





Introduction to GPT-3
GPT-3 (Generative Pre-trained Transformer 3) is an advanced language model developed by OpenAI. Built on the Transformer architecture, GPT-3 is the third iteration of the GPT series and was released in 2020. The term “Generative” indicates that these models are capable of generating text, and “Pre-trained” suggests that they are trained on vast amounts of data before being fine-tuned for specific tasks. With its impressive capability to understand and generate human-like text, GPT-3 has emerged as one of the most powerful artificial intelligence language generators to date.
GPT-3 boasts an extensive neural network model with a staggering 175 billion parameters, a substantial increase compared to its predecessor, GPT-2. The vast parameter space allows the model to discern complex patterns in extensive datasets and better grasp the underlying structures of texts.
Technical Specifications of GPT-3
Parameter
Architecture
Parameters
Pre-training Data
Fine-tuning Data
Maximum Sequence Length
Inference Speed
Released Year
Value
Transformer
175 billion
Diverse text corpora
Customizable for tasks
2048 tokens
Varies by hardware
2020
Development of GPT-3
GPT refers to a family of artificial intelligence language models developed by OpenAI. The Transformer architecture, introduced in the paper “Attention Is All You Need” by Vaswani et al. in 2017, forms the basis of GPT models. Transformers use a self-attention mechanism to process input data in parallel, making them highly efficient for tasks involving sequential data, such as natural language processing.
The GPT technology have evolved over time, and as of the last update in March 2023, there are four major iterations: GPT, GPT-2, GPT-3 and GPT-4.
- GPT: The original GPT model, released in 2018, was a breakthrough in natural language processing. It consisted of 117 million parameters and was trained on a wide range of internet text data.
- GPT-2: Released in 2019, GPT-2 was a larger and more powerful version of the original GPT. It had 1.5 billion parameters, making it more capable of generating coherent and contextually relevant text. Due to concerns about potential misuse for generating fake news, OpenAI initially limited access to the full model, but later made it available to the public.
- GPT-3: Introduced in 2020, GPT-3 took the capabilities of its predecessors to a whole new level. With a staggering 175 billion parameters, it became one of the largest language models ever created. GPT-3 demonstrated unprecedented language understanding, generating highly realistic and contextually appropriate responses to diverse prompts.
- GPT-4: GPT-4 is the latest language model developed by OpenAI, released on March 14, 2023. As the fourth version in the GPT series, it is a large multimodal language model capable of comprehending both text and images. GPT-4 is trained using “pre-training,” predicting the next word in sentences from vast and diverse data sources. Additionally, it utilizes reinforcement learning, learning from human and AI feedback to align its responses with human expectations and guidelines. While available to the public through ChatGPT Plus, full access to GPT-4 via OpenAI’s API is currently limited and offered through a waitlist. Although it represents an improvement over GPT-3.5 in the ChatGPT application, GPT-4 still faces some similar issues, and specific technical details about its model size remain undisclosed.
These GPT models are examples of unsupervised learning, where the models learn from vast amounts of text data without explicit labels or annotations. During the pre-training phase, the models develop an understanding of language and context, and during the fine-tuning phase, they are adapted for specific tasks like translation, summarization, question-answering, and more.
How GPT-3 works
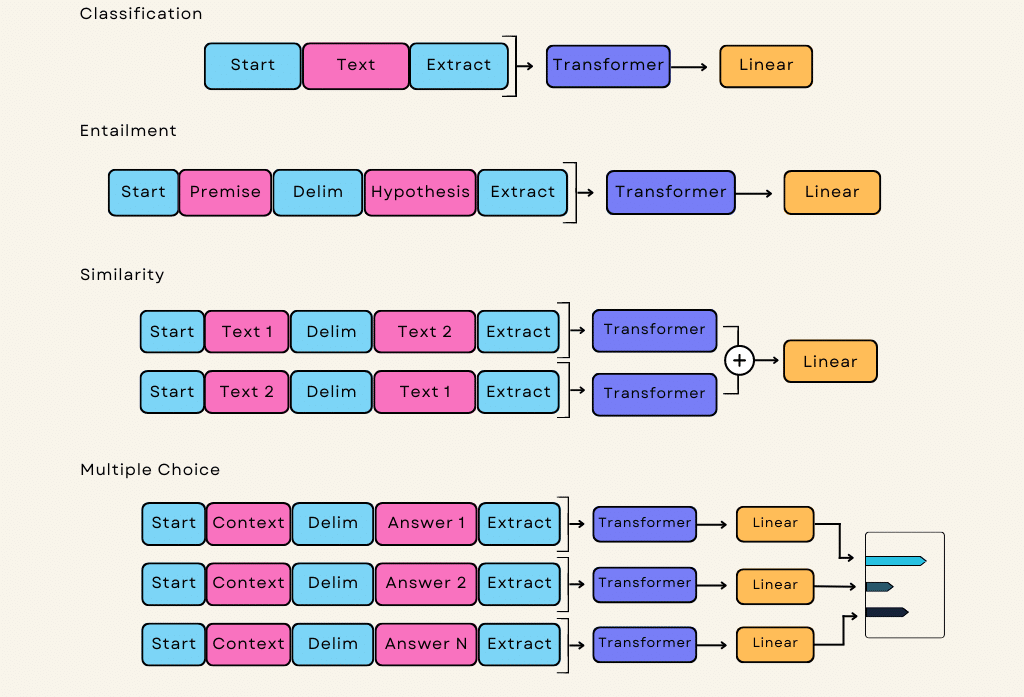
Leveraging the Transformer architecture, GPT-3 excels at recognizing long-range dependencies between words and phrases within a text. This enhanced understanding of context enables the model to generate semantically coherent responses. Furthermore, the artificial intelligence adopts an “unsupervised learning” approach, eliminating the need for task-specific pre-training. Here is how all of it works together in detail:
- Architecture: GPT-3 is based on the Transformer architecture, which was introduced in the paper “Attention Is All You Need” by Vaswani et al. in 2017. The Transformer architecture uses a novel self-attention mechanism that allows the model to process input data in parallel, making it highly efficient for handling sequences, such as natural language.
- Pre-training: GPT-3 is “pre-trained” on a massive dataset comprising diverse text from various sources, such as books, articles, and websites. During pre-training, the model learns to predict the next word in a sequence given the preceding words. This process exposes the model to an extensive understanding of grammar, context, and relationships between words.
- Parameters: GPT-3 is a massive model with 175 billion parameters. Parameters are the learnable weights that the model uses to make predictions during training and inference. The vast number of parameters allows GPT-3 to capture complex patterns and nuances in the data.
- Fine-tuning: After pre-training on the large corpus of text, GPT-3 is fine-tuned for specific tasks. Fine-tuning involves training the model on more specialized datasets for tasks like translation, summarization, question-answering, and more. This process tailors the model’s abilities to be more relevant and accurate for specific applications.
- Zero-Shot and Few-Shot Learning: One remarkable aspect of GPT-3 is its ability to perform “zero-shot” and “few-shot” learning. Zero-shot learning allows the model to generate plausible responses for tasks it was not explicitly fine-tuned on, based on a description of the task. Few-shot learning allows the model to adapt to new tasks with only a few examples or demonstrations, without extensive retraining.
- Text Generation and Completions: Given a prompt or context, GPT-3 can generate coherent and contextually appropriate text, whether it’s completing a sentence, writing paragraphs, or even composing creative stories or poems.
- Natural Language Understanding: GPT-3 can understand and process natural language, making it proficient in answering questions, providing explanations, and engaging in conversations with users.
- Limitations: While GPT-3 is a highly advanced language model, it is not without limitations. It can sometimes generate responses that may sound plausible but lack factual accuracy or exhibit biases present in the training data. Additionally, controlling the output to ensure it adheres to specific requirements can be challenging.
Applications of GPT-3
GPT-3 finds application across various domains, making it a versatile language model:

- Programming: GPT-3 can generate code snippets and assist in understanding and improving code in multiple programming languages.
- Creative Applications: GPT-3 can generate creative texts such as poems, stories, and song lyrics, inspiring artists in their creative endeavors.
- Research and Analysis: Its ability to process vast amounts of text data aids in research and analysis of text corpora and literature.
- Language Generation: GPT-3 can produce high-quality text ranging from simple sentences to entire articles and narratives.
- Chatbots and Virtual Assistants: Its capabilities serve as the foundation for developing advanced chatbots and virtual assistants that facilitate human-like interactions.
- Automating Text Tasks: The model can automate repetitive tasks, including text summarization, translation, and email responses.
Using GPT-3 with the OpenAI Token System
The token system is a fundamental concept in GPT-3 and other language models based on the Transformer architecture. Tokens are the individual units of text that the model processes. In the context of natural language, tokens can be as short as one character or as long as one word.
In GPT-3, the input text is broken down into tokens before being fed into the model for processing. Likewise, the model’s output is produced in the form of tokens, which are then converted back into readable text.

Here are some key points to understand about the token system behind GPT-3:
- Tokenization: Tokenization is the process of breaking down a continuous text into individual tokens. For example, the sentence “Hello, how are you?” might be tokenized into [“Hello”, “,”, “how”, “are”, “you”, “?”].
- Token Size: The size of tokens in GPT-3 can vary, but it typically uses a subword tokenization method. Instead of representing each word as a single token, GPT-3 may split words into smaller units, called subwords. For example, the word “unbelievable” might be tokenized into [“un”, “##believable”]. This subword tokenization allows the model to handle rare words and morphological variations effectively.
- Token Limitation: GPT-3 has a maximum token limit, which means it can only process a fixed number of tokens in a single API call. As of my last update, the maximum token limit was 4096 tokens for GPT-3.
- Token Count in Cost: Both input and output tokens count towards the cost when using GPT-3 through the OpenAI API. This means you pay based on the total number of tokens used in your API request and the response generated by the model.
- Token Constraints: To ensure that a given text input fits within the model’s token limit, you might need to truncate or omit parts of the text, depending on its length.
- Token Economization: Since the cost of using GPT-3 is based on the number of tokens, developers often try to optimize their API calls to minimize token usage while still achieving the desired outcomes.
Understanding the token system is essential for using GPT-3 effectively, as it influences not only the processing capability of the model but also the cost associated with its usage. Developers need to be mindful of token usage and tailor their text inputs to fit within the token limits to make the most of GPT-3’s capabilities efficiently.
Challenges and Ethical Considerations of GPT-3
Despite GPT-3’s impressive achievements, it faces challenges and ethical concerns typical of advanced artificial intelligence technology:
- Bias and Fairness: GPT-3 is susceptible to bias, as it learns from large datasets that may not be perfectly balanced, leading to unfair or discriminatory responses.
- Misuse: The technology can be misused for fraudulent or manipulative purposes, such as spreading misinformation or generating fake content.
- Control over Outputs: It can be challenging to control GPT-3’s output, leading to unwanted or inappropriate responses.
- Safety and Security: GPT-3, being a powerful artificial intelligence technology, has the potential to generate harmful content, such as hate speech, harassment, or violent language. Ensuring safety measures to prevent the model from generating harmful outputs is a significant concern.
- Overfitting and Memorization: GPT-3 may sometimes memorize specific data patterns during pre-training, leading to overfitting on certain datasets. This can result in the model providing accurate-sounding but false or unreliable information.
- Explainability and Interpretability: GPT-3’s decision-making process is often considered a “black box” due to its complex neural network architecture. This lack of transparency can raise concerns regarding the model’s decision-making and the potential for biased or unexplainable responses.
- Environmental Impact: Training large language models like GPT-3 requires substantial computational power and energy consumption. The environmental impact of training and running such models at scale needs to be considered.
- Copyright and Intellectual Property: The data used to pre-train GPT-3 often includes copyrighted content from various sources. There can be legal and ethical implications concerning the use of copyrighted material in the training process.
- Inclusivity and Accessibility: Language models like GPT-3 may not fully cater to the needs of users from diverse linguistic backgrounds or individuals with disabilities. Ensuring inclusivity and accessibility is vital when deploying AI models for broader use.
- Unintended Consequences: The deployment of GPT-3 and similar AI technologies can have unintended consequences on society, including economic disruptions, changes in employment patterns, and societal dependencies on AI for decision-making.
- Dependency on AI: As AI technologies like GPT-3 become more prevalent, there is a risk of over-reliance on them, leading to potential loss of human skills and critical thinking abilities.
- Data Privacy and Ownership: Utilizing GPT-3 may involve sharing sensitive user data with the AI provider, raising concerns about data privacy, ownership, and the potential for data exploitation.
- Regulatory and Legal Challenges: The deployment of powerful AI models like GPT-3 may raise regulatory and legal challenges related to liability, accountability, and compliance with existing laws and regulations.
Addressing these challenges and ethical concerns is crucial to ensure responsible and beneficial use of GPT-3 and other advanced AI technologies, fostering trust and transparency in AI applications.
Related Links
Please note that the data in this article is subject to change as newer versions or improvements to GPT-3 may be released in the future


