
The world of artificial intelligence continues to evolve rapidly, and OpenAI’s latest model—ChatGPT o3-mini-high—marks a significant milestone in this journey. Combining enhanced reasoning capabilities with dramatic improvements in speed and cost efficiency, this new model is already reshaping how advanced language models are used in domains such as coding, math, and science.
Drawing on insights from recent benchmarks and industry analysis, we explore what makes o3-mini-high so compelling compared to its predecessors, and what its broader implications are for AI applications.

Advanced Reasoning Capabilities
ChatGPT’s o3-mini-high is one of OpenAI’s most recent advances in reasoning models—a variant that’s designed to deliver enhanced performance on challenging tasks while remaining cost‐efficient and fast.
Enhanced “Chain-of-Thought” Reasoning:
Unlike earlier models that primarily relied on pattern recognition, o3-mini-high incorporates an internal chain-of-thought process. This means it “thinks through” a problem by breaking it into intermediate reasoning steps before delivering an answer. This deliberate reasoning approach is especially beneficial for complex tasks in math, science, and coding.
Performance Benchmarks
Coding Performance:
- Competitive Programming:
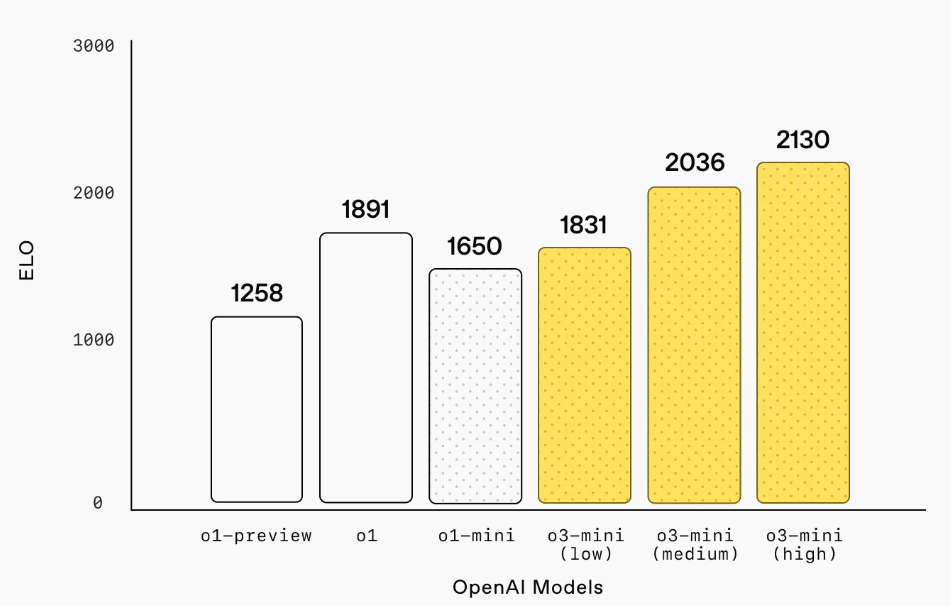
In tests such as on Codeforces, o3-mini-high has achieved an Elo rating of around 2,130—placing it among the top tiers of programming performance. This suggests that when it comes to writing and debugging code, the model can rival experienced human programmers. - Real-World Software Tasks:
In the SWE-bench Verified benchmark—designed to measure how well a model can solve real software engineering problems—o3-mini-high reached an accuracy of 49.3%, slightly outperforming the older GPT o1 model (which scored around 48.9%).
Mathematical Reasoning:
- AIME 2024:
For challenging math problems, such as those on the American Invitational Mathematics Examination (AIME), o3-mini-high has scored approximately 87.3%. This is a strong indicator of its ability to understand and solve high-level mathematical problems. - FrontierMath Benchmark:
When faced with expert-level math problems derived from challenging academic tasks (designed in part by top mathematicians), o3-mini-high has demonstrated a notable improvement—even achieving scores of about 9.2% on single-attempt tasks and up to 20% over multiple attempts.
(These numbers, while lower in absolute percentage, are significant given that many other models often only manage around 2% on such rigorous tests.)
Science and Domain-Specific Benchmarks:
- GPQA Diamond:
For questions in specialized fields—spanning biology, physics, and chemistry—the o3-mini-high variant scores around 79.7%, edging out the larger o1 model’s score of about 78.0%. This indicates its superior grasp of PhD-level science queries.
General Knowledge:
- While the model is specifically optimized for STEM fields, in broader benchmarks like the Massive Multitask Language Understanding (MMLU) test, o3-mini-high comes close to matching larger, more general-purpose models (scoring around 86.9% versus GPT-4o’s roughly 88.7%). This balance is particularly impressive given its smaller size and specialized optimization.
Speed and Efficiency
Response Speed:
- One of the standout features of o3-mini-high is its speed improvement. Compared to the previous o1 model, it is reported to be roughly 3.26 times faster.
- Techniques such as batch inference optimization allow the model to process multiple pieces of text simultaneously. For long texts, this can translate to up to a 78% reduction in processing time.
Cost Efficiency:
- The reduced token cost (for instance, around $1.15 per million tokens as opposed to significantly higher rates with earlier models) makes the model much more accessible. This cost efficiency is particularly valuable for developers and businesses integrating advanced reasoning into real-world applications, without incurring prohibitive expenses.
Applications and Impact
The improvements in o3-mini-high’s performance have several real-world implications:
- Coding Assistance: Its high programming accuracy and speed make it an excellent tool for automating code generation, debugging, and even for educational purposes.
- Mathematical Problem Solving: With its strong performance on advanced math benchmarks, it can support tutoring systems or serve as an assistant for researchers tackling complex mathematical challenges.
- Scientific Research: The model’s edge on benchmarks like GPQA Diamond positions it as a potential aid in research environments where deep, technical analysis is required.
- General AI Assistants: Although optimized for STEM, the model’s general knowledge performance means it can also be effectively used in multi-domain conversational agents.

o3-mini-high vs. o1: A Head-to-Head Comparison
🚩 Key Differences
Reasoning Process:
o3-mini improves upon o1 by introducing deeper internal deliberation (simulated reasoning), allowing it to more reliably handle complex, multi-step tasks.Performance Metrics:
Benchmarks show that o3-mini-high outperforms o1 in coding (higher competitive ratings and fewer errors), mathematics (higher test scores on advanced exams), and scientific reasoning (slightly higher scores on domain-specific benchmarks).Speed and Cost:
The o3-mini series is both faster and more cost-efficient, with significant improvements in latency and a token cost reduction that makes it viable for widespread use.User Experience:
By offering different reasoning levels (low, medium, high), o3-mini provides flexibility—allowing users to choose a balance between speed and accuracy that best suits their application, something that was less configurable in the o1 models.
1. Architectural and Reasoning Improvements
Enhanced Chain-of-Thought Reasoning:
- o1 Model: The o1 models were the first in OpenAI’s line to incorporate a “think-before-you-answer” process. They could generate internal chains of thought that helped reduce hallucinations and improve complex problem solving.
- o3-mini: Building on that foundation, the o3-mini series refines this process further. It employs a more robust “simulated reasoning” approach where the model not only generates an internal chain of thought but can adjust and self-correct during its reasoning process. This extra deliberation makes o3-mini (especially the high variant) significantly better at tasks that require multi-step reasoning—be it in mathematics, coding, or scientific inquiry.
- Example: On challenging math problems, o3-mini-high has achieved an 87.3% score on tests like AIME 2024, whereas o1 was comparatively lower.
2. Performance and Benchmark
Coding and Software Engineering:
- o1 Performance: The o1 models set a strong baseline by demonstrating solid performance in generating and debugging code.
- o3-mini Advantages: Recent benchmarks show that o3-mini-high scores around an Elo rating of 2,130 on competitive programming platforms (like Codeforces), placing it among the top tiers of coding proficiency. In the SWE-bench Verified benchmark—which evaluates the ability to solve real-world software issues—o3-mini-high achieved a 49.3% accuracy rate compared to approximately 48.9% for o1.
Mathematical Reasoning:
- o1 Performance: While o1 was already capable of tackling high-level math problems, its performance left room for improvement on rigorous academic benchmarks.
- o3-mini Enhancements: The o3-mini series pushes these boundaries further, scoring impressively on tests such as the American Invitational Mathematics Examination (AIME) and the FrontierMath benchmark. For instance, o3-mini-high not only scores higher (with AIME scores near 87.3%) but also shows better consistency in handling multi-step mathematical problems.
Scientific and Domain-Specific Tasks:
- o1 Model: Designed for scientific queries, o1 performed well on benchmarks like the GPQA Diamond test that measures the ability to answer advanced questions in biology, physics, and chemistry.
- o3-mini Superiority: The newer model scores around 79.7% on the GPQA Diamond benchmark, slightly surpassing the o1 model’s score of approximately 78.0%. This increment, while seemingly small, is important in specialized domains where precision is critical.
General Knowledge and Context Handling:
- Context Windows: Both models are designed to handle long-form content; however, o3-mini comes with a highly competitive context window (up to 200,000 tokens), which enables it to manage more extended and complex interactions without losing track of context.
- Overall Accuracy: In broader evaluations like the Massive Multitask Language Understanding (MMLU) benchmark, o3-mini-high scores around 86.9%, coming very close to larger models (for example, GPT-4o scores around 88.7%). While o1 had set a strong baseline in general language understanding, o3-mini’s improvements show that its optimizations for reasoning do not come at the expense of broader knowledge.
3. Speed, Efficiency, and Cost
Speed and Latency:
- o1 Model: Although robust in its reasoning, the o1 model sometimes lagged in response times when dealing with complex queries.
- o3-mini Performance: The o3-mini series is engineered for faster responses—reports indicate that the high variant can be up to 3.26 times faster than o1 in some tasks. Additionally, batch inference optimization in o3-mini allows for processing multiple queries simultaneously, cutting long-text processing times by as much as 78%.
Cost Efficiency:
- Cost per Token: One of the standout improvements of the o3-mini models is their drastically lower cost. While the older o1 model might cost upwards of $12.50 per million tokens for input processing, o3-mini-high is priced significantly lower—around $1.15 per million tokens. This makes advanced reasoning more accessible, especially for developers integrating these models into high-volume applications.
- User Accessibility: With o3-mini now available across both free and paid tiers (with the high-reasoning variant reserved for subscribers like ChatGPT Plus, Team, and Pro users), OpenAI has broadened the user base while still offering a premium option for more demanding applications, thanks to continuous openAI optimization.
Conclusion
OpenAI’s o3-mini-high represents a major leap forward from the earlier o1 and o1-mini models. At its core, it is designed to offer robust reasoning while keeping latency low and costs down. Specialized for STEM tasks, it provides users with multiple reasoning effort levels—ranging from the default medium effort (which matches the performance of o1 but with faster response times) to the high effort variant that delivers even greater accuracy for demanding challenges. With a dramatic reduction in token costs (down by 95% since GPT-4), o3-mini-high makes high-quality, advanced reasoning more accessible than ever before.




