





The development of multilingual AI has reached a new milestone with Teuken 7B, the latest language model from the OpenGPT-X initiative. Designed to address Europe’s linguistic diversity, Teuken 7B stands out as an innovative solution tailored for the unique challenges of multilingual communication and AI deployment across the continent. In this article, we’ll explore its key features, including pre-training data, multilingual tokenization, model architecture, training process, access methods, and limitations.
Introducing Teuken 7B: A Multilingual AI for Europe
Teuken 7B is a large language model (LLM) built specifically to handle Europe’s 24 official languages. Unlike most AI models that are heavily focused on English, Teuken 7B ensures robust support for a wide array of languages, from widely spoken ones like German and French to less commonly used languages such as Finnish and Maltese. By prioritizing linguistic inclusivity and multilingual efficiency, it positions itself as a game-changer for governments, businesses, and researchers across Europe.
Key Features
European-Centric Training: Unlike many existing language models that predominantly focus on English or Chinese, Teuken 7B is tailored to Europe’s linguistic diversity, ensuring robust performance across multiple European languages.
Custom Multilingual Tokenizer: To enhance efficiency, a specialized tokenizer was developed for the 24 EU languages. This approach reduces fragmentation in non-English texts, leading to more efficient training and inference processes.
Open Source Collaboration: The model is open source, encouraging collaboration among researchers, developers, and AI enthusiasts to further advance Europe’s AI landscape.
Instruction-Tuned: Teuken 7B has undergone instruction tuning, enhancing its ability to follow human instructions effectively across various tasks and languages.
The development of Teuken 7B underscores Europe’s commitment to advancing AI technologies that reflect its cultural and linguistic diversity, promoting inclusivity and representation in the digital realm.
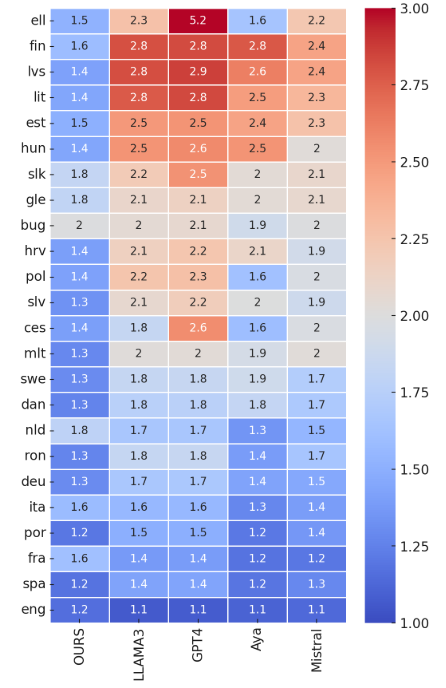
Teuken 7B : Pre-Training Data
A cornerstone of Teuken 7B’s capabilities is its high-quality pre-training data. Approximately 60% of the dataset comprises non-English content, ensuring the model excels in European languages. The pre-training pipeline employed rigorous quality control, filtering out over 90% of the initial dataset to maintain relevance and reliability. This meticulous approach ensures the model’s responses are accurate, contextually appropriate, and linguistically nuanced, making it especially valuable for applications like translation, sentiment analysis, and content generation.

Multilingual Tokenization and Efficiency
One of Teuken 7B’s standout innovations is its custom multilingual tokenizer. Tokenization, the process of breaking text into smaller units, is critical for language models. Generic tokenizers often struggle with European languages, especially those with compound words (e.g., German’s Lebensmittelgeschäft) or agglutinative structures (e.g., Finnish’s taloissammekaan).
Teuken 7B’s tokenizer minimizes fragmentation, preserving semantic meaning and improving model efficiency. This optimization reduces computational overhead while enhancing the model’s ability to understand and generate text in diverse languages.
Model Architecture
Teuken 7B features a carefully designed architecture with 7 billion parameters. This size strikes a balance between computational efficiency and performance, allowing it to handle complex linguistic tasks while remaining accessible for research and application. The model leverages state-of-the-art transformer-based techniques to deliver high-quality outputs across a variety of tasks, including text summarization, question answering, and translation.
Training Process of Teuken 7B
Teuken 7B was trained using the JUWELS supercomputer at Forschungszentrum Jülich, one of Europe’s leading computational facilities. This training leveraged advanced techniques to maximize efficiency and scalability. The collaboration between OpenGPT-X and European computational infrastructure underscores a commitment to creating AI solutions that address regional needs and challenges effectively.
The Custom Multilingual Tokenizer
The custom multilingual tokenizer in Teuken 7B is a critical innovation that addresses challenges in processing text from diverse languages. Here’s why it matters:
Minimized Text Fragmentation: A tokenizer breaks down text into smaller units called tokens. Generic tokenizers, often designed for English, can fragment words in other languages inappropriately. For example:
- In German, compound words (e.g., Lebensmittelgeschäft) are common. A generic tokenizer might split it into unrelated parts, leading to a loss of context.
- In Finnish, agglutinative words like taloissammekaan (meaning “not even in our houses”) can be misunderstood by generic tokenizers. The custom tokenizer for Teuken 7B minimizes such fragmentation, ensuring that tokens remain semantically meaningful.
Optimized for 24 EU Languages: By tailoring the tokenizer to handle the nuances of European languages, Teuken 7B can process texts more efficiently, improving its accuracy in tasks like translation, sentiment analysis, and summarization.
Efficiency Gains: A more effective tokenizer reduces the computational cost of training and inference. This is especially valuable in multilingual settings, where handling diverse scripts and grammatical structures can otherwise be resource-intensive.
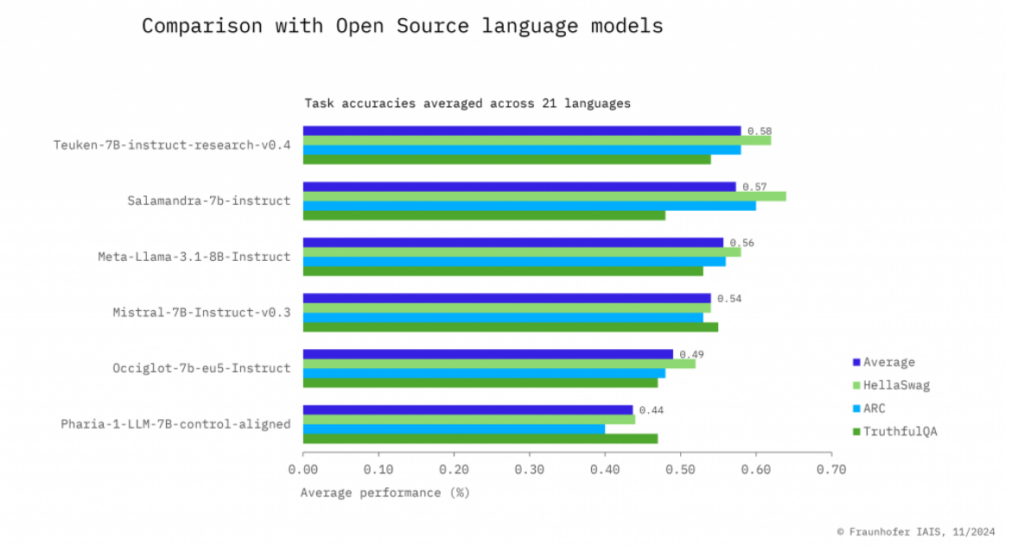
How is Teuken 7B different from other language models?
Teuken 7B stands out because of its multilingual focus and European-centric design, which set it apart in the following ways:
Prioritization of Non-English Languages: Unlike most large language models (LLMs) that allocate a significant majority of their training data to English (e.g., GPT-3, BERT), Teuken 7B ensures over 50% of its training data is in non-English European languages. This improves its performance in languages like German, French, Italian, and even less widely spoken ones such as Finnish or Maltese.
Custom-Built for European Languages: It uses datasets curated specifically from European sources, capturing the unique grammar, syntax, and idiomatic expressions of these languages. This is critical for tasks like translation or localized content generation.
Open Source and Ethical AI: Many other advanced LLMs are proprietary, meaning they are not openly accessible. Teuken 7B is open source, promoting transparency and collaboration, which aligns with Europe’s ethical AI initiatives.
Efficiency Through Instruction Tuning: Teuken 7B is designed with user instructions in mind, making it adept at understanding and responding to tasks across languages. Its instruction-tuned training sets it apart from older models that often required fine-tuning for each new task.
What is Instruction Tuning?
Typically, LLMs are trained on large amounts of text to predict the next word in a sequence, which helps them learn language structure. Instruction tuning goes a step further by training the model to respond specifically to structured instructions given by users.
For example, instead of simply completing a sentence, an instruction-tuned model can respond to prompts like: “Summarize this article in French” or “Translate this text into German.”
Why Does It Matter for Teuken 7B?
- Multilingual Complexity: Handling structured instructions in multiple languages requires nuanced understanding. Instruction tuning ensures Teuken 7B performs well not just in understanding a single language but also in switching between languages as per user requests.
- Task Adaptability: Teuken 7B can handle diverse tasks (translation, summarization, answering questions, etc.) without needing extensive re-training for each task. This flexibility reduces deployment time and costs for users.
- Comparison to Non-Tuned Models: Models without instruction tuning often require manual intervention or additional task-specific fine-tuning to achieve similar results. Teuken 7B’s instruction tuning makes it efficient and ready to use out of the box for a variety of applications.
How to Access Teuken 7B
As an open-source model, Teuken 7B is freely accessible to researchers, developers, and organizations. It is hosted on platforms like Hugging Face, making it easy to integrate into various applications. By prioritizing openness and collaboration, Teuken 7B aligns with Europe’s ethical AI initiatives and fosters innovation in multilingual AI development.
For direct access, visit the Hugging Face repository for Teuken 7B, or book a Demo at Fraunhofer IAIS
Teuken 7B Limitations:
While Teuken 7B is a significant advancement, it is not without limitations:
Language Representation: The model’s performance may vary across languages, especially for those with less representation in the training dataset.
Bias in Training Data: As with many AI models, biases present in the training data can influence outputs. Efforts are ongoing to mitigate these issues and improve fairness.
Computational Requirements: Although optimized, the model still requires significant computational resources for fine-tuning and large-scale deployments.
These challenges highlight areas for future research and development to enhance Teuken 7B’s capabilities further.
Use the best GPT's alternative for multilingual outcomes: neuroflash!
neuroflash leverages the power of GPT-3.5 and GPT-4o to generate high-quality content in multiple languages, thus breaking down language barriers and opening up new possibilities for communication and engagement. Currently, neuroflash is capable of producing texts in German, English, Spanish, Catalan, French, Polish, Italian, Dutch, Croatian, Hungarian, Portuguese, Czech, Swedish, Turkish, and Chinese. This extensive linguistic capability ensures that your content can reach a broad and diverse audience, catering to various regions and cultural nuances.

Imagine being able to seamlessly produce engaging, relevant, and contextually appropriate content for such a wide array of languages. Whether it’s for marketing copy, academic articles, customer service responses, or creative writing, neuroflash stands out as the best AI content tool with the power of GPT-4o technology. The ability to generate quality content across different languages not only enhances communication but also significantly boosts inclusivity and accessibility.
Conclusion
Teuken 7B exemplifies a dedicated effort to create a multilingual AI model that reflects and serves Europe’s rich linguistic diversity. Its development showcases the potential of collaborative, open-source AI initiatives in addressing regional needs. As Teuken 7B continues to evolve, it holds promise for facilitating more inclusive and effective AI applications across Europe.














