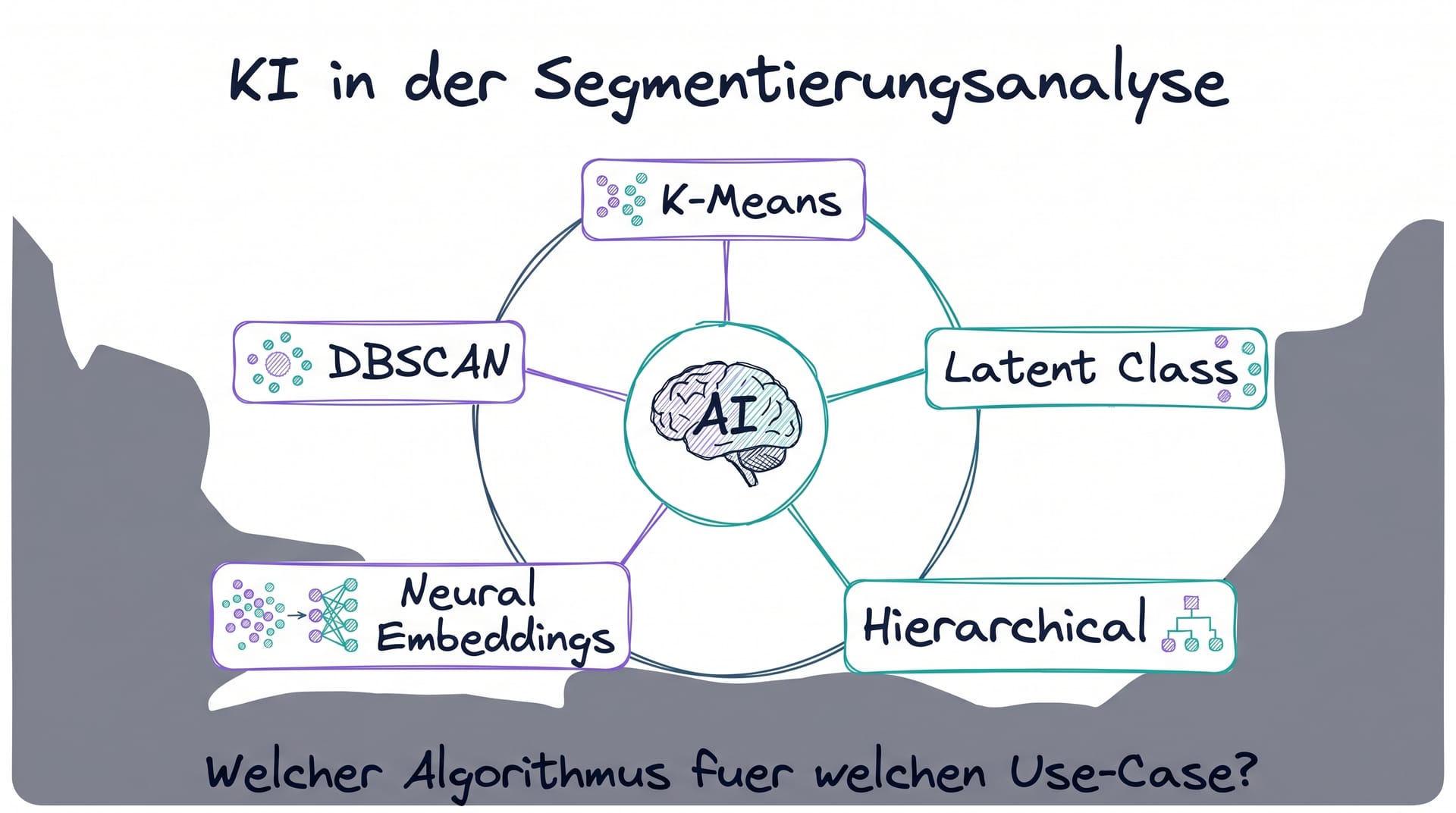
Wer 2026 Marktsegmentierung mit KI machen will, muss zuerst die Algorithmen-Frage klären. K-Means, Latent Class Analysis, Hierarchical Clustering, Neural Embeddings und DBSCAN sind die fünf Schulen, die heute den Markt prägen. Jede hat ihre methodischen Stärken und ihre typischen Anwendungsfälle. Wer den falschen Algorithmus für seinen Use-Case wählt, bekommt schlechte Cluster, die zwar mathematisch korrekt aussehen, aber operativ wertlos sind.
Dieser Artikel liefert die kompakte Übersicht über die fünf Algorithmen, den 7-Schritte-Workflow für KI-basierte Segmentierungs-Studien und die Tool-Landschaft 2026.
Dieser Artikel ist Teil unseres Pillars Segmentierung mit synthetischen Daten: Methodik und Anwendung.
5 Algorithmen-Schulen im Vergleich
K-Means. Der Klassiker. Findet runde Cluster gleicher Größe, ist schnell und skalierbar. Analytics India Mag dokumentiert in einer Vergleichsstudie zu Customer-Segmentation-Datensätzen: Silhouette-Score 0.29 für K-Means.[3] Datasolut beschreibt K-Means als den DACH-Standard für Erst-Segmentierungen.[1]
Stärken: Schnell, skalierbar auf Millionen-Datensätze, einfach zu interpretieren.
Schwächen: Findet nur runde Cluster, sensibel gegenüber Ausreißern, Anzahl Cluster muss vorab gesetzt werden.
Use-Case: Erste Segmentierung, Customer Lifetime Value Cluster, Demografie-basierte Segmente.
Hierarchical Clustering. Liefert eine Hierarchie von Clustern (Dendrogramm), interpretierbar, gut für kleinere Datensätze. Vergleichsstudie zeigt Silhouette 0.25.[3]
Stärken: Visuell intuitiv (Dendrogramm), gute Interpretierbarkeit, Anzahl Cluster muss nicht vorab gesetzt werden.
Schwächen: Schlechtere Performance bei großen Datensätzen, rechenintensiv ab n=10.000.
Use-Case: Premium-Segmentierungen mit qualitativem Fokus, kleinere B2B-Studien.
Latent Class Analysis (LCA). Probabilistisches Modell, jedem Respondenten werden Wahrscheinlichkeiten für Cluster-Zugehörigkeit zugeordnet. SKIM nutzt LCA als methodische Standard-Methode für Segmentierungs-Studien.[4] Statistical Innovations bietet mit Latent Gold das Industrie-Standard-Tool.[5]
Stärken: Probabilistisch und damit statistisch robust, ideal für kategoriale Variablen, dokumentierte Validität.
Schwächen: Erfordert statistische Expertise, höhere Komplexität als K-Means.
Use-Case: Attitude-basierte Segmentierungen, Healthcare, klassische Marktforschung mit hohem methodischen Anspruch.
Neural Embedding Clustering. Nutzt Deep-Learning-Modelle (BERT, Autoencoder) zur Projektion von Konsumenten-Daten in hochdimensionale Vektor-Räume. Springer-Paper aus 2024 und 2025 dokumentieren Deep Embedding Clustering und Customer2Vec-Frameworks als State-of-the-Art.[10][11]
Stärken: Hochdimensionale, nicht-lineare Strukturen, ideal für Big-Data-Segmentierung mit Textdaten oder Verhaltensdaten.
Schwächen: Schwierig zu interpretieren (Black-Box), erfordert ML-Engineering-Kompetenz.
Use-Case: E-Commerce-Verhaltens-Segmentierung, NLP-basierte Konsumenten-Segmente.
DBSCAN und dichtebasierte Methoden. Findet Cluster beliebiger Form, ist tolerant gegenüber Ausreißern.
Stärken: Beliebige Cluster-Formen, automatische Ausreißer-Identifikation, keine vorgegebene Cluster-Anzahl.
Schwächen: Sensibel gegenüber Parameter-Wahl, Performance-Probleme bei hochdimensionalen Daten.
Use-Case: Geo-räumliche Segmentierung, Anomalie-Erkennung in Konsumenten-Daten.

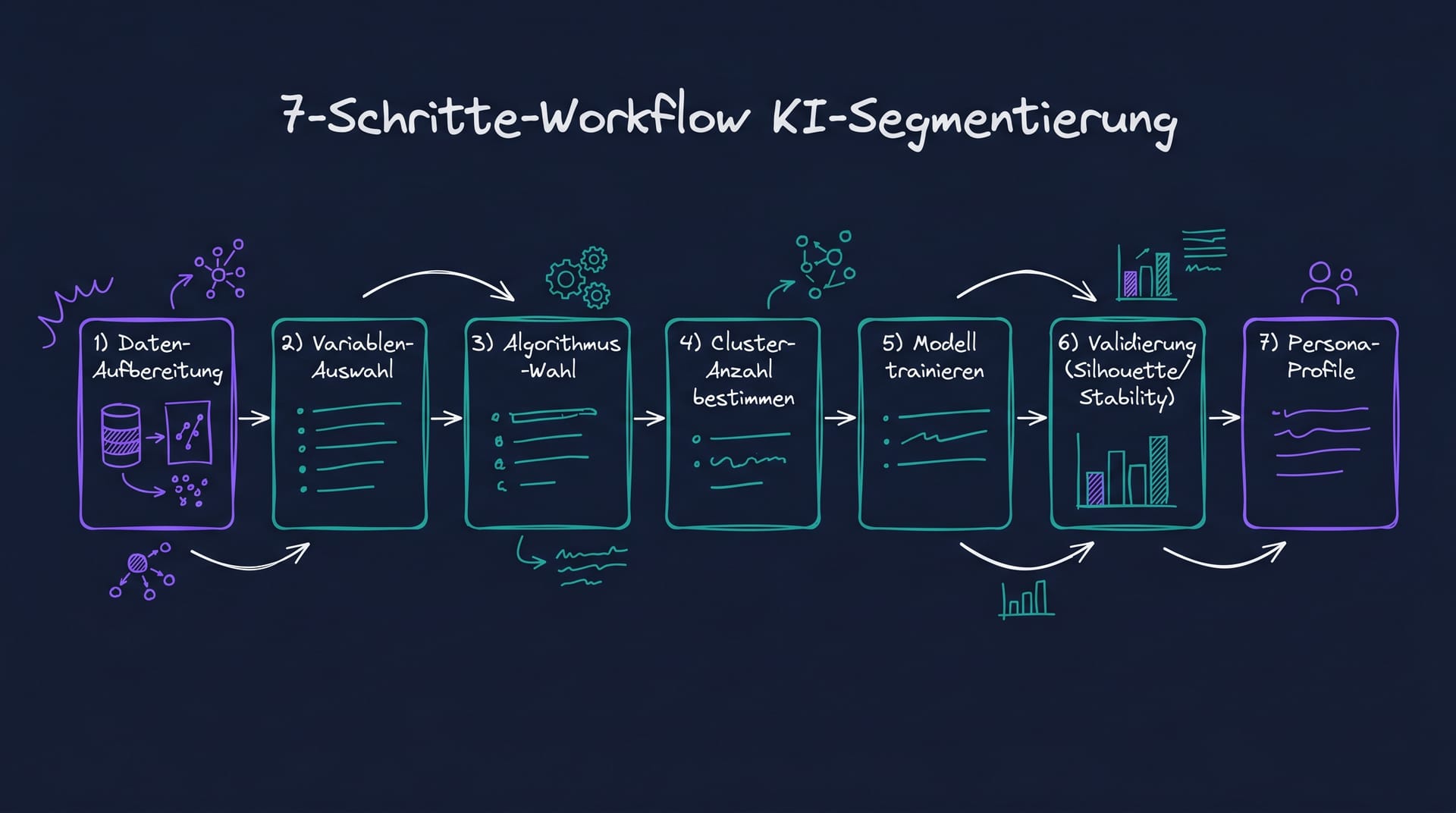
Der 7-Schritte-Workflow für KI-Segmentierung
Ein produktiver Workflow folgt sieben Schritten.
Schritt 1: Daten-Aufbereitung. Roh-Daten aus Surveys, CRM, Behavior-Logs werden bereinigt, normalisiert und auf fehlende Werte geprüft. Adobe Business dokumentiert das als methodischen Grundbaustein.[2]
Schritt 2: Variablen-Auswahl. Welche Variablen sollen die Segmentierung tragen? Demografie, Psychografie, Verhalten, Attitude. Die Variablen-Wahl bestimmt die Cluster-Logik mehr als der Algorithmus.
Schritt 3: Algorithmus-Wahl. Je nach Use-Case einer der fünf Schulen (siehe oben).
Schritt 4: Cluster-Anzahl bestimmen. Elbow-Method, Silhouette-Analysis, Information-Kriterien (BIC, AIC) für LCA. Faustregel: 4 bis 7 Cluster für strategische Segmentierungen, 8 bis 12 für taktische.
Schritt 5: Modell trainieren. Algorithmus auf die Daten anwenden, mehrere Startpunkte ausprobieren (besonders bei K-Means), Modell-Konvergenz prüfen.
Schritt 6: Validierung. Silhouette-Score, Stability-Tests (Bootstrap-Resampling), Konvergenz-Validierung gegen externe Variablen. Wenn die Validierung schwach ausfällt, zurück zu Schritt 2 oder 3.
Schritt 7: Persona-Profile erstellen. Die statistischen Cluster werden in strategisch handhabbare Personas übersetzt, mit Name, Demografie, Mindset, Mediennutzung, Motivationen. Diese Personas sind das, was Marketing-Teams tatsächlich nutzen.
Mehr zur Validität der entstehenden Segmente findest du im Schwester-Cluster.
Tool-Landschaft 2026
Enterprise-Plattformen:
- Qualtrics XM. Nativ integriert in der XM-Plattform mit AI-generierten Auto-Segmenten in XiD.[6]
- Ipsos High Definition Customers und Connected Segmentation. Methodisch tief, multi-dimensional.[7][8]
- SKIM mit Latent Class Analysis. Spezialist für probabilistische Segmentierung.[4]
Spezialisierte Tools:
- Statistical Innovations Latent Gold. Industrie-Standard für LCA.[5]
- R und Python (sklearn, scikit-learn, hclust, K-Means, DBSCAN). Maximum Flexibilität, ML-Engineer-Skill nötig.
Synthetische Datenbasen:
- neuroflash Digital Twins. DACH-Plattform, über eine Million reale Profile als Datenbasis.
- PyMC Labs Synthetic Consumers. US-Fokus, akademisch validiert.
Die Tool-Wahl hängt vom Reifegrad des Insights-Teams ab. Mid-Market-Teams kommen mit Qualtrics oder Ipsos weit, Enterprise-Teams kombinieren Plattform-Tools mit eigenen ML-Stacks.
Mit neuroflash Digital Twins KI-Segmentierung produktiv machen

neuroflash Digital Twins ist die DACH-Plattform für synthetische Datenbasen in KI-Segmentierungs-Workflows. Über eine Million reale Profile, 85 Prozent plus Vorhersagegenauigkeit, Segmentierung in Stunden statt Wochen. Ideal als Sub-Segment-Vertiefung und Iterations-Layer. Jetzt neuroflash testen.
FAQ
Welcher Segmentierungs-Algorithmus passt für meinen Use-Case?
K-Means für schnelle Erst-Segmentierungen, Hierarchical für kleinere qualitative Studien, LCA für methodisch anspruchsvolle Attitude-Segmente, Neural Embeddings für Big-Data und Textdaten, DBSCAN für Geo-Räume und Anomalien.
Welcher Algorithmus hat die höchste Genauigkeit?
Die Genauigkeit hängt vom Datensatz ab, nicht vom Algorithmus an sich. Analytics India Mag dokumentiert für vergleichbare Customer-Segmentation-Datensätze: K-Means Silhouette 0.29, Hierarchical 0.25.[3] LCA und Neural Embeddings können je nach Use-Case höhere Werte erreichen.
Welche Tools sind 2026 Branchenstandard?
Qualtrics XM, Ipsos SLICE und Connected Segmentation, SKIM mit LCA, Statistical Innovations Latent Gold. Für synthetische Datenbasen: neuroflash Digital Twins (DACH).[6][7][5]
Wie viele Cluster sollten Segmentierungen haben?
Faustregel: 4 bis 7 für strategische Segmentierungen (Marken-Positionierung, Portfolio-Strategie), 8 bis 12 für taktische (Kampagnen-Targeting, Personalisierung).
Wie validiere ich AI-Segmente?
Silhouette-Score und Stability-Tests als statistische Basis. Konvergenz-Validierung gegen externe Variablen (Sales-Daten, Behavioral-Daten). Live-Pilot in Marketing-Kampagnen als finale Validierung.
Was kostet KI-Segmentierungs-Tooling?
Qualtrics XM und Ipsos im Custom-Bereich (50.000 plus Euro pro Jahr für Enterprise). Synthetische Datenbasen wie neuroflash Digital Twins ab 5.000 Euro pro Jahr. Open-Source mit R/Python kostenlos, aber ML-Engineering-Aufwand.
Fazit:
KI in der Segmentierungsanalyse ist 2026 nicht mehr die Frage des Ob, sondern des Wie. Die fünf Algorithmen-Schulen (K-Means, Hierarchical, LCA, Neural Embeddings, DBSCAN) decken jeden Use-Case ab, der 7-Schritte-Workflow ist Industrie-Standard, die Tool-Landschaft ist marktreif. Was Insights-Teams 2026 unterscheidet, ist die methodische Disziplin: Wer den Algorithmus zum Use-Case passend wählt, sauber validiert und die Personas operativ übersetzt, baut Segmentierungen, die tatsächlich Wert schaffen.
Wer KI nur als Marketing-Buzzword einsetzt und Algorithmen ohne Validierung anwendet, baut Cluster, die statistisch existieren, aber operativ wertlos sind. Der methodische Anspruch bleibt 2026 hoch, auch wenn die Tools effizienter werden.
Quellenverzeichnis
[1] Datasolut (2025): „Kundensegmentierung mit K-Means.“ https://datasolut.com/clusteranalyse-kundensegmentierung-beispiel/
[2] Adobe Business (2025): „Was sind Cluster-Analysen im Marketing?“ https://business.adobe.com/de/blog/basics/cluster-analysis
[3] Analytics India Mag: „Comparison Of K-Means and Hierarchical Clustering In Customer Segmentation.“ https://analyticsindiamag.com/deep-tech/comparison-of-k-means-hierarchical-clustering-in-customer-segmentation/
[4] SKIM (2025): „Latent Class Analysis (LCA).“ https://skimgroup.com/methodologies/segmentation-analysis/latent-class-analysis-lca/
[5] Statistical Innovations (2025): „About Latent Class Analysis.“ https://www.statisticalinnovations.com/about-latent-class-analysis/
[6] Qualtrics (2024): „X4 2024 New XM Innovations.“ https://www.qualtrics.com/articles/news/x4-2024-new-innovations-xm/
[7] Ipsos: „High Definition Customers, Powerful Segmentation.“ https://www.ipsos.com/en/high-definition-customers-powerful-segmentation
[8] Ipsos (2020): „Connected Segmentation.“ https://www.ipsos.com/sites/default/files/ct/publication/documents/2020-04/ipsos_connected_segmentation_-_april_2020.pdf
[9] ScienceDirect (2025): „NLP-driven customer segmentation.“ https://www.sciencedirect.com/science/article/pii/S2666764925000463
[10] arXiv: „Intelligent Vector-based Customer Segmentation in the Banking Industry.“ https://arxiv.org/pdf/2012.11876
[11] Springer (2025): „Enhancing Customer Segmentation with Unsupervised Deep Learning.“ https://link.springer.com/chapter/10.1007/978-3-031-88304-0_1