





Inleiding tot GPT-3
GPT-3 (Generative Pre-trained Transformer 3) is een geavanceerd taalmodel ontwikkeld door OpenAI. GPT-3 is gebouwd op de Transformer-architectuur, is de derde iteratie van de GPT-serie en werd uitgebracht in 2020. De term “Generatief” geeft aan dat deze modellen tekst kunnen genereren en “Voorgetraind” suggereert dat ze worden getraind op grote hoeveelheden gegevens voordat ze worden verfijnd voor specifieke taken. Met zijn indrukwekkende vermogen om mensachtige tekst te begrijpen en te genereren, heeft GPT-3 zich ontpopt als een van de krachtigste taalgeneratoren voor kunstmatige intelligentie tot nu toe.
GPT-3 heeft een uitgebreid neuraal netwerkmodel met maar liefst 175 miljard parameters, een aanzienlijke toename ten opzichte van zijn voorganger GPT-2. Dankzij de enorme parameterruimte kan het model complexe patronen in uitgebreide datasets onderscheiden en de onderliggende structuren van teksten beter begrijpen.
Technische specificaties van GPT-3
Parameter
Architectuur
Parameters
Voortrainingsgegevens
Gegevens verfijnen
Maximale sequentielengte
Inferentiesnelheid
Uitgebracht Jaar
Waarde
Transformator
175 miljard
Diverse tekstcorpora
Aanpasbaar voor taken
2048 munten
Verschilt per hardware
2020
Ontwikkeling van GPT-3
GPT verwijst naar een familie van kunstmatige intelligentie taalmodellen ontwikkeld door OpenAI. De Transformer-architectuur, geïntroduceerd in het artikel “Attention Is All You Need” van Vaswani et al. in 2017, vormt de basis van GPT-modellen. Transformers gebruiken een zelfattractiemechanisme om invoergegevens parallel te verwerken, waardoor ze zeer efficiënt zijn voor taken met sequentiële gegevens, zoals natuurlijke taalverwerking.
De GPT-technologie is in de loop der tijd geëvolueerd en vanaf de laatste update in maart 2023 zijn er vier grote iteraties: GPT, GPT-2, GPT-3 en GPT-4.
- GPT: Het oorspronkelijke GPT-model, uitgebracht in 2018, was een doorbraak in natuurlijke taalverwerking. Het bestond uit 117 miljoen parameters en werd getraind op een breed scala aan internettekstgegevens.
- GPT-2: GPT-2 werd uitgebracht in 2019 en was een grotere en krachtigere versie van de oorspronkelijke GPT. Het had 1,5 miljard parameters, waardoor het beter in staat was om samenhangende en contextueel relevante tekst te genereren. Vanwege zorgen over mogelijk misbruik voor het genereren van nepnieuws, beperkte OpenAI aanvankelijk de toegang tot het volledige model, maar maakte het later openbaar.
- GPT-3: Geïntroduceerd in 2020, bracht GPT-3 de mogelijkheden van zijn voorgangers naar een heel nieuw niveau. Met maar liefst 175 miljard parameters werd het een van de grootste taalmodellen ooit gemaakt. GPT-3 toonde een ongekend taalbegrip en genereerde zeer realistische en contextueel passende antwoorden op uiteenlopende vragen.
- GPT-4: GPT-4 is het nieuwste taalmodel ontwikkeld door OpenAI, uitgebracht op 14 maart 2023. Als vierde versie in de GPT-serie is het een groot multimodaal taalmodel dat zowel tekst als afbeeldingen kan begrijpen. GPT-4 wordt getraind met behulp van “pre-training”, waarbij het volgende woord in zinnen wordt voorspeld op basis van uitgebreide en diverse gegevensbronnen. Daarnaast maakt het gebruik van reinforcement learning, waarbij het leert van menselijke en AI-feedback om zijn reacties af te stemmen op menselijke verwachtingen en richtlijnen. Hoewel beschikbaar voor het publiek via ChatGPT Plus, is volledige toegang tot GPT-4 via OpenAI’s API momenteel beperkt en wordt aangeboden via een wachtlijst. Hoewel het een verbetering is ten opzichte van GPT-3.5 in de ChatGPT-toepassing, heeft GPT-4 nog steeds te maken met een aantal vergelijkbare problemen en specifieke technische details over de modelgrootte zijn nog niet bekend gemaakt.
Deze GPT-modellen zijn voorbeelden van unsupervised learning, waarbij de modellen leren van enorme hoeveelheden tekstgegevens zonder expliciete labels of annotaties. Tijdens de pre-training fase ontwikkelen de modellen een begrip van taal en context en tijdens de fine-tuning fase worden ze aangepast voor specifieke taken zoals vertalen, samenvatten, vragen beantwoorden en meer.
Hoe GPT-3 werkt
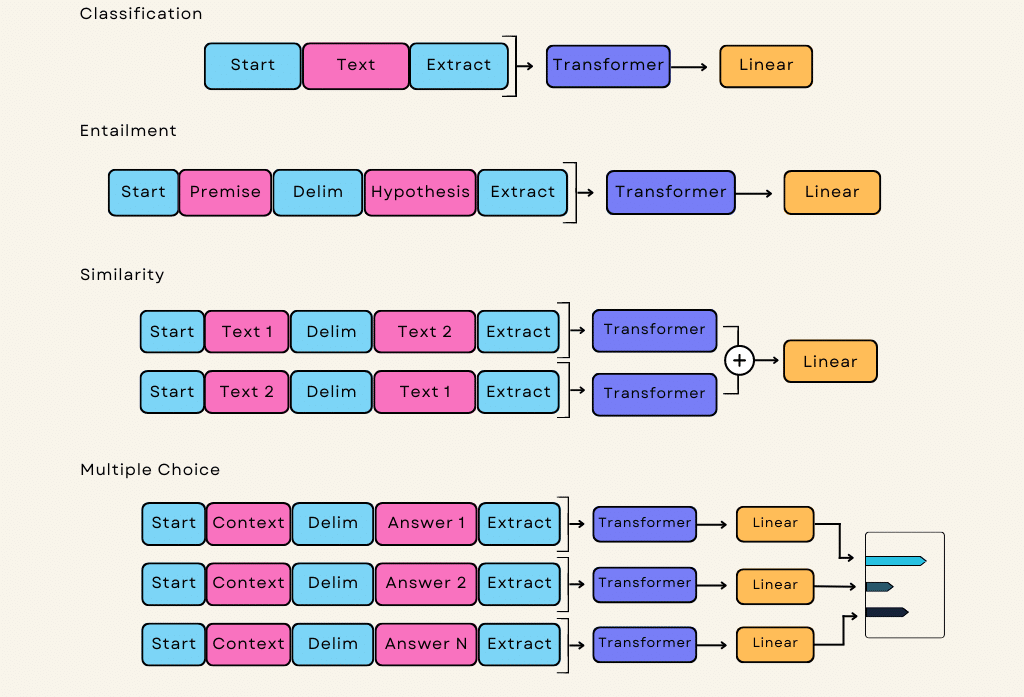
Door gebruik te maken van de Transformer-architectuur, blinkt GPT-3 uit in het herkennen van lange-afstandsrelaties tussen woorden en zinnen in een tekst. Dit verbeterde begrip van de context stelt het model in staat om semantisch coherente antwoorden te genereren. Bovendien maakt de kunstmatige intelligentie gebruik van een “unsupervised learning” benadering, waardoor taakspecifieke training vooraf niet nodig is. Hier wordt uitgelegd hoe alles in detail werkt:
- Architectuur: GPT-3 is gebaseerd op de Transformer-architectuur, die in 2017 werd geïntroduceerd in het artikel “Attention Is All You Need” van Vaswani et al. De Transformer architectuur maakt gebruik van een nieuw zelf-attentie mechanisme dat het model in staat stelt om invoergegevens parallel te verwerken, waardoor het zeer efficiënt is voor het verwerken van reeksen, zoals natuurlijke taal.
- Voortraining: GPT-3 is “voorgetraind” op een enorme dataset met diverse teksten uit verschillende bronnen, zoals boeken, artikelen en websites. Tijdens het voortrainen leert het model het volgende woord in een reeks te voorspellen op basis van de voorgaande woorden. Dit proces stelt het model bloot aan een uitgebreid begrip van grammatica, context en relaties tussen woorden.
- Parameters: GPT-3 is een enorm model met 175 miljard parameters. Parameters zijn de leerbare gewichten die het model gebruikt om voorspellingen te doen tijdens training en inferentie. Dankzij het enorme aantal parameters kan GPT-3 complexe patronen en nuances in de gegevens vastleggen.
- Fijnafstemming: Na pre-training op het grote tekstcorpus wordt GPT-3 verfijnd voor specifieke taken. Fine-tuning houdt in dat het model wordt getraind op meer gespecialiseerde datasets voor taken als vertalen, samenvatten, vragen beantwoorden en meer. Dit proces zorgt ervoor dat de mogelijkheden van het model relevanter en nauwkeuriger worden voor specifieke toepassingen.
- Zero-Shot en Few-Shot Leren: Een opmerkelijk aspect van GPT-3 is de mogelijkheid om “zero-shot” en “few-shot” leren uit te voeren. Zero-shot learning stelt het model in staat om plausibele reacties te genereren voor taken waarop het niet expliciet is afgestemd, gebaseerd op een beschrijving van de taak. Few-shot learning stelt het model in staat om zich aan te passen aan nieuwe taken met slechts een paar voorbeelden of demonstraties, zonder uitgebreide hertraining.
- Tekst genereren en aanvullen: Gegeven een opdracht of context kan GPT-3 coherente en contextueel geschikte tekst genereren, of het nu gaat om het aanvullen van een zin, het schrijven van alinea’s of zelfs het componeren van creatieve verhalen of gedichten.
- Begrip van natuurlijke taal: GPT-3 kan natuurlijke taal begrijpen en verwerken, waardoor het vaardig is in het beantwoorden van vragen, het geven van uitleg en het aangaan van gesprekken met gebruikers.
- Beperkingen: Hoewel GPT-3 een zeer geavanceerd taalmodel is, is het niet zonder beperkingen. Het kan soms antwoorden genereren die plausibel klinken, maar feitelijke nauwkeurigheid missen of vertekeningen vertonen die aanwezig zijn in de trainingsgegevens. Bovendien kan het een uitdaging zijn om de uitvoer te controleren op naleving van specifieke vereisten.
Toepassingen van GPT-3
GPT-3 wordt toegepast in verschillende domeinen, waardoor het een veelzijdig taalmodel is:

- Programmeren: GPT-3 kan stukjes code genereren en helpen bij het begrijpen en verbeteren van code in meerdere programmeertalen.
- Creatieve toepassingen: GPT-3 kan creatieve teksten genereren, zoals gedichten, verhalen en songteksten, die kunstenaars inspireren bij hun creatieve inspanningen.
- Onderzoek en analyse: De mogelijkheid om enorme hoeveelheden tekstgegevens te verwerken helpt bij onderzoek en analyse van tekstcorpora en literatuur.
- Taalgeneratie: GPT-3 kan tekst van hoge kwaliteit produceren, van eenvoudige zinnen tot volledige artikelen en verhalen.
- Chatbots en virtuele assistenten: De mogelijkheden dienen als basis voor de ontwikkeling van geavanceerde chatbots en virtuele assistenten die mensachtige interacties mogelijk maken.
- Teksttaken automatiseren: Het model kan repetitieve taken automatiseren, zoals tekst samenvatten, vertalen en e-mail beantwoorden.
GPT-3 gebruiken met het OpenAI Token Systeem
Het tokensysteem is een fundamenteel concept in GPT-3 en andere taalmodellen gebaseerd op de Transformer-architectuur. Tokens zijn de individuele teksteenheden die het model verwerkt. In de context van natuurlijke taal kunnen tokens zo kort zijn als één karakter of zo lang als één woord.
In GPT-3 wordt de ingevoerde tekst opgedeeld in tokens voordat deze wordt ingevoerd in het model voor verwerking. Op dezelfde manier wordt de uitvoer van het model geproduceerd in de vorm van tokens, die vervolgens weer worden omgezet in leesbare tekst.

Hier zijn enkele belangrijke punten om te begrijpen over het tokensysteem achter GPT-3:
- Tokenisatie: Tokenization is het opsplitsen van een doorlopende tekst in individuele tokens. De zin “Hallo, hoe gaat het?” kan bijvoorbeeld worden getokeniseerd in [“Hallo”, “,”, “hoe”, “zijn”, “jij”, “?”].
- Token grootte: De grootte van tokens in GPT-3 kan variëren, maar meestal wordt een tokenmethode met subwoorden gebruikt. In plaats van elk woord als een enkel token weer te geven, kan GPT-3 woorden opsplitsen in kleinere eenheden, subwoorden genoemd. Het woord “ongelooflijk” kan bijvoorbeeld getoken worden in [“un”, “##believable”]. Met deze tokenisatie van subwoorden kan het model effectief omgaan met zeldzame woorden en morfologische variaties.
- Token Beperking: GPT-3 heeft een maximale tokenlimiet, wat betekent dat het alleen een vast aantal tokens kan verwerken in een enkele API-aanroep. Bij mijn laatste update was de maximale tokenlimiet 4096 tokens voor GPT-3.
- Token tellen mee in de kosten: Zowel invoer- als uitvoertokens tellen mee in de kosten bij gebruik van GPT-3 via de OpenAI API. Dit betekent dat je betaalt op basis van het totale aantal tokens dat wordt gebruikt in je API-verzoek en de respons die wordt gegenereerd door het model.
- Token beperkingen: Om ervoor te zorgen dat een bepaalde tekstinvoer binnen de tokenlimiet van het model past, kan het nodig zijn om delen van de tekst in te korten of weg te laten, afhankelijk van de lengte.
- Token Economisatie: Aangezien de kosten voor het gebruik van GPT-3 gebaseerd zijn op het aantal tokens, proberen ontwikkelaars vaak hun API-aanroepen te optimaliseren om het tokengebruik te minimaliseren en toch de gewenste resultaten te bereiken.
Inzicht in het tokensysteem is essentieel om GPT-3 effectief te gebruiken, omdat het niet alleen de verwerkingscapaciteit van het model beïnvloedt, maar ook de kosten die gepaard gaan met het gebruik ervan. Ontwikkelaars moeten rekening houden met het tokengebruik en hun tekstinvoer zo aanpassen dat deze binnen de tokenlimieten past om de mogelijkheden van GPT-3 efficiënt te benutten.
Uitdagingen en ethische overwegingen bij GPT-3
Ondanks de indrukwekkende prestaties van GPT-3 heeft het te maken met uitdagingen en ethische bezwaren die kenmerkend zijn voor geavanceerde kunstmatige intelligentietechnologie:
- Vertekening en eerlijkheid: GPT-3 is gevoelig voor vertekening, omdat het leert van grote datasets die mogelijk niet perfect in balans zijn, wat kan leiden tot oneerlijke of discriminerende reacties.
- Misbruik: De technologie kan worden misbruikt voor frauduleuze of manipulatieve doeleinden, zoals het verspreiden van verkeerde informatie of het genereren van valse inhoud.
- Controle over uitgangen: Het kan een uitdaging zijn om de uitvoer van GPT-3 te controleren, wat kan leiden tot ongewenste of ongepaste reacties.
- Veiligheid en beveiliging: GPT-3 is een krachtige technologie met kunstmatige intelligentie en kan schadelijke inhoud genereren, zoals haatdragende taal, intimidatie of gewelddadig taalgebruik. Het waarborgen van veiligheidsmaatregelen om te voorkomen dat het model schadelijke uitvoer genereert, is een belangrijk punt van zorg.
- Overfitting en memorisatie: GPT-3 kan soms specifieke gegevenspatronen onthouden tijdens de pre-training, wat leidt tot overfitting op bepaalde datasets. Dit kan ertoe leiden dat het model nauwkeurig klinkende, maar foutieve of onbetrouwbare informatie geeft.
- Verklaarbaarheid en interpreteerbaarheid: Het besluitvormingsproces van GPT-3 wordt vaak beschouwd als een “black box” vanwege de complexe neurale netwerkarchitectuur. Dit gebrek aan transparantie kan leiden tot bezorgdheid over de besluitvorming van het model en de kans op bevooroordeelde of onverklaarbare antwoorden.
- Milieu-impact: Voor het trainen van grote taalmodellen zoals GPT-3 is veel rekenkracht en energieverbruik nodig. Er moet rekening worden gehouden met de milieueffecten van het trainen en gebruiken van dergelijke modellen op schaal.
- Auteursrecht en intellectueel eigendom: De gegevens die gebruikt worden om GPT-3 voor te trainen bevatten vaak auteursrechtelijk beschermde inhoud van verschillende bronnen. Er kunnen juridische en ethische implicaties zijn met betrekking tot het gebruik van auteursrechtelijk beschermd materiaal in het trainingsproces.
- Inclusiviteit en toegankelijkheid: Taalmodellen zoals GPT-3 voldoen mogelijk niet volledig aan de behoeften van gebruikers met verschillende taalachtergronden of personen met een handicap. Het waarborgen van inclusiviteit en toegankelijkheid is van vitaal belang bij het inzetten van AI-modellen voor breder gebruik.
- Onbedoelde gevolgen: De toepassing van GPT-3 en vergelijkbare AI-technologieën kan onbedoelde gevolgen hebben voor de samenleving, zoals economische verstoringen, veranderingen in werkgelegenheidspatronen en maatschappelijke afhankelijkheid van AI voor het nemen van beslissingen.
- Afhankelijkheid van AI: Naarmate AI-technologieën zoals GPT-3 meer ingang vinden, bestaat het risico dat er te veel op wordt vertrouwd, wat kan leiden tot verlies van menselijke vaardigheden en kritisch denkvermogen.
- Privacy en eigendom van gegevens: Het gebruik van GPT-3 kan betekenen dat gevoelige gebruikersgegevens worden gedeeld met de AI-provider, waardoor bezorgdheid ontstaat over gegevensprivacy, eigendom en de mogelijkheid van gegevensexploitatie.
- Wettelijke en juridische uitdagingen: De inzet van krachtige AI-modellen zoals GPT-3 kan leiden tot regelgevende en juridische uitdagingen met betrekking tot aansprakelijkheid, verantwoordingsplicht en naleving van bestaande wet- en regelgeving.
Het aanpakken van deze uitdagingen en ethische bezwaren is cruciaal om te zorgen voor een verantwoord en nuttig gebruik van GPT-3 en andere geavanceerde AI-technologieën en om vertrouwen en transparantie in AI-toepassingen te bevorderen.
Verwante koppelingen
Houd er rekening mee dat de gegevens in dit artikel kunnen veranderen als er in de toekomst nieuwere versies of verbeteringen aan GPT-3 worden uitgebracht.


