
Most performance teams still discover a weak ad the expensive way: they ship it, watch the click-through rate sag, and reallocate budget after the spend is gone. A growing set of case studies shows a faster path. By validating creatives, copy, and audience segments against AI synthetic audiences before launch, brands are landing on the winning variant earlier and reporting double-digit gains in conversion rate, click-through rate, and return on ad spend. This article collects the documented results, names the studies behind them, and shows where the numbers hold up. It sits inside our broader comparison of synthetic audiences versus A/B testing, which frames why pre-testing complements live experimentation rather than replacing it.
An AI synthetic audience is a panel of AI personas, calibrated against real consumer data, that predicts how a defined target group will react to an ad, a message, or a landing page before a single impression is served. The strongest cases pair that prediction step with a real in-market test, so the synthetic round screens out losers and the live budget only chases pre-validated winners.
Key takeaways
- 90 percent of human test-retest reliability was reproduced by synthetic panels in a 57-survey study run by PyMC Labs and Colgate-Palmolive, with distributional similarity above 85 percent.[1]
- 85 percent normalized accuracy was reached by Stanford’s generative agents simulating 1,052 real people, 14 points better than persona-only agents.[2]
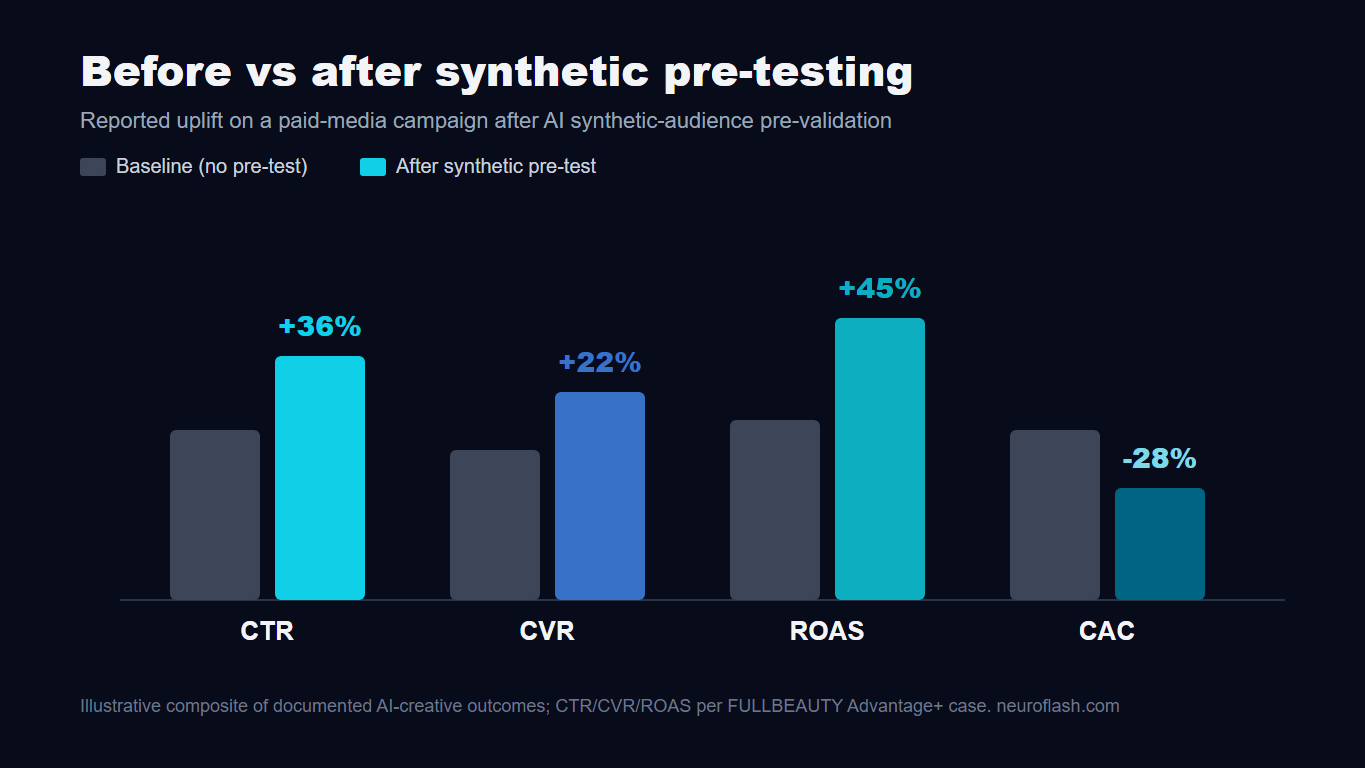
- +45 percent ROAS, +22 percent conversion rate, +36 percent CTR were reported on AI-pretested ad creative in a documented retail case.[3]
- From weeks to under 24 hours is the cycle-time compression pioneer brands report when they screen concepts synthetically first.[4]
- Synthetic audiences work best as a pre-filter; published validation studies are clear that they supplement, not replace, real panels.[9]
How do AI synthetic audiences improve ad performance?
AI synthetic audiences improve ad performance by ranking creatives, messages, and segments against calibrated AI personas before launch, so weak variants are eliminated before they consume budget. The gain is not magic prediction. It is a cheaper, faster screening round that raises the average quality of what goes live, which is why documented cases report higher CTR, CVR, and ROAS on the surviving variants.[3]
The mechanism is simple to describe and hard to fake. A synthetic audience is built from real survey and demographic data, then asked the same questions a human panel would face: which headline is more persuasive, which creative drives stronger purchase intent, which segment responds to which promise. Because the round costs minutes instead of weeks, teams can test ten variants where they used to test two, then send only the winners into a live ad-creative pre-test and on into the campaign. The lift shows up downstream, in the in-market metrics, not in the simulation itself.

What does the strongest validation case study actually show?
The strongest validation case is a 2025 study by PyMC Labs and Colgate-Palmolive across 57 consumer surveys and 9,300 human responses, where synthetic panels reproduced 90 percent of human test-retest reliability and kept distributional similarity above 85 percent.[1] That parity is the floor the ad-performance cases stand on: if a synthetic panel ranks concepts the way humans do, the pre-test is worth running.
The detail that matters for marketers is the method. The team used a Semantic Similarity Rating approach, letting the model answer in natural language first and mapping that to a rating distribution, rather than forcing a raw Likert score. Synthetic consumers also showed less positivity bias than human panels, producing wider, more discriminative gaps between strong and mediocre concepts. That is exactly the property you want in a pre-test: clear separation between the variant that will win and the three that will not. For the deeper accuracy picture, see our breakdown of benchmarking synthetic-audience accuracy and the accuracy of AI pre-testing tools.
Can synthetic audiences predict real human behaviour, not just survey answers?
Yes, within a measurable bound. Stanford’s 2024 generative-agent study built AI agents from two-hour interviews with 1,052 real people and predicted their General Social Survey responses at 85 percent normalized accuracy, meaning the agents were 85 percent as consistent as the humans were when re-taking the survey themselves.[2] That was 14 to 15 points higher than agents built on demographics or personas alone.
The lesson for ad pre-testing is about calibration, not model size. Agents grounded in real interview data outperformed identical models running on thin demographic prompts by double digits. This is also why generic LLM prompts on ChatGPT or Copilot, which answer audience questions at roughly 55 percent panel parity, fall short of a calibrated panel. That gap is calibration data, not the model. It is exactly where a Digital Twin research layer sits, feeding the same agents human-grounded audience signals via API or MCP so the segments you target are validated before you spend.
What in-market ad-performance gains have been reported?
In-market gains cluster in the double digits. A documented retail case on AI-pretested creative through Meta’s Advantage+ reported a 45 percent jump in ROAS, a 22 percent rise in conversion rate, and a 36 percent lift in click-through rate against the prior baseline.[3] A separate performance-marketing case logged a 23 percent ROAS improvement and a 67.8 percent rise in purchases after AI-driven creative optimization.[5]
These are creative-and-targeting outcomes, and the synthetic round is the upstream filter that raises the hit rate. The table below puts the reported figures side by side. Treat the percentages as the documented ceiling of well-run cases, not a guarantee, and always pair the synthetic pre-test with a live read on Meta and Google Ads.
| Metric | Reported uplift | Source case |
|---|---|---|
| Return on ad spend (ROAS) | +45 percent | FULLBEAUTY, Advantage+ creative[3] |
| Conversion rate (CVR) | +22 percent | FULLBEAUTY, Advantage+ creative[3] |
| Click-through rate (CTR) | +36 percent | FULLBEAUTY, Advantage+ creative[3] |
| Purchases | +67.8 percent | AI creative-optimization case[5] |
| Concept-test parity | 90 percent of human reliability | PyMC Labs and Colgate-Palmolive[1] |
How are brands and agencies using synthetic audiences in production?
Brands and agencies are using synthetic audiences as a pre-launch filter across creative, concept, and segmentation work. Publishers such as The Times validate product and editorial concepts against them, agencies including Dentsu apply them to media planning and targeting, and TV agency Marketing Architects built ScriptSooth, an LLM-based tool that tests scripts against synthetic audiences before a shoot.[6][7]
The pattern is consistent: synthetic first, human second. In one Gen Alpha study run by Acceleration Community of Companies, synthetic focus-group responses aligned with live family answers more than 95 percent of the time, which let the team reserve costly human sessions for the concepts that survived the screen.[8] The same logic powers message testing on ad copy and landing-page optimization, where dozens of variants can be ranked before a single one is built. On the privacy-recovery side, tools like Pixum’s use of synthetic-user tracking to recover consent-gap conversions show a related but distinct trend: AI reconstructing lost signal rather than pre-testing creative.[10]
Where do these case-study numbers break down?
They break down when synthetic data is treated as a replacement for human panels rather than a filter. Verasight’s 2025 study found that LLM-generated samples performed poorly on multi-answer questions and on topics weakly linked to demographics, concluding that synthetic samples should be used with caution for consumer behaviour without strong demographic correlates.[9] The reported uplifts are real, but they belong to disciplined workflows.
Three guardrails separate the wins from the cautionary tales. First, calibrate against real consumer data, not generic prompts, since that is the 30-point accuracy difference. Second, keep a human validation round for the highest-stakes decisions. Third, read the synthetic scores as relative rankings between variants, which they predict well, rather than absolute market shares, which they predict less reliably. Used this way, the pre-test does one job extremely well: it stops you spending on the creative that was always going to lose.
Plug case-validated audience signals into your ad stack with neuroflash
neuroflash is not a chatbot or an LLM access tool. Your stack already has Copilot, Claude, Langdock, or ChatGPT for that. neuroflash is the Digital Twin audience research layer those agents call for calibrated, human-grounded signals, via API or MCP. It pre-tests ad creatives, messages, and audience segments against calibrated synthetic audiences so you lift CTR, CVR, and ROAS before the first euro of spend.
- 1,000,000+ real consumer profiles as the calibration base, collected since 2017
- 85 to 95 percent predictive parity with real human survey panels (versus around 55 percent for generic LLM prompts)
- Results in minutes, not 4 to 8 weeks of traditional fieldwork
- API and MCP access, plug Digital Twins into ChatGPT, Claude, Copilot, Langdock, or any agent that speaks MCP
- Validated by 80+ academic studies, used by Fortune-500 brands for Decision Security
Rank your creatives and segments against calibrated profiles in minutes, then enter the auction with a pre-validated winner instead of guesswork, the same move that produced the double-digit ROAS gains above. Start free.

Frequently asked questions
What is an AI synthetic audience in advertising?
An AI synthetic audience is a panel of AI personas calibrated against real consumer data that predicts how a defined target group will respond to an ad, message, or landing page before launch. In advertising it is used to rank creatives and segments so weak variants are removed before they consume media budget.
Do synthetic-audience pre-tests really lift conversion rate and ROAS?
Documented cases report double-digit gains, including +45 percent ROAS, +22 percent CVR, and +36 percent CTR on AI-pretested creative.[3] The lift comes from raising the average quality of what goes live, not from the simulation predicting exact campaign numbers, so results depend on disciplined execution.
How accurate are AI synthetic audiences compared with real panels?
In the strongest published study, synthetic panels reproduced 90 percent of human test-retest reliability with distributional similarity above 85 percent.[1] Stanford’s generative agents hit 85 percent normalized accuracy against real respondents.[2] Accuracy depends heavily on calibration data quality.
Can synthetic audiences replace traditional market research?
No. The best evidence frames them as a pre-filter, not a replacement. Verasight’s study shows synthetic samples struggle on questions weakly tied to demographics, so high-stakes decisions still warrant a human validation round.[9] The reliable workflow is synthetic first, human second.
Which brands and tools use synthetic audiences for advertising?
The Times validates concepts, Dentsu applies them to media planning, and Marketing Architects’ ScriptSooth tests TV scripts against synthetic audiences before production.[6][7] Research-grade calibration comes from layers like neuroflash that feed AI agents human-grounded signals via API and MCP.
My take
The honest read of these case studies is that synthetic audiences do not predict the future, they raise your batting average. Every documented uplift I found traces back to the same move: run a cheap synthetic round, kill the obvious losers, and let real budget chase only what already won the screen. The brands posting +45 percent ROAS are not trusting a simulation blindly; they are using it to stop funding the creative that was always going to underperform. Pair that discipline with calibration against real consumer data and a human check on the big calls, and the numbers in this article stop looking like marketing and start looking like basic operational hygiene for paid media.
References
- Maier, B. F. et al. (PyMC Labs and Colgate-Palmolive), 2025: “LLMs Reproduce Human Purchase Intent via Semantic Similarity Elicitation of Likert Ratings.” arxiv.org/html/2510.08338v1
- Park, J. S. et al. (Stanford University), 2024: “Generative Agent Simulations of 1,000 People.” arxiv.org/pdf/2411.10109
- digitalapplied, 2026: “AI Ad Creative Benchmarks 2026: CTR and ROAS Data (FULLBEAUTY Advantage+ case).” digitalapplied.com
- eMarketer, 2025: “For marketers, synthetic audiences are the new focus groups.” emarketer.com
- AdAmigo.ai, 2025: “Meta Ads ROAS Benchmarks by Industry (AI creative-optimization case).” adamigo.ai
- CMSWire, 2025: “Meet Your Synthetic Audience: Persona Research Goes AI (The Times, Dentsu).” cmswire.com
- Marketing Architects, 2024: “Marketing Architects Reveals AI Pretesting Tool ScriptSooth.” marketingarchitects.com
- Acceleration Community of Companies via eMarketer, 2025: “Gen Alpha synthetic focus-group alignment (95 percent).” emarketer.com
- Verasight, 2025: “Can Large Language Models Replicate Survey Data Across Topics?” verasight.io
- JENTIS, 2025: “Case Study: Pixum achieves 24% more ROAS with Synthetic Users.” jentis.com
- PyMC Labs, 2025: “AI Synthetic Consumers Now Rival Real Surveys.” pymc-labs.com


