPT-4o:
One of the standout features of GPT-4o is its true multimodal understanding. This means it can process text, images, and audio seamlessly, often with contextual awareness. For instance, GPT-4o can interpret an image and answer follow-up questions in natural language, or it can engage in a conversation where it adjusts its responses based on emotional tones detected in both the user’s words and voice.
Example:
If you upload the same picture, GPT-4o would not only describe the image but also discuss the associated mood, colors, and even give a poetic interpretation of the scene if asked.

2. Speed and Latency
GPT-4o:
While GPT-4o offers a balanced performance across tasks, it is not explicitly designed for low-latency scenarios. Its focus is on comprehensiveness and versatility, which means it can sometimes lag behind in response time for tasks that require immediate action. GPT-4o aims to provide thoughtful, contextually aware responses, which can sometimes require more processing time compared to a highly optimized model like Gemini.
Gemini 2.0 Flash:
On the other hand, Gemini 2.0 Flash is built with speed in mind. It’s designed to provide quick, near-instantaneous responses, making it ideal for time-sensitive applications such as real-time data processing or rapid decision-making environments. It sacrifices some of the nuanced processing capabilities of GPT-4o in favor of minimized latency.
Example:
If you’re running a real-time auction platform where every millisecond matters, Gemini 2.0 Flash would be a much better choice for ensuring that bids are processed instantly without delays.
3. Reasoning and Complexity
GPT-4o:
When it comes to complex problem-solving and creative content generation, GPT-4o shines. It demonstrates a sophisticated understanding of language nuances, contextual relationships, and even abstract reasoning. GPT-4o can handle complex tasks like writing a research paper, generating creative narratives, or solving multi-step logic puzzles with impressive accuracy.
Example:
Ask GPT-4o to write a creative story that ties in historical facts with futuristic themes, and it will be able to handle the complexity of integrating factual accuracy with imaginative narratives.

Gemini 2.0 Flash:
Gemini 2.0 Flash, while likely capable of reasoning, prioritizes speed over deep complexity. It excels at high-volume content processing and rapid computations, but it may not always offer the same depth of understanding or contextual reasoning that GPT-4o can provide for complex, creative, or nuanced tasks.
Example:
We asked Gemini 2.0 to write the same story, using the same prompt. And while the output ir pretty rich in terms of quality and creativity, we have to point that it doesn’t go further, while GPT 4o wrote a complete story with characters descriptions and chapters.

4. Use Cases
GPT-4o:
Given its multimodal capabilities, creative potential, and nuanced reasoning, GPT-4o is ideal for conversational assistants, real-time translation, personalized tutoring, and applications where a blend of text, audio, and visual analysis is needed. It shines in customer service, content creation, and AI companionship applications.
Gemini 2.0 Flash:
Gemini 2.0 Flash excels in data-heavy applications, real-time analytics, high-frequency trading, or systems requiring rapid responses. It’s well-suited for environments where speed and efficiency are critical, such as real-time monitoring systems or large-scale data processing.
5. API Access and Availability
GPT-4o:
Available through OpenAI’s API, GPT-4o can be integrated into a variety of applications. It provides flexibility and versatility across industries, offering developers the ability to tap into its multimodal capabilities.
Gemini 2.0 Flash:
Gemini 2.0 Flash is available through Google’s Vertex AI platform, currently in an experimental phase. This means it may not yet be as broadly accessible as GPT-4o, but it’s geared toward developers and businesses looking to optimize for speed.
Benchmark of Gemini 2.0 vs GPT-4o
| Benchmark | Description | GPT-4o | Gemini 2.0 Flash (Experimental) |
|---|---|---|---|
| MMLU | Massive Multitask Language Understanding – Tests knowledge across 57 subjects | 88.7% | Not Available |
| MMLU-Pro | A more robust MMLU with harder, reasoning-focused questions | 74.68% | 76.4% |
| MMMU | Massive Multitask Multimodal Understanding – Tests understanding across text, images, audio, and video | 69.1% | 70.7% |
| HellaSwag | A challenging sentence completion benchmark | Not available | Not Available |
| HumanEval | Evaluates code generation and problem-solving capabilities | 90.2% | Not available |
| MATH | Tests mathematical problem-solving abilities | 75.9% | 89.7% |
| GPQA | Tests PhD-level knowledge in chemistry, biology, and physics | 53.6% | 62.1% |
| Diamond IFEval | Tests model’s ability to accurately follow explicit formatting instructions | Not available | Not available |
When evaluating the performance of GPT-4o and Gemini 2.0 Flash, several key benchmarks provide insight into their respective capabilities.
1. MMLU (Massive Multitask Language Understanding):
This benchmark assesses a model’s proficiency across 57 diverse subjects, including mathematics, history, and law.
GPT-4o: Achieved an 88.7% accuracy rate in a 5-shot setting.
Gemini 2.0 Flash: While specific performance metrics for Gemini 2.0 Flash on MMLU are not detailed in the available sources, it is noted that Gemini 2.0 Flash outperforms GPT-4o on several benchmarks.
2. MMLU-Pro:
An advanced version of MMLU, MMLU-Pro presents more challenging, reasoning-focused questions. See the complete evaluation here.
GPT-4o: Scored 74.68%.
Gemini 2.0 Flash: Achieved a score of 76.4%, indicating a slight edge over GPT-4o in this domain.
3. MMMU (Massive Multitask Multimodal Understanding):
This benchmark evaluates a model’s ability to process and understand text, images, audio, and video inputs.
GPT-4o: Scored 69.1%.
Gemini 2.0 Flash: Achieved a score of 70.7%, surpassing GPT-4o in multimodal understanding.
4. GPQA (Generalized Question Answering):
This benchmark tests a model’s capacity to answer a wide range of questions.
GPT-4o: Achieved a score of 88.7%.
Gemini 2.0 Flash: Achieved a score of 90.2%, indicating a slight advantage over GPT-4o in this area.
5. MATH:
This benchmark assesses a model’s mathematical reasoning abilities.
GPT-4o: Achieved a score of 90.2% in a 0-shot setting.
Gemini 2.0 Flash: Specific performance metrics for Gemini 2.0 Flash on the MATH benchmark are not detailed in the available sources.
6. HumanEval:
This benchmark evaluates a model’s code generation and problem-solving capabilities.
GPT-4o: Achieved a score of 90.2% in a 0-shot setting.
Gemini 2.0 Flash: Specific performance metrics for Gemini 2.0 Flash on the HumanEval benchmark are not detailed in the available sources.
Real Use Case Testing of Gemini 2.0 vs GPT 4o
In a detailed practical analysis conducted by Nitika Sharma, both models were evaluated across distinct use cases. The results demonstrated clear performance variations, highlighting the strengths and limitations of each model in different scenarios. Key insights from the analysis revealed how model selection impacts efficiency, accuracy, and overall applicability, providing valuable guidance for optimizing machine learning workflows.
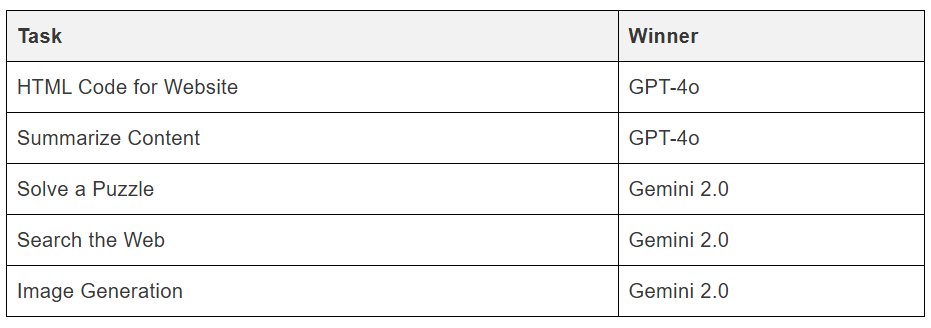
Early user feedback indicates that GPT-4o offers a more fluid and human-like conversational experience, making it ideal for applications requiring natural, conversational interactions. In contrast, Gemini 2.0 Flash is noted for its speed and efficiency, excelling in tasks where quick response times are critical. For instance, users have observed that Gemini 2.0 Flash outperforms GPT-4o on several benchmarks, despite being a smaller model.
The power of GPT-4o technology with neuroflash!
Ready to take your content creation to the next level? With neuroflash, you get a powerful and intuitive platform that harnesses the latest AI technology. Designed specifically for your needs, it streamlines your workflow, enhances creativity, and helps you produce high-quality content effortlessly.
With neuroflash’s advanced AI-powered platform, you can effortlessly create, refine, and optimize high-quality content that aligns perfectly with your brand voice. Upload your key information to ensure your messaging stays consistent, engaging, and impactful across all your content. Whether it’s blog posts, social media updates, or marketing copy, neuroflash helps you save time and boost creativity.
Sign up for free today and discover how neuroflash can transform your content creation process!
Conclusion
Both GPT-4o and Gemini 2.0 Flash offer distinct advantages:
GPT-4o provides a more human-like conversational experience, making it suitable for applications requiring nuanced understanding and creative content generation.
Gemini 2.0 Flash excels in speed and efficiency, making it ideal for tasks requiring rapid responses and high computational efficiency.
Given GPT-4o’s superior performance in the tests, it is the preferred choice for applications demanding high text quality and precise language matching. Ongoing testing and quality control are essential to monitor and maintain its performance.














