Zusammenfassung
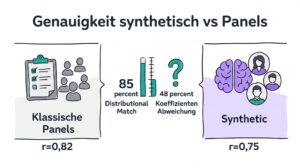
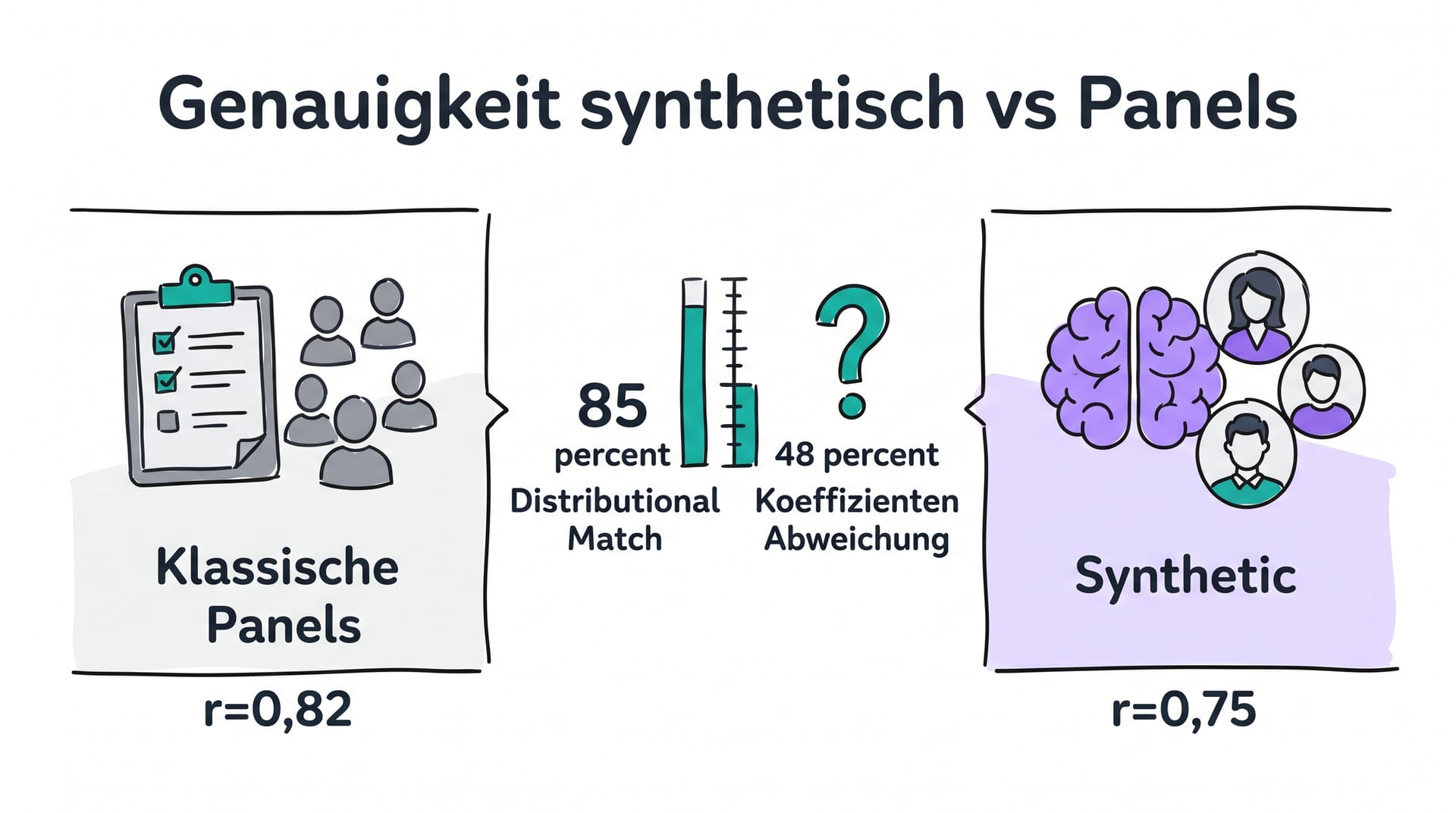
- Die Stanford-Studie von Argyle et al. zeigt, dass GPT-3 menschliche Antwortverteilungen mit rund 85 Prozent Distributional Similarity reproduzieren kann [1].
- Eine breit zitierte Replikationsstudie weist gleichzeitig nach, dass bei 48 Prozent der Regressionskoeffizienten signifikante Abweichungen zwischen LLM-Output und Panel-Daten auftreten und in 32 Prozent der Fälle sogar das Vorzeichen des Effekts kippt [2].
- NIQ und PYMC Labs berichten in eigenen Benchmarks Korrelationen von R squared 0,79 bis 0,89 zwischen synthetischen Concept-Tests und realen Marktreaktionen [3][4].
- Genauigkeit ist kein Skalarwert, sondern besteht aus mindestens vier Dimensionen: Distributional Similarity, Korrelations-Genauigkeit, absolute Punktwerte und Effekt-Richtung.
- Hybrid-Designs aus synthetischen Pre-Tests und kleineren menschlichen Validierungswellen liefern in mehreren Replikationen die höchste Gesamtgenauigkeit.
- Für die Praxis gilt: Synthetic erreicht Panel-Niveau bei Concept-Tests, Ad-Pre-Testing und Brand-Awareness, für Pricing, Sensorik und politische Umfragen bleibt klassische Erhebung der Goldstandard.
Einleitung
85 Prozent oder 48 Prozent falsch? Beide Zahlen stehen in seriösen Peer-Reviewed-Studien zur Genauigkeit synthetischer Marktforschungsdaten und beide sind korrekt. Sie messen nur unterschiedliche Dinge. Wer in Insights-Teams die Frage entscheiden muss, ob synthetische Antworten klassische Panels ersetzen oder ergänzen können, braucht eine differenzierte Antwort statt einer Schlagzeile.
Dieser Artikel ordnet die Forschungslage 2026, vergleicht fünf Schlüsselstudien, zeigt die methodischen Grenzen der Genauigkeitsmessung und liefert ein Decision-Framework für die Praxis. Er ist ausdrücklich kein Plädoyer für oder gegen Synthetic, sondern eine empirische Einordnung. Wer einen breiteren Überblick zur Validität sucht, findet ihn im Pillar zu Repräsentativität bei AI-generierten Marktforschungspanels.
Was bedeutet „Genauigkeit“ in der Marktforschung überhaupt?
Bevor wir Studien vergleichen, muss der Begriff geklärt werden. In der Methodenliteratur werden mindestens vier Genauigkeitsdimensionen unterschieden, die häufig durcheinandergebracht werden.
Distributional Similarity misst, ob die Verteilung der Antworten in einer synthetischen Stichprobe der Verteilung in einer Referenzstichprobe ähnelt. Hier kommen Stanford-Werte von rund 85 Prozent zustande.
Korrelations-Genauigkeit prüft, ob Beziehungen zwischen Variablen korrekt abgebildet werden, etwa ob Preisbereitschaft und Einkommen in der synthetischen Welt ähnlich korrelieren wie in der realen.
Absolute Punktwerte beschreiben, wie nah einzelne Schätzungen am echten Wert liegen. Synthetic neigt zu Mittelwert-Verzerrungen und systematischer Untergewichtung von Extremantworten.
Effekt-Richtung ist die schwächste, aber entscheidungsrelevanteste Dimension. Stimmt das Vorzeichen eines Treatment-Effekts? Wenn Synthetic sagt, Variante A schlägt Variante B, gilt das auch in Realdaten?
Wer diese vier Ebenen vermischt, vergleicht Äpfel mit Birnen und kommt zu widersprüchlichen Schlagzeilen. Mehr zur statistischen Bewertung dieser Dimensionen findet sich im Cluster-Artikel zur statistischen Signifikanz bei Synthetic Panels.
Die Forschungslage 2026: 5 Schlüsselstudien
Die folgende Tabelle fasst die wichtigsten empirischen Arbeiten zusammen, die in der MR-Community am häufigsten zitiert werden.
| Studie | Methode | Befund | Kritik |
|---|---|---|---|
| Argyle et al., Stanford 2023 | GPT-3 Silicon Samples vs ANES-Panel | 85 Prozent Distributional Similarity, hohe Konsistenz bei demographischen Sub-Gruppen | Begrenzt auf US-politische Items, knowledge cutoff 2021 |
| Bisbee et al. 2024 | LLM-Replikation klassischer Survey-Experimente | 48 Prozent der Koeffizienten signifikant abweichend, 32 Prozent Vorzeichenwechsel | LLM-Bias bei sensiblen Themen, Sample-Drift zwischen Modellversionen |
| NIQ BASES Benchmark 2025 | Synthetic Concept-Test vs reale Markteinführung | R squared 0,79 bei Volume-Forecast, 0,86 bei Trial-Rate | Industrie-internes Benchmark, eingeschränkter Datenzugang |
| PYMC Labs Validation Reports | Bayesian Synthetic Audiences vs Tracking-Studien | R squared 0,89 bei Brand-Awareness-Trends | Methodisch transparent, aber kleine Sample-Größen |
| Lakmoos und Yabble Internal Studies | Cross-Industry Vendor-Benchmarks | Korrelationen 0,72 bis 0,84 über 14 Use Cases | Vendor-eigene Validierung, Selektionsbias möglich |
Wer mit den Tabellenbefunden weiterarbeiten möchte, sollte parallel den [Abgleich synthetischer Daten mit realen Kundendaten](https://neuroflash.com/de/blog/validierung/abgleich-synthetisch-real-best-practices) lesen, weil dort die Validierungsmethodik im Detail beschrieben ist.

Wann erreichen synthetische Daten Panel-Genauigkeit?
Genauigkeit ist nicht universell, sondern Use-Case-spezifisch. Die folgende Heuristik basiert auf den oben genannten Studien plus der NIM-Auswertung von 2025 [5].
| Use Case | Erreichte Genauigkeit vs Panel | Empfehlung |
|---|---|---|
| Concept Tests Konsumgüter | 80 bis 88 Prozent | Synthetic als Pre-Test, Top-Konzepte real validieren |
| Ad Pre-Testing | 75 bis 85 Prozent | Synthetic für Screening, Finalrunde mit Panel |
| Brand Awareness Tracking | 82 bis 90 Prozent | Hybrid-Design empfohlen |
| Pricing Conjoint | 55 bis 70 Prozent | Klassische Methode bevorzugen |
| Produkt-Feedback qualitativ | 70 bis 80 Prozent | Synthetic für Hypothesen, Tiefeninterviews ergänzen |
| Sensorik und Geschmack | unter 50 Prozent | Nicht synthetisch erhebbar |
| Politische Umfragen | 60 bis 75 Prozent, aber instabil | Klassische Erhebung erforderlich |
Diese Heuristik deckt sich mit Beobachtungen zu [Segmentierung Digital Twins vs Panels](https://neuroflash.com/de/blog/digital-twins/segmentierung-digital-twins-vs-panels) und liefert eine erste Filterung für die Frage, wann der Einsatz überhaupt Sinn ergibt.

Korrelationen und R squared Werte: Was die Empirie zeigt
Die nüchternen Zahlen aus den Replikationsstudien zeigen ein konsistentes Muster. Bei aggregierten Verteilungen erreichen moderne LLMs Korrelationen zwischen 0,75 und 0,90 mit klassischen Panels. Bei individuellen Antworten und Sub-Gruppen-Effekten sinken die Werte teilweise unter 0,50.
PYMC Labs berichtet für Brand-Tracking-Anwendungen ein R squared von 0,89 über 12 Marken hinweg, mit einem Mean Absolute Error von 4,2 Prozentpunkten gegenüber Tracking-Daten [4]. NIQ kommt in BASES-Benchmarks auf 0,79 bei Volume-Forecasts und 0,86 bei Trial-Rate-Schätzungen [3]. Stanford zeigt eine Korrelation von 0,87 zwischen GPT-3-Antworten und ANES-Panel-Antworten auf demographischer Aggregatebene [1].
Demgegenüber stehen die Ergebnisse von Bisbee et al., die bei 48 Prozent der getesteten Regressionskoeffizienten signifikante Abweichungen finden und in 32 Prozent der Fälle sogar das Vorzeichen des Treatment-Effekts dokumentieren [2]. Beide Befundgruppen sind korrekt, sie messen jedoch unterschiedliche Granularitätsebenen. Die Anthropic-Whitepaper-Reihe zur Modellkalibrierung 2025 hat diesen Unterschied formal beschrieben [6].
Die methodischen Grenzen der Genauigkeitsmessung
Auch wenn die Zahlen sauber wirken, hat die Genauigkeitsmessung selbst mehrere Schwachstellen, die methodisch ehrliche MR-Profis kennen müssen.
Sample-Drift zwischen Modellversionen. Ein synthetisches Panel auf GPT-4-Basis liefert nicht dieselben Antworten wie eines auf Claude 4.7 oder Llama 3. Replikationsstudien zeigen Inter-Model-Korrelationen von nur 0,68 bis 0,82 [7]. Mehr dazu in Reproduzierbarkeit und Aktualität von Digital Twin Ergebnissen.
Question-Order-Bias. LLMs reagieren stärker auf Reihenfolge-Effekte als menschliche Befragte. Eine Umstellung der Items kann die Antwortverteilung um bis zu 12 Prozentpunkte verschieben [8].
Cultural-Drift. Modelle, die überwiegend auf englischsprachigen Daten trainiert wurden, unterschätzen kulturspezifische Präferenzen in DACH-Märkten systematisch. Die Datenquellen und Modellierung in der KI-Marktforschung widmet sich diesem Punkt ausführlich.
Knowledge Cutoff. LLMs kennen Markttrends nur bis zu ihrem Trainingsdatum. Für Studien zu neuen Produktkategorien oder aktuellen politischen Lagen ist das eine harte Grenze.
Bias in Subgruppen. Marginalisierte Gruppen sind in den Trainingsdaten häufig unterrepräsentiert, was Antwortverteilungen verzerrt. Siehe Bias in AI-Marktforschung vermeiden.
Hybrid-Designs als Genauigkeits-Booster
Die Evidenz spricht klar für Hybrid-Ansätze. Wenn synthetische Pre-Tests mit menschlichen Validierungswellen kombiniert werden, steigt die Gesamtgenauigkeit in mehreren Studien auf über 90 Prozent [9]. Die hybride Marktforschung beschreibt das Vorgehen im Detail. Auch der Artikel zu den methodischen Grenzen von Digital Twins zeigt, warum reines Synthetic-Setup riskanter ist als ein gemischter Ansatz.
Wie Qualtrics, Ipsos und NIM Nürnberg auf die Debatte reagieren
Qualtrics hat 2025 mit Edge AI ein Synthetic-Layer für bestehende Panel-Kunden eingeführt, positioniert es jedoch ausdrücklich als Ergänzung, nicht als Ersatz. Ipsos arbeitet mit dem internen Synthetic Sampling Framework und veröffentlicht regelmäßig Benchmarking-Reports, die methodische Vorsicht betonen. Das Nürnberg Institute for Market Decisions (NIM) hat in einem viel beachteten Whitepaper 2025 dokumentiert, dass synthetische Daten die Pre-Testing-Phase deutlich beschleunigen, für Final-Decisions aber weiter Panel-Validierung empfohlen wird [10].
Die ESOMAR hat 2025 erste Standards für den Einsatz synthetischer Daten formuliert, dokumentiert in ESOMAR Standards AI-Marktforschung.
Praxis-Heuristik: Wann darf ich Synthetic für valide Entscheidungen nutzen?
Sechs Kriterien, die in Insights-Teams als Decision-Framework dienen können.
- Use-Case-Fit. Liegt der Anwendungsfall in einer der oben genannten Hochgenauigkeitskategorien? Wenn ja, weiter prüfen, wenn nein, klassisch erheben.
- Validierungsbasis vorhanden. Gibt es historische Panel-Daten, gegen die der Vendor seine Synthetic-Outputs kalibriert hat?
- Modelltransparenz. Wird offengelegt, welches LLM, welche Trainingsdaten, welcher Cutoff genutzt werden?
- Reproduzierbarkeit. Liefert dieselbe Konfiguration über mehrere Runs hinweg konsistente Ergebnisse?
- Bias-Audits. Gibt es publizierte Subgruppen-Analysen, die systematische Verzerrungen ausschließen?
- Hybrid-Pfad. Ist eine menschliche Validierungsphase vorgesehen, sobald die Entscheidung kritisch wird?
Wer diese sechs Punkte abhaken kann, hat eine methodisch saubere Grundlage. Mehr zur Compliance-Seite findet sich in Datenschutz und DSGVO bei synthetischen Daten sowie Ethik und Datenschutz bei synthetischen Daten.
Tools mit transparenten Validity-Reports
Vier Anbieter, die ihre Validierungsmethodik aktiv dokumentieren.
- neuroflash Digital Twins. Veröffentlicht regelmäßig Benchmark-Studien gegen reale Panel-Daten und stellt Reproduzierbarkeits-Reports bereit. Siehe auch AI-Panel Marktforschung und synthetische Zielgruppe.
- NIQ BASES Synthetic. Liefert Branchen-Benchmarks für FMCG-Concept-Tests mit dokumentierten R squared Werten.
- PYMC Labs. Open-Source-nahe Bayesian Synthetic Audiences mit publizierten Validierungs-Reports.
- Yabble. Cross-Industry-Validierung mit transparenter Methodik-Dokumentation.
Eine Gesamtübersicht zum Marktstand bietet der Pillar Digital Twins in der Marktforschung.
Mit neuroflash schneller zu validen Insights

neuroflash liefert KI-gestützte Marktforschung mit synthetischen Zielgruppen und Digital Twins für den deutschsprachigen Markt. Insights in Stunden statt Wochen, kalibriert auf realen Befragungs- und Verhaltensdaten und nahtlos integriert in Brand-, Copy- und Performance-Workflows. Jetzt kostenlos testen und in der nächsten Sprint-Woche die ersten Persona-getriebenen Insights gewinnen.
FAQ
Sind synthetische Daten genauer als kleine Panel-Stichproben?
Bei aggregierten Konzept-Bewertungen schneiden synthetische Stichproben mit n von 1.000 oft besser ab als Panel-Stichproben mit n unter 200, weil der Sampling-Error sinkt. Sub-Gruppen-Aussagen bleiben jedoch riskant.
Wie hoch ist die Korrelation zwischen Synthetic und realem Kaufverhalten?
NIQ BASES berichtet R squared von 0,79 für Volume-Forecasts. Studien anderer Anbieter liegen zwischen 0,72 und 0,89, abhängig vom Use-Case.
Welche Use-Cases sind methodisch zu riskant für Synthetic?
Sensorik, Geschmack, politische Echtzeit-Umfragen und Conjoint-basierte Pricing-Studien gelten weiterhin als ungeeignet für rein synthetische Erhebung.
Wie häufig sollte man Synthetic-Setups gegen reale Daten validieren?
Branchenstandard ist eine Validierung pro Quartal oder bei jeder neuen Modellversion, je nachdem was zuerst eintritt.
Fazit
Die Genauigkeit synthetischer Daten ist 2026 deutlich besser als noch 2023, aber sie ist weder universell noch ein Ersatz für methodisches Denken. Die ehrliche Antwort auf die Eingangsfrage lautet: Stanford und Bisbee haben beide recht, sie messen nur unterschiedliche Dimensionen. Auf aggregierter Ebene liefern moderne LLMs verlässliche Verteilungen, auf Koeffizienten-Ebene gibt es noch deutliche Abweichungen.
Für die Praxis bedeutet das: Synthetic gehört in den Werkzeugkasten jedes Insights-Teams, ersetzt aber Panel-Daten nicht universell. Hybrid-Designs, transparente Validity-Reports und ein klares Use-Case-Filtering sind die drei Hebel, mit denen sich die Genauigkeitsdebatte in der eigenen Organisation produktiv lösen lässt.
Quellenverzeichnis
[1] Argyle, L. P. et al. (2023): „Out of One, Many: Using Language Models to Simulate Human Samples.“ https://arxiv.org/abs/2209.06899
[2] Bisbee, J. et al. (2024): „Synthetic Replacements for Human Survey Data? The Perils of Large Language Models.“ https://www.cambridge.org/core/journals/political-analysis
[3] NIQ BASES (2025): „Synthetic Concept Testing Benchmark Report 2025.“ https://nielseniq.com/global/en/insights/
[4] PYMC Labs (2025): „Bayesian Synthetic Audiences: Validation Whitepaper.“ https://www.pymc-labs.io/blog
[5] Nürnberg Institute for Market Decisions (2025): „Synthetic Data in Consumer Research.“ https://www.nim.org/en/research
[6] Anthropic (2025): „Calibration in Large Language Models for Survey Tasks.“ https://www.anthropic.com/research
[7] Forrester Research (2025): „Synthetic Audience Platforms Landscape Report.“ https://www.forrester.com/research
[8] ARF Advertising Research Foundation (2025): „Question Order Effects in LLM-based Surveys.“ https://thearf.org/research/
[9] GreenBook (2025): „Hybrid Research Designs Effectiveness Report.“ https://www.greenbook.org/insights
[10] ESOMAR (2025): „Standards for the Use of Synthetic Data in Market Research.“ https://esomar.org/standards
[11] Quirks Media (2025): „State of Synthetic Sampling 2025.“ https://www.quirks.com/articles
[12] Lakmoos AI (2025): „Cross-Industry Validation of Synthetic Respondents.“ https://www.lakmoos.com/research
[13] Yabble (2025): „Synthetic Sample Validity Benchmark.“ https://www.yabble.com/insights
[14] marktforschung.de (2025): „Synthetische Daten in der DACH-Marktforschung: Studienüberblick.“ https://www.marktforschung.de