





Pixtral Large is the latest innovation in multimodal language models, developed by Mistral AI to push the boundaries of artificial intelligence in interpreting and processing textual and visual data simultaneously. This guide dives deep into what Pixtral Large is, how it works, its structure, applications, and how you can start using it today.

What is Pixtral Large?
Pixtral Large is a 124-billion-parameter multimodal language model that combines a robust text decoder with an advanced vision encoder. This cutting-edge model bridges the gap between textual and visual understanding, making it an ideal tool for handling complex data inputs that include images, charts, documents, and natural text.
Building on the foundation of Mistral Large 2, Pixtral Large sets itself apart with an impressive ability to process extensive context windows and deliver high accuracy across various benchmarks.
How Pixtral Large Works
Pixtral Large integrates a 123-billion-parameter transformer-based text decoder with a 1-billion-parameter vision encoder. These components work in tandem to:
Text Decoder: Process massive amounts of text data, offering state-of-the-art performance in natural language processing tasks.
Vision Encoder: Analyze a wide range of visual inputs, preserving critical details by using aspect ratio-preserving preprocessing techniques.
The synergy between these two modules allows Pixtral Large to seamlessly interpret both text and visual data, enabling it to excel in multimodal tasks such as document analysis, visual question answering, and optical character recognition (OCR).
Key Features of Pixtral Large
1. Comprehensive Multimodal Understanding
Pixtral Large interprets natural images, charts, documents, and other forms of visual input while maintaining a high level of understanding of text-based data.
2. Expansive Context Window
With a context window of 128,000 tokens, the model can process substantial data inputs, equivalent to a 300-page book or up to 30 high-resolution images, without requiring segmentation.
3. Performance Benchmarks
Pixtral Large has achieved state-of-the-art results in several multimodal benchmarks, including:
MathVista for mathematical reasoning tasks.
DocVQA for document-based question answering.
VQAv2 for visual question answering.
Performance
Pixtral Large has been benchmarked against leading models using a standardized multimodal evaluation framework. On MathVista, a benchmark focused on complex mathematical reasoning over visual data, the model achieves a score of 69.4%, surpassing all competing models. For reasoning tasks involving intricate charts and documents, Pixtral Large excels in both ChartQA and DocVQA, outperforming GPT-4o and Gemini-1.5 Pro.
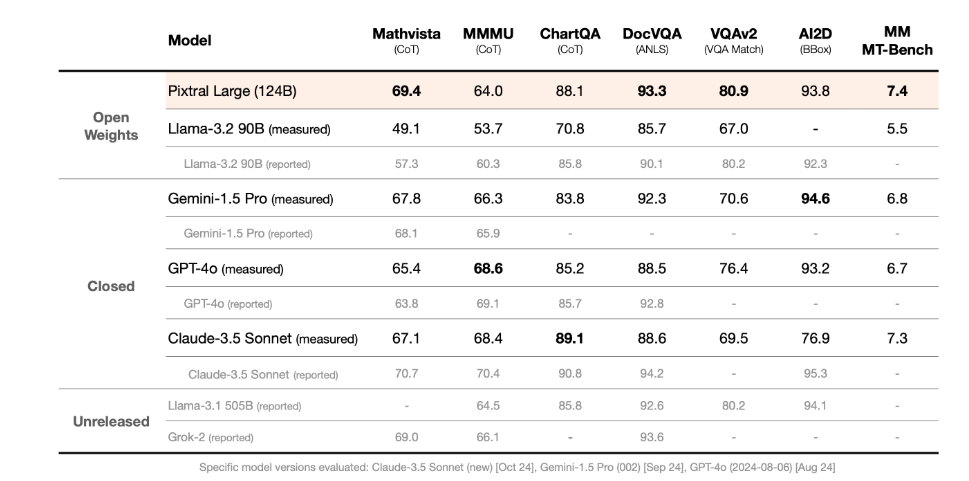
Additionally, Pixtral Large showcases outstanding performance on MM-MT-Bench, surpassing Claude-3.5 Sonnet (new), Gemini-1.5 Pro, and GPT-4o (latest). MM-MT-Bench serves as an open-source, judge-based evaluation tailored to real-world applications of multimodal LLMs (refer to the Pixtral 12B technical report for further details).
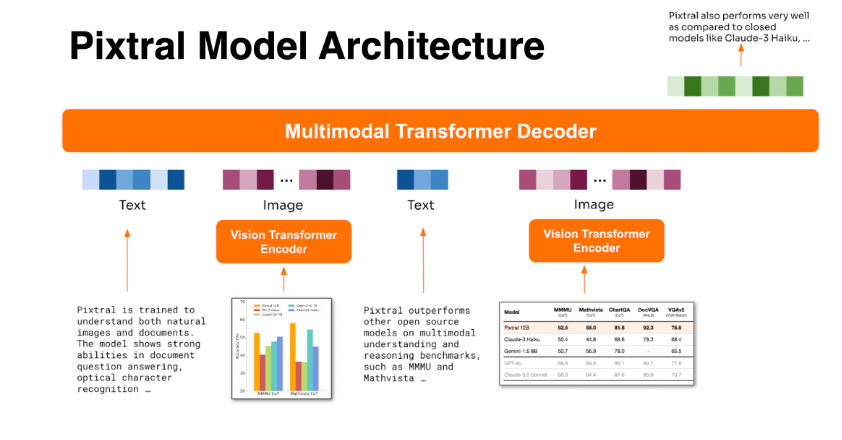
Architecture:
Multimodal Decoder
The decoder in Pixtral Large is built upon the architecture of Mistral Large 2. It employs a transformer-based framework designed for advanced reasoning across both text and visual modalities. Capable of handling extended contexts of up to 128K tokens, the decoder excels at integrating substantial amounts of textual and visual information within a single inference process.
Vision Encoder
Parameters:
config (PixtralVisionConfig): A configuration class containing all parameters for the vision encoder. Initializing with a configuration file sets up the model’s structure but does not load its weights. To load the model weights, use the from_pretrained() method.
The Pixtral vision encoder provides raw hidden states without any specialized head on top. It inherits from the PreTrainedModel class, granting access to generic methods common across all models in the library (e.g., downloading or saving models, resizing input embeddings, pruning heads, etc.).
This model is also a subclass of PyTorch’s torch.nn.Module. It can be used like any standard PyTorch module, and the PyTorch documentation can be referenced for general usage and behavior.
Use Cases of Pixtral Large
Pixtral Large’s capabilities open doors to a wide range of applications:
Document Analysis:
Pixtral Large is optimized for document analysis, including PDFs, invoices, and scanned materials. It supports tasks such as:
- Optical Character Recognition (OCR): Extracts text from multilingual documents.
- Content Summarization: Generates concise summaries of extensive documents containing embedded images.
- Semantic Search: Enables retrieval of relevant information from datasets combining text and visual content.
Visual Question Answering:
Pixtral Large is capable of interpreting and reasoning about visual data, including:
- Charts and Graphs: Detects trends and identifies anomalies in visualized datasets.
- Training Loss Curves: Evaluates the performance of machine learning models over time, helping to identify issues like instability or overfitting.
- Multilingual OCR:
The model supports multi-turn conversational systems that combine text and images. Use cases include:
- Customer Support: Resolves user queries by analyzing screenshots and associated text.
- Knowledge Exploration: Provides detailed explanations of documents, diagrams, or charts during interactive sessions.
Image-to-Code Conversion:
Pixtral Large transforms images of hand-drawn or designed interfaces into executable HTML or code snippets. This feature connects design and development workflows, enhancing efficiency in prototyping.
Accessing Pixtral Large
Licensing:
Pixtral Large is available under two licensing models:
Mistral Research License (MRL): For research and educational use.
Mistral Commercial License: For commercial applications.
Availability:
Pixtral Large is offered under two licenses:
- Mistral Research License: For academic research and educational purposes.
- Mistral Commercial License: For experimentation, testing, and production use in commercial environments.
Access Options:
- Chatbot: Mistral’s chatbot for experimenting with the model. Click here to access it.
- API: Available as pixtral-large-latest for integration into applications. Click here to access the API.
- HuggingFace Repository: Open weights for self-hosting and further fine-tuning. Click here to download it.
Conclusion:
Pixtral Large represents a significant milestone in the field of AI, offering robust multimodal capabilities that unlock new possibilities for understanding and processing complex data. Whether you’re a researcher, developer, or business leader, Pixtral Large provides an unparalleled tool for advancing your projects in document analysis, visual intelligence, and more. With its expansive context window, high performance, and ease of access, Pixtral Large is poised to become a cornerstone in AI-driven innovation.














