Marktsegmentierung ist seit den 1960er-Jahren das methodische Rückgrat strategischen Marketings. Sinus-Milieus, McKinsey 7S, klassische Cluster-Analysen mit K-Means oder Latent Class Analysis sind die etablierten Werkzeuge der Branche. Was sich 2026 grundlegend verändert: Die Datenbasis. Statt klassischer Befragungen mit 1.500 bis 3.000 Konsumenten liefern AI-Plattformen Segmentierungen auf Basis synthetischer Daten, mit Stichproben in den Zehntausenden, in Tagen statt Wochen, zu einem Bruchteil der Kosten.
Die Versprechen sind groß, die methodische Validität ist differenziert. PyMC Labs dokumentiert in der Mega-Studie mit 57 realen Konsumenten-Studien (n=9.300): Synthetic Consumers erreichen 90 Prozent der Human-Test-Retest-Reliabilität und über 85 Prozent Distributional Similarity.[3] Gleichzeitig warnen Branchenstimmen vor naivem Vollersatz, weil synthetische Segmente bei spezifischen Use-Cases drastisch schlechter performen.[6]
Dieser Pillar liefert die Methodik, die Validitäts-Diskussion, die Algorithmen-Auswahl und den pragmatischen Entscheidungsrahmen für Insights-Teams, die 2026 zwischen klassischer und AI-Segmentierung entscheiden müssen.
Warum klassische Segmentierung in der Krise steckt
Drei strukturelle Probleme machen klassische Segmentierungs-Studien zunehmend schwer rechtfertigbar.
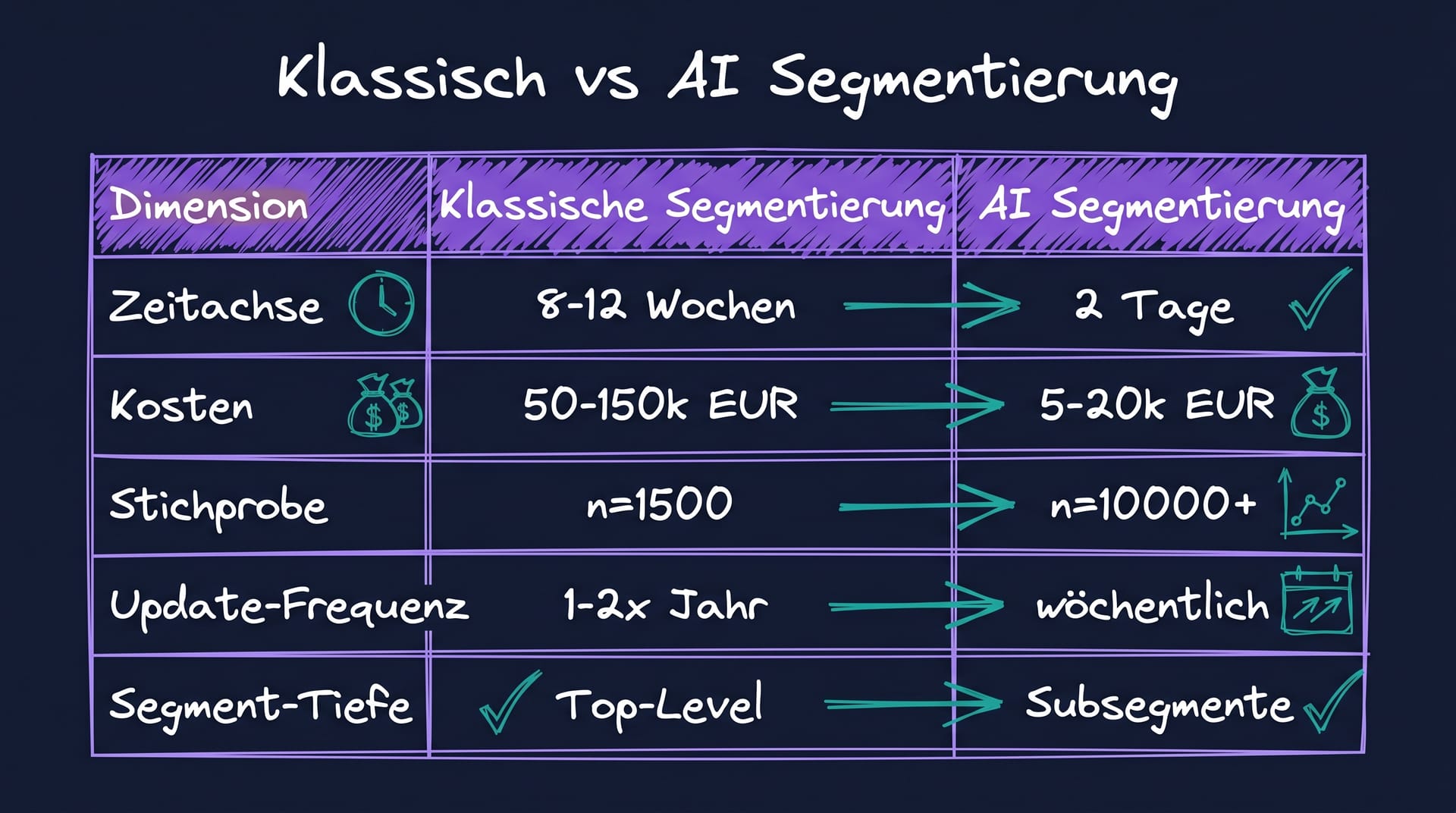
Erstens, Kosten. Eine professionelle Custom-Segmentierungs-Studie bei Ipsos, GfK oder einem ähnlichen Anbieter kostet 50.000 bis 150.000 Euro, mit Stichproben zwischen 1.500 und 3.000 Befragten.[2] Für Mid-Market-Marken ist das nicht jährlich finanzierbar.
Zweitens, Geschwindigkeit. Eine Welle braucht acht bis zwölf Wochen von Briefing bis finalem Report. In einer Welt, in der Konsumenten-Präferenzen sich quartalsweise verschieben, ist das ein strukturelles Problem.
Drittens, Veralten der Segmente. Klassische Segmente werden alle zwei bis drei Jahre aktualisiert. Zwischen den Aktualisierungen arbeiten Marketing-Teams mit Daten, die schon bei Veröffentlichung nicht mehr ganz aktuell waren. Sinus-Milieus, der DACH-Goldstandard, wird in der b4p-Studie 2024 mit 30.000 Interviews aktualisiert, läuft aber als Strukturmodell seit den 1980er-Jahren.[5]
Qualtrics prognostiziert in seinen Trends-Reports: In drei Jahren wird mehr als die Hälfte der Marktforschung synthetisch ergänzt sein.[8] Die Branche befindet sich in einem methodischen Übergang, der die Segmentierungs-Praxis als erste tiefgreifend verändert.
Methodische Grundlagen: 5 Algorithmen-Schulen
Bevor wir über synthetische Daten reden, ist die Algorithmen-Frage zu klären. Fünf Schulen dominieren 2026 die Segmentierungs-Praxis.
Schule 1: K-Means. Schnell, skalierbar, einfach zu implementieren. Findet runde, gleichgroße Cluster. Standard für viele DACH-Studien.[1]
Schule 2: Hierarchical Clustering. Liefert eine Hierarchie von Clustern (Dendrogramm), interpretierbar, gut für kleine bis mittlere Datensätze. Analytics India Mag dokumentiert in einer Vergleichsstudie: K-Means erreicht Silhouette 0.29, Hierarchical 0.25 für vergleichbare Customer-Segmentation-Datensätze.
Schule 3: Latent Class Analysis (LCA). Probabilistisches Modell, das jedem Respondenten Wahrscheinlichkeiten für Cluster-Zugehörigkeit zuordnet. SKIM nutzt LCA als methodisches Rückgrat für Segmentierungs-Studien.[4] Statistical Innovations bietet mit Latent Gold das Industrie-Standard-Tool.
Schule 4: Neural Embedding Clustering. Nutzt Deep-Learning-Modelle (BERT, Autoencoder), um Konsumenten-Daten in hochdimensionale Vektor-Räume zu projizieren. Springer-Paper aus 2024 dokumentieren Deep Embedding Clustering mit Residual Autoencoder als State-of-the-Art für Big-Data-Segmentierung.[9]
Schule 5: DBSCAN und dichtebasierte Methoden. Findet Cluster beliebiger Form und ist tolerant gegenüber Ausreißern. Besonders nützlich für Behavioral-Daten.
Welcher Algorithmus für welchen Use-Case passt, vertieft unser Schwester-Cluster Einsatz von KI in der Segmentierungsanalyse.
Was synthetische Daten in der Segmentierung verändern
Synthetische Daten verändern nicht den Algorithmus selbst, sondern die Datenbasis, auf der der Algorithmus rechnet. Das hat drei tiefgreifende Konsequenzen.
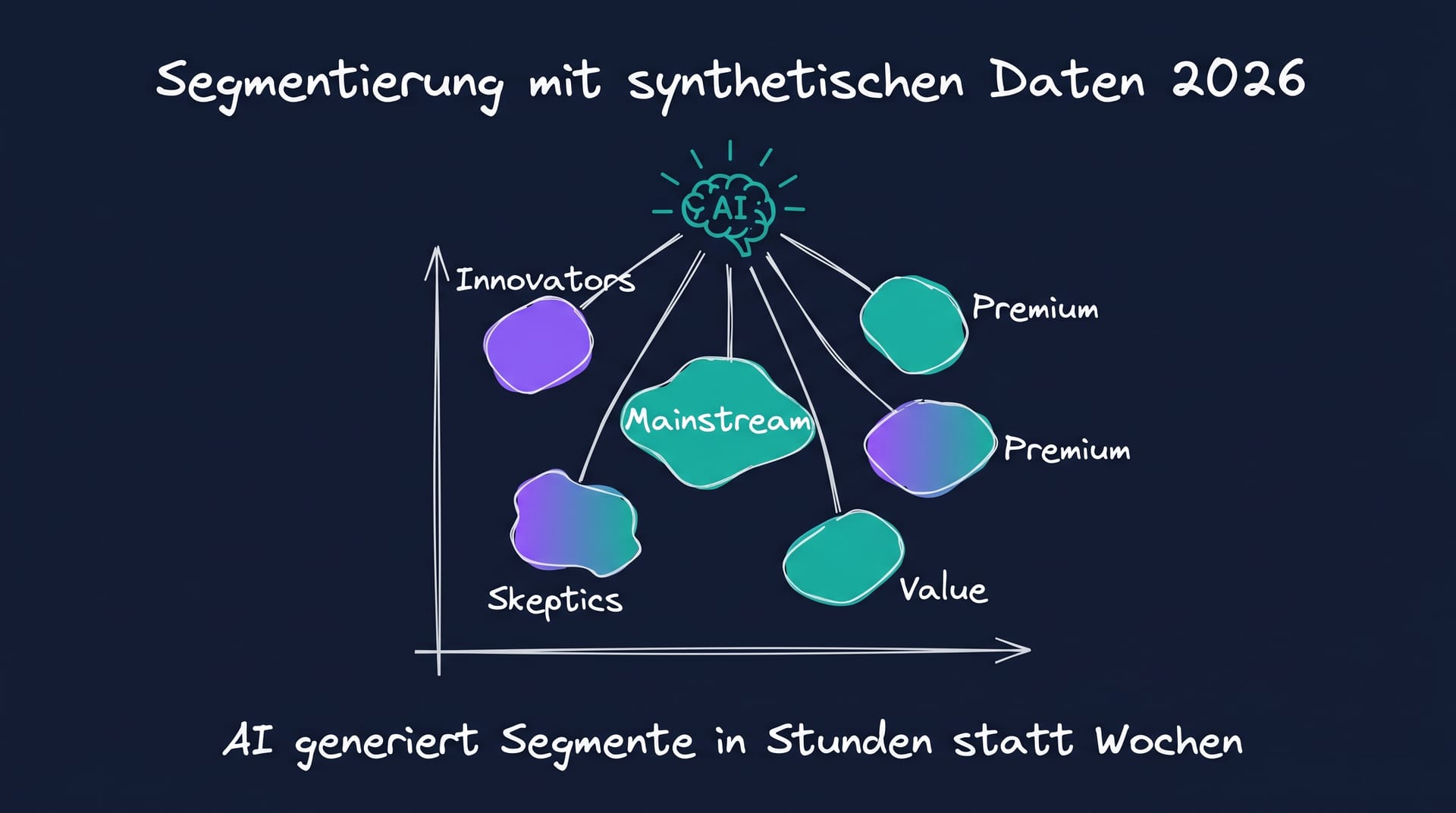
Konsequenz 1: Sample-Größen werden quasi-kostenlos. Wenn die Datenbasis aus einem Foundation-Modell stammt (GPT, Claude, Gemini, kalibriert auf realen Profilen), kosten zusätzliche Befragungen praktisch nichts mehr. Stichproben von 10.000 plus pro Segment werden Standard, statt der klassischen 200 bis 400 pro Cluster.[3]
Konsequenz 2: Sub-Segment-Tiefe wird methodisch realistisch. Klassische Studien stoßen bei Sub-Segmenten mit unter 50 Befragten an Belastbarkeits-Grenzen. Synthetische Datenbasen ermöglichen 1.000 plus Befragte auch für kleinste Sub-Segmente, was differenziertere Segment-Profile liefert.
Konsequenz 3: Iterations-Geschwindigkeit explodiert. Wo klassisch eine Segmentierung im Quartals-Rhythmus aktualisiert wird, läuft synthetische Segmentierung wöchentlich oder monatlich.
neuroflash dokumentiert in DACH-Use-Cases: Segmentierungen in Stunden statt Wochen, kalibriert auf über einer Million realer Profile als Trainingsbasis.[4]
Validität synthetischer Segmente: Die ehrliche Antwort
Die zentrale Frage für jeden Insights-Team-Lead: Wie belastbar sind Segmente, die auf synthetischen Daten basieren?
Positive Befunde: PyMC Labs dokumentiert 90 Prozent Alignment mit Realdaten und 85 Prozent Distributional Similarity in 57 Konsumenten-Studien.[3] Qualtrics dokumentiert Validierungs-Frameworks, die saubere Methodik ermöglichen.[8] neuroflash kommuniziert 85 bis 98 Prozent Accuracy im DACH-Kontext, mit 36 bis 62 Prozent Reduktion politischer Verzerrungen gegenüber generischen LLMs.[4]
Kritische Befunde: Bisbee et al. haben in der Forschung dokumentiert, dass ChatGPT-Antworten auf Survey-Skalen oft nur 1 Prozent (r²) der menschlichen Attitude-Patterns reproduzieren.[6] Die methodische Skepsis ist berechtigt: Synthetische Daten sind nicht gleich synthetische Daten. Die Qualität hängt fundamental von der Kalibrierungs-Methodik ab.
Konvergenz-Befund: Der Marktforschungs-Branchenkonsens 2026 lautet: Hybride Ansätze sind die belastbare Zukunft. Cogitaris hat das in einem viel zitierten Whitepaper formuliert: Synthetic Data plus reale Validierung schlägt sowohl reines Synthetic als auch reines Real.[8] ESOMAR-Congress-Papers konvergieren auf das gleiche Bild.[10]
Wie die Eignung synthetischer Daten für valide Marktsegmente konkret zu prüfen ist, vertieft unser dedizierter Schwester-Cluster.
Anwendungsfälle: Wo synthetische Segmentierung wirklich liefert
Aus den dokumentierten Cases lassen sich vier Sweet-Spots ableiten.
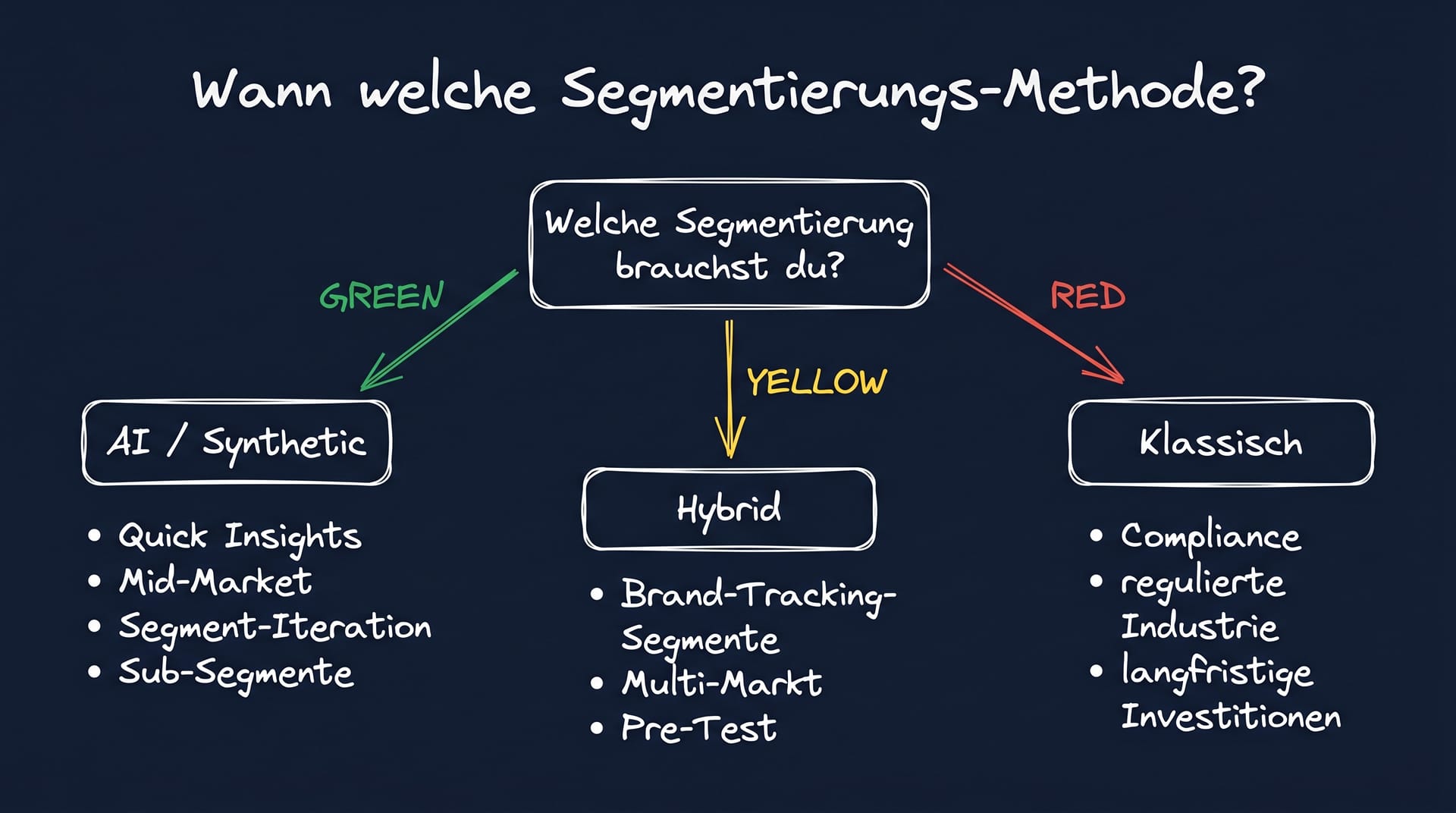
Sweet-Spot 1: Schnelle Marken-Iteration. Kampagnen-Vorbereitungen, in denen das Marketing-Team innerhalb von Tagen eine Zielgruppe-Tiefe braucht, bevor Budget freigegeben wird.
Sweet-Spot 2: Mid-Market-Marken mit eingeschränktem Insights-Budget. Wo klassische Custom-Studien nicht finanzierbar sind, liefert synthetische Segmentierung brauchbare Werte für 5.000 bis 20.000 Euro pro Jahr.
Sweet-Spot 3: Sub-Segment-Vertiefung. Wenn ein klassisch existierendes Segment intern weiter aufgegliedert werden soll (etwa der Premium-Käufer-Cluster in Early-Adopter und Status-Käufer), liefern synthetische Audiences die benötigte Tiefe ohne Boost-Sample-Kosten.
Sweet-Spot 4: B2B-Nischen-Segmentierung. B2B-Zielgruppen sind klassisch teuer zu rekrutieren. Synthetische Buying-Center-Simulationen lösen das Recruiting-Engpass-Problem.
Für Zielgruppen-Replikation aus seed-Audiences, etwa via LinkedIn Predictive Audiences oder Meta Advantage+, gibt es eigene Methodik. Vertiefung im Schwester-Cluster AI für Zielgruppenreplikation.
Limits: Wo synthetische Segmentierung versagt
Drei Limits sind 2026 hart und nicht wegdiskutierbar.
Limit 1: Trauma-, Stigma- und politische Themen. Bei sensiblen Themen reproduzieren LLM-basierte Modelle gesellschaftliche Bias-Patterns, ohne die methodische Diversität echter Befragungen abbilden zu können. Diese Use-Cases bleiben klassische Domäne.[6]
Limit 2: Long-Tail-Demografien. Wenn die Zielgruppe im Trainingsdatensatz unterrepräsentiert ist (etwa spezifische Migranten-Communities in DACH, ältere Senioren, ländlich-isolierte Konsumenten), bricht die Genauigkeit synthetischer Modelle ein.
Limit 3: Sensorische, emotionale, körperliche Erfahrungen. Synthetische Audiences können nichts schmecken, riechen, fühlen. Für Konzepte, deren Wirkung primär sensorisch ist, bleibt qualitative Realforschung Pflicht. Das gilt besonders im Einzelhandel und Konsumgüterbereich. Mehr dazu im Schwester-Cluster Digital Twins für qualitative Insights und Customer Journey.
Marktforschung.de hat in einem Praxistest-Artikel deutlich gemacht: Strukturierte Qualitätsbewertungen synthetischer Daten fehlen aktuell in vielen DACH-Insights-Teams.[6] Die Eigenverantwortung pro Use-Case ist hoch.
Best-Practice-Stack für synthetische Segmentierung 2026
Wer 2026 produktiv segmentiert, baut einen Drei-Schichten-Stack.
Schicht 1: Klassische Basis-Segmentierung. Alle zwei Jahre eine klassische Wellen-Segmentierung mit echten Stichproben, methodisch sauber durchgeführt. Das ist der Methodik-Anker für Vergleichbarkeit über die Zeit.
Schicht 2: Synthetische Sub-Segmentierung und Iteration. Zwischen den klassischen Wellen werden Sub-Segmente synthetisch vertieft, neue Hypothesen synthetisch geprüft, schnelle Iterations-Zyklen synthetisch gefahren.
Schicht 3: Live-Validierung in Pilot-Kampagnen. Synthetische Segmente werden vor produktivem Marketing-Einsatz in kleinen Pilot-Kampagnen validiert. Wenn die tatsächliche Marktreaktion mit den synthetischen Vorhersagen konvergiert, ist das Segment für größere Roll-outs freigegeben.
HSLU IKM hat das Modell 2025 detailliert beschrieben: Synthetische Daten als Ergänzung, nicht Ersatz, mit klaren Validierungs-Pflichten.[7]
Vertiefung: Die vier Themen-Cluster zur Segmentierung mit KI
Die folgenden spezialisierten Artikel vertiefen einzelne Aspekte dieses Pillars:
- Einsatz von KI in der Segmentierungsanalyse liefert die Algorithmen-Übersicht (K-Means, LCA, Hierarchical, Neural Embeddings, DBSCAN) plus 7-Schritte-Workflow.
- Eignung synthetischer Daten für valide und handlungsanweisende Marktsegmente gibt das 5-Schritte-Validierungs-Framework mit konkreten KPIs.
- AI für Zielgruppenreplikation: Methodik und Grenzen erklärt LinkedIn Predictive Audiences, Meta Advantage+ und die fünf harten Grenzen.
- Digital Twins für qualitative Insights und Customer Journey Verständnis zeigt Customer Journey Mapping mit Twins inklusive Retail-Limits.
Mit neuroflash Digital Twins synthetische Segmente bauen

neuroflash Digital Twins ist die DACH-Plattform für synthetische Segmentierung. Über eine Million reale Profile als Datenbasis, 85 Prozent plus Vorhersagegenauigkeit gegenüber Realbefragungen, Segmentierungen in Stunden statt Wochen. Ideal als Sub-Segment-Vertiefung und Iterations-Schicht im Hybrid-Stack. Jetzt neuroflash testen.
FAQ
Was ist Segmentierung mit synthetischen Daten methodisch?
Marktsegmentierung, deren Datenbasis nicht aus realen Konsumenten-Befragungen, sondern aus LLM-basierten Modellen stammt, die auf realen Profilen kalibriert sind. Die Algorithmen (K-Means, LCA, Neural Embeddings) bleiben gleich, nur die Stichprobe wird synthetisch generiert.[3]
Wie genau sind synthetische Segmente?
Zwischen 65 und 95 Prozent Genauigkeit gegenüber Realbefragungen, abhängig vom Use-Case und der Kalibrierungs-Qualität. PyMC Labs dokumentiert 90 Prozent Alignment in kalibrierten Personal-Care-Studien.[3] Bei sensiblen Themen brechen die Werte ein.[6]
Welche Tools sind für AI-Segmentierung 2026 relevant?
Qualtrics XM mit AI-Segmenten, Ipsos SLICE und Connected Segmentation, SKIM mit Latent Class Analysis, Statistical Innovations Latent Gold. Für synthetische Datenbasen: neuroflash Digital Twins (DACH), PyMC Labs (US), GWI Edge.
Wann ist klassische Segmentierung weiter Pflicht?
Bei regulierten Industrien (Pharma, Finanz), bei langfristigen strategischen Entscheidungen mit hohem Investment, bei Compliance-Reports und bei sensiblen Themen, in denen LLM-Bias die Validität gefährdet.[6]
Wie viel kostet AI-basierte Segmentierung im Vergleich?
Klassische Custom-Segmentierung: 50.000 bis 150.000 Euro pro Studie.[2] AI-Plattformen mit synthetischer Datenbasis: 5.000 bis 30.000 Euro pro Jahr für unbegrenzte Studien. Kosten-Faktor 5 bis 30 Mal niedriger.[4]
Welche Sample-Größen sind 2026 üblich?
Klassisch: 200 bis 400 Befragte pro Cluster, 1.500 bis 3.000 pro Gesamtstudie. Synthetisch: 1.000 bis 10.000 pro Cluster, 10.000 bis 100.000 pro Gesamtstudie. Sub-Segment-Tiefe steigt dramatisch.
Was ist der Branchen-Konsens 2026?
Hybrid statt rein synthetisch oder rein klassisch. Klassische Basis-Segmentierung als methodischer Anker, synthetische Sub-Segmentierung und Iteration zwischen klassischen Wellen, Live-Validierung in Pilot-Kampagnen.[7][8][10]
Fazit:
Segmentierung mit synthetischen Daten ist 2026 von der akademischen Diskussion zur produktiven Praxis geworden. Die methodischen Algorithmen (K-Means, LCA, Neural Embeddings) bleiben gleich, die Datenbasis wird dramatisch günstiger, schneller und tiefer. Validität reicht von 65 bis 95 Prozent gegenüber Realbefragungen, mit klaren Use-Case-Limits bei sensiblen Themen, Long-Tail-Demografien und sensorischen Insights.
Der pragmatische Weg ist hybrid: Klassische Basis-Segmentierung als Anker, synthetische Sub-Segmentierung und Iteration für Geschwindigkeit, Live-Validierung in Pilot-Kampagnen für Verbindung zur Marktrealität. Wer diese Architektur sauber baut, gewinnt Geschwindigkeit, Kostenvorteile und Sub-Segment-Tiefe, ohne methodische Glaubwürdigkeit zu verlieren.
Quellenverzeichnis
[1] Qualtrics (2024): „Cluster Analysis: Definition and Examples.“ https://www.qualtrics.com/articles/strategy-research/analyse-cluster/
[2] Ipsos: „Segmentation Methodology Guide.“ https://www.ipsos.com/sites/default/files/publication/1970-01/MediaCT_BiteSizedWhitePaper_Segmentation_Web.pdf
[3] PyMC Labs (2025): „Synthetic Consumers: A Practical Guide.“ https://www.pymc-labs.com/blog-posts/synthetic-consumers-a-practical-guide
[4] neuroflash (2026): „Datenquellen & Modellierung in KI-Marktforschung.“ https://neuroflash.com/de/blog/validierung/datenquellen-digital-twins/
[5] SINUS-Institut (2025): „Sinus-Milieus.“ https://www.sinus-institut.de/en/sinus-milieus
[6] Marktforschung.de (2025): „Synthetische Daten im Praxistest, Methode mit Zukunft oder überschätzt?“ https://www.marktforschung.de/marktforschung/a/synthetische-daten-im-praxistest-methode-mit-zukunft-oder-ueberschaetzt/
[7] HSLU IKM (2025): „Synthetische Daten, echte Fragen: Wie KI die Marktforschung verändert.“ https://hub.hslu.ch/ikm/2025/11/11/synthetische-daten-echte-fragen-wie-ki-die-marktforschung-veraendert/
[8] Qualtrics (2024): „Synthetic Data Validation: Methods & Best Practices.“ https://www.qualtrics.com/articles/strategy-research/synthetic-data-validation/
[9] Springer (2024): „Deep Embedding Clustering Based on Residual Autoencoder.“ https://link.springer.com/article/10.1007/s11063-024-11586-0
[10] ESOMAR Congress (2024): „Synthetic Data in Marketing Studies.“ https://ana.esomar.org/api/public/document/file_renderer/12519