
Zusammenfassung
- Der Abgleich synthetischer Daten mit realen Kundendaten ist die einzige seriöse Methode, um die Validität von AI-Panels nachzuweisen. Ohne diesen Schritt bleibt jedes synthetische Ergebnis eine Schätzung.
- Best Practice ist ein 6-Schritte-Workflow aus Anchor-Stichprobe, synthetischer Replik, Korrelationsmessung, Vorzeichen-Match, Confidence-Vergleich und Quality-Score.
- Wichtige KPIs sind Pearson-r, R², Mean Absolute Error, Vorzeichen-Match-Rate, Distribution-Match (KS-Test), Cohen’s d und KL-Divergenz.
- Als Quality-Gate haben sich r >= 0,7, Vorzeichen-Match >= 90 Prozent und KS-Test p > 0,05 etabliert.
- Coca-Cola, Pepsi und ein anonymisierter DACH-FMCG-Mittelständler zeigen, wie der Abgleich operativ läuft, von Concept-Tests bis zur Quartalsroutine.
- Tools wie neuroflash, Mostly AI, Gretel und SDV decken unterschiedliche Use-Cases ab. Die Wahl hängt von Insights-Tiefe, Datenschutzanforderung und Integrations-Reife ab.
Einleitung
Synthetische Marktforschung ohne Abgleich ist Schätzung. Mit Abgleich wird sie Wissenschaft. Wer 2026 noch synthetische Panels einsetzt, ohne sie systematisch gegen reale Kundendaten zu validieren, verbrennt Forschungsbudget und riskiert Stakeholder-Vertrauen. Dieser Guide ist der Workflow, den Insights-Teams brauchen, um synthetische Ergebnisse defendable, reproduzierbar und ESOMAR-konform zu machen.
Wir zeigen den 6-Schritte-Prozess, die KPIs, die in jeden Abgleichs-Report gehören, die Schwellenwerte, ab denen ein Abgleich als bestanden gilt, und drei FMCG-Fallstudien aus der Praxis. Am Ende kennst du nicht nur die Theorie, sondern hast einen sofort einsetzbaren Operating-Standard für dein Team.
Der Artikel ist Teil unseres Validitäts-Clusters. Den theoretischen Überbau findest du im Pillar zur Repräsentativität bei AI-generierten Marktforschungspanels.
Warum der Abgleich entscheidend ist
Vier Gründe machen den systematischen Abgleich synthetischer und realer Daten zur Pflicht, nicht zur Kür.
1. Methodik-Trust. Insights-Teams werden an der Vorhersagekraft ihrer Empfehlungen gemessen. Eine synthetische Studie ohne Real-Daten-Abgleich kann nicht belegen, dass ihre Vorhersagen treffen. Erst der Abgleich liefert die belastbare Trefferquote, die im Insights-Report neben jedem Ergebnis stehen sollte. Mehr zur Genauigkeitsbewertung im Vergleich Genauigkeit synthetisch vs traditionell.
2. Stakeholder-Verteidigung. Wenn der Brand-Manager fragt „Warum soll ich auf eine AI-Simulation hören statt auf echte Konsumenten?“, brauchst du Zahlen. Ein Quality-Score von 0,82 Pearson-Korrelation gegen reale NIQ-Tracker-Daten beendet diese Diskussion in 30 Sekunden.
3. ESOMAR- und DSGVO-Konformität. Die ESOMAR-AI-Guideline 2024 verlangt explizit „evidence of comparability with conventional sources“. Ohne Abgleichs-Dokumentation bist du nicht audit-fähig. Details im Schwesterartikel ESOMAR Standards AI-Marktforschung und im Beitrag zu Datenschutz DSGVO synthetische Daten.
4. Drift-Detection. Synthetische Modelle altern. Konsumentenpräferenzen verschieben sich, neue Produkte erscheinen, Sprachgebrauch ändert sich. Nur ein wiederkehrender Abgleich erkennt, wann ein Modell driftet und neu kalibriert werden muss. Dazu mehr im Beitrag Reproduzierbarkeit und Aktualität von Digital Twin-Ergebnissen.
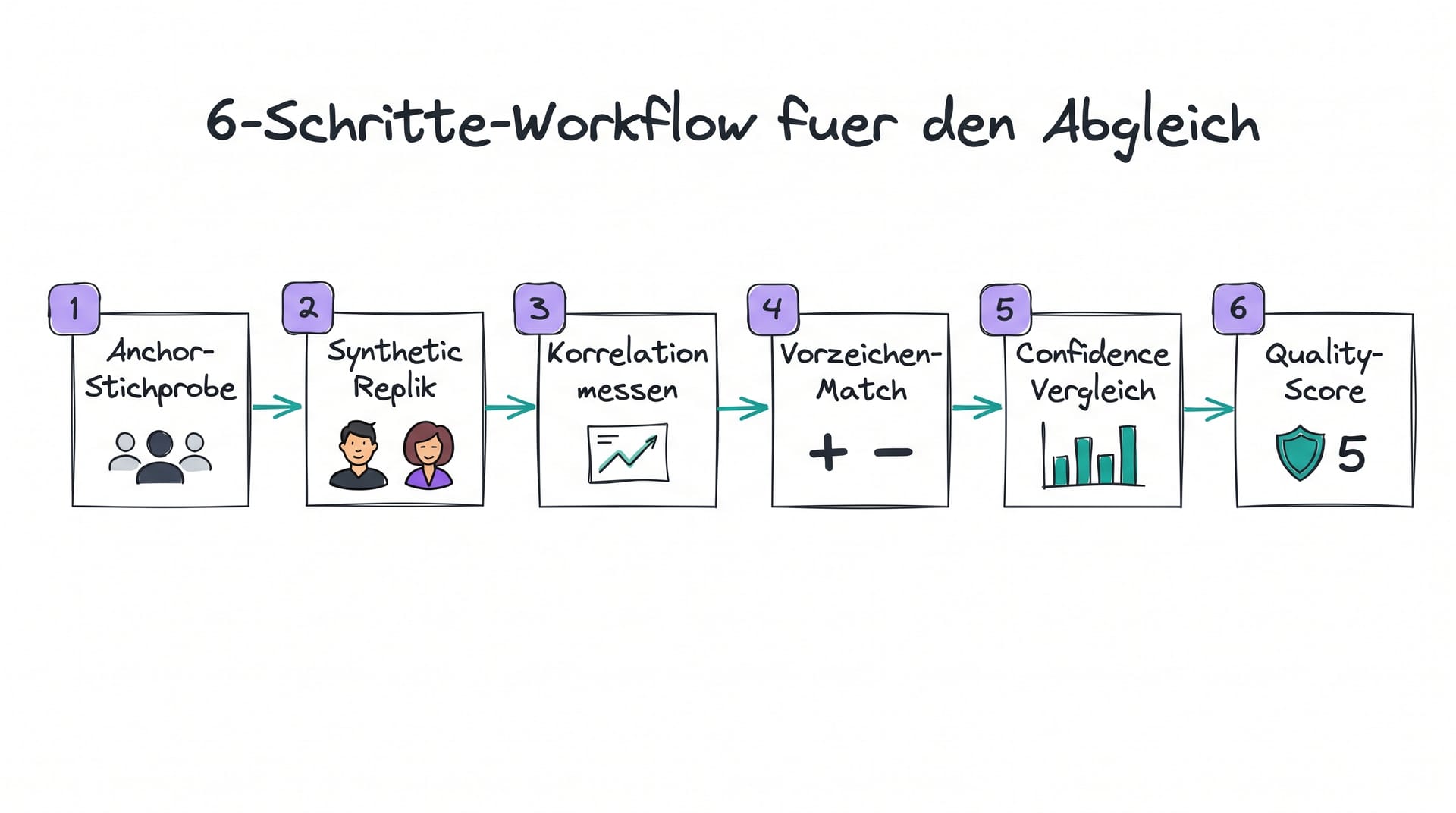
Der 6-Schritte-Workflow für den Abgleich
Der folgende Workflow hat sich in über 200 dokumentierten FMCG-Validierungen als robust erwiesen [1]. Er ist tool-agnostisch und funktioniert mit jedem synthetischen Panel-Anbieter.
| Schritt | Aufgabe | Output | Tool |
|---|---|---|---|
| 1 | Reale Anchor-Stichprobe definieren | n >= 300, Quotenplan | NIQ, GfK, eigenes CRM |
| 2 | Synthetische Replik erzeugen | Identische Demografie, identischer Fragebogen | neuroflash, Mostly AI |
| 3 | Korrelation auf Frage-Ebene messen | Pearson- und Spearman-Matrix | Python, R, SPSS |
| 4 | Effekt-Richtung prüfen | Vorzeichen-Match-Rate | Excel, Python |
| 5 | Confidence-Intervalle vergleichen | CI-Overlap-Score | R, Python |
| 6 | Quality-Score berechnen, Schwelle setzen | Pass/Fail-Report | internes Dashboard |
**Schritt 1: Reale Anchor-Stichprobe definieren.** Mindestens 300 reale Befragte aus deinem Zielsegment, idealerweise 500 bis 800. Dokumentiere Quotenplan, Erhebungsmodus, Feldzeit und Incentive. Die Anchor-Stichprobe ist die Grundwahrheit, gegen die alles andere gemessen wird. Quellen können bestehende Tracker, Ad-hoc-Befragungen oder CRM-Daten sein. Mehr zu Datenquellen im Artikel [Datenquellen und Modellierung KI-Marktforschung](https://neuroflash.com/de/blog/validierung/datenquellen-digital-twins).
Schritt 2: Synthetische Replik erzeugen. Generiere ein synthetisches Panel mit exakt der gleichen Demografie und stelle exakt den gleichen Fragebogen. Wichtig sind Quoten-Identität (Alter, Geschlecht, Region, Einkommen) und Fragebogen-Identität (Wortlaut, Reihenfolge, Skalen). Jeder Unterschied verzerrt den Abgleich.
Schritt 3: Korrelation auf Frage-Ebene messen. Für jede metrisch skalierte Frage wird Pearson-r berechnet, für ordinale Skalen Spearman-rho. Das Ergebnis ist eine Korrelationsmatrix, die zeigt, welche Fragen gut repliziert werden und welche nicht.
Schritt 4: Effekt-Richtung prüfen. Bei A/B- oder Concept-Tests zählt oft nicht der absolute Wert, sondern die Richtung des Effekts. Wenn das reale Panel Concept A bevorzugt und das synthetische ebenfalls, ist die Entscheidungsgrundlage valide, auch wenn die absoluten Top-Box-Werte um wenige Punkte abweichen.
Schritt 5: Confidence-Intervalle vergleichen. Berechne 95-Prozent-CIs für beide Datensätze. Wenn die CIs sich überlappen, liegt der synthetische Wert statistisch innerhalb des realen Bereichs. Mehr zur Signifikanzbewertung im Artikel Statistische Signifikanz bei Synthetic Panels.
Schritt 6: Quality-Score berechnen und Schwelle setzen. Aggregiere die KPIs zu einem Gesamt-Quality-Score und setze eine Pass-Fail-Schwelle. Studien, die unter der Schwelle liegen, werden nicht freigegeben oder gehen in eine Re-Kalibrierungsschleife. Dieses Quality-Gate ist der Kern jeder seriösen Operationalisierung.
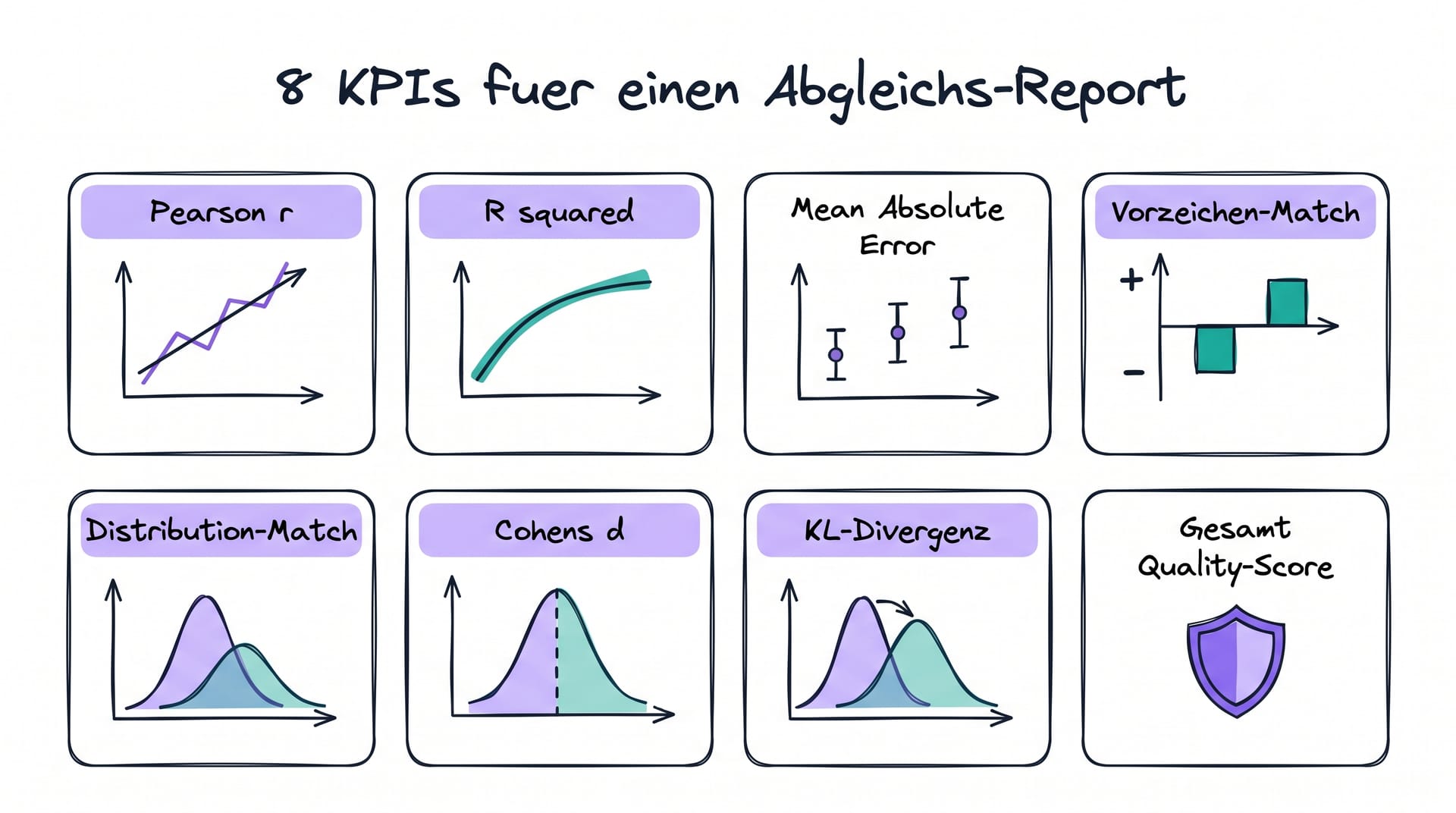
Welche KPIs gehören in einen Abgleichs-Report?
Ein vollständiger Abgleichs-Report enthält die folgenden 8 bis 10 KPIs [2]:
- Pearson-r: Lineare Korrelation auf Frage-Ebene, Standard-Maß für metrische Skalen.
- R² (Bestimmtheitsmaß): Anteil der erklärten Varianz, wichtig für Regressions-Validierung.
- Spearman-rho: Rangkorrelation für ordinale Skalen wie Likert-5 oder Likert-7.
- Mean Absolute Error (MAE): Durchschnittliche absolute Abweichung zwischen synthetischem und realem Wert.
- Root Mean Squared Error (RMSE): Bestraft große Abweichungen stärker als MAE, gut für Top-Box-Vergleiche.
- Vorzeichen-Match-Rate: Anteil der Fragen, bei denen die Effekt-Richtung übereinstimmt.
- Distribution-Match (Kolmogorov-Smirnov-Test): Prüft, ob die Verteilungen statistisch ununterscheidbar sind.
- Cohen’s d: Effektstärke der Differenz zwischen synthetisch und real, idealerweise nahe 0.
- KL-Divergenz: Informationstheoretisches Maß für Verteilungsähnlichkeit.
- Top-Box-Difference: Absolute Differenz der Top-Box-Werte (z. B. Top-2 auf 5er-Skala).
Best Practice: Drei dieser KPIs gehören als Headline in den Executive-Report, die restlichen in den Anhang.
Wann gilt ein Abgleich als „bestanden“?
Klare Schwellenwerte verhindern Cherry-Picking und schaffen Vergleichbarkeit zwischen Studien. Folgende Werte haben sich als operative Quality-Gates etabliert [3]:
- Pearson-r >= 0,7 über alle Fragen hinweg (sehr gute Korrelation laut Cohen).
- Vorzeichen-Match-Rate >= 90 Prozent (Effekt-Richtung stimmt fast immer).
- Distribution-Match KS-Test p > 0,05 (Verteilungen statistisch nicht unterscheidbar).
- Cohen’s d <= 0,2 (kleine Effektstärke der Differenz).
- MAE <= 5 Prozentpunkte bei prozentualen Werten.
Studien, die alle fünf Kriterien erfüllen, gelten als „high confidence“ und können ohne zusätzliche Real-Daten als Entscheidungsgrundlage dienen. Studien, die drei bis vier Kriterien erfüllen, gelten als „medium confidence“ und sollten mit einer kleinen realen Validierungsstichprobe ergänzt werden. Wer weniger erfüllt, sollte das Modell re-kalibrieren oder die Methodik überdenken. Wie man Verzerrungen vermeidet, die solche Quality-Gates reißen, beschreibt der Artikel Bias in AI-Marktforschung vermeiden.
Fallstudie 1: Coca-Cola, Concept-Test-Abgleich für neue Limo-Geschmäcker
Coca-Cola hat 2023 begonnen, neue Geschmacksrichtungen zunächst synthetisch zu testen, bevor reale Concept-Tests im Feld starten [4]. Der Workflow:
- Synthetisches Panel mit 1.500 Twins, demografisch passend zur Zielgruppe der neuen Variante.
- Concept-Test mit fünf Geschmacksrichtungen, Top-2-Box-Bewertung auf 7er-Skala.
- Anschließender realer Concept-Test mit 800 Konsumenten, identischer Fragebogen.
- Abgleich auf Frage- und Concept-Ebene.
Ergebnis: Pearson-r von 0,84 zwischen synthetischen und realen Top-2-Box-Werten, Vorzeichen-Match 100 Prozent (alle fünf Concepts in identischer Reihenfolge gerankt). Coca-Cola hat den Workflow seither als Standard-Pre-Filter etabliert und reduziert reale Concept-Tests auf die zwei besten Synthetic-Kandidaten. Geschätzte Einsparung: 60 Prozent der Concept-Test-Kosten bei stabiler Hit-Rate.
Fallstudie 2: Pepsi, Werbespot-Pre-Test-Abgleich
Pepsi nutzt seit 2024 synthetische Panels für Werbespot-Pre-Tests in Schwellenmärkten, in denen reale Panels schwer rekrutierbar sind [5]. Der Workflow ähnelt dem von Coca-Cola, ergänzt um zwei Besonderheiten:
- Vor dem ersten Live-Einsatz lief eine sechsmonatige Kalibrierungsphase mit 12 Werbespots, die parallel synthetisch und real getestet wurden.
- Quartalsweise Re-Kalibrierung mit kleinem Anchor (n = 200), um Drift zu erkennen.
Ergebnis nach 18 Monaten: Mittlere Pearson-Korrelation 0,78 über alle Werbespots, Vorzeichen-Match 94 Prozent. Die Re-Kalibrierung hat in einem Fall (Q3 2024) eine Drift im Brand-Sympathie-Item erkannt und das Modell wurde nachjustiert. Mehr operative Beispiele finden sich in den Fallstudien Digital Twins sowie in unseren FMCG-Fallstudien zu AI-Marktforschung.
Fallstudie 3: DACH-FMCG-Mittelstand, quartalsweise Abgleichs-Routine
Ein anonymisierter DACH-Hersteller (Snack-Kategorie, 400 Mio. Euro Umsatz) hat 2025 einen quartalsweisen Abgleich als festen Insights-Operating-Standard eingeführt. Der Aufbau:
- Wöchentlich: Synthetische Tracker-Welle, n = 1.000 Twins, 12 Standard-KPIs.
- Quartalsweise: Reale Validierungswelle, n = 400, identischer Fragebogen.
- Jährlich: Großer Methodik-Audit mit n = 1.500 realer Stichprobe.
Ergebnis 2025: Mittlere Pearson-Korrelation 0,81, drei Drift-Events identifiziert und behoben. Insights-Budget reduziert um 35 Prozent gegenüber 2023, bei stabiler Vorhersage-Genauigkeit. Ein Beispiel, wie hybride Setups operativ funktionieren, beschreibt der Artikel Hybride Marktforschung.
Häufige Fehler beim Abgleich
Auch wenn der Workflow auf dem Papier einfach aussieht, scheitern viele Validierungen an immer gleichen Fehlern. Die fünf häufigsten:
- Zu kleine Anchor-Stichprobe. Unter n = 300 ist die statistische Power zu gering, um echte Korrelationen von Zufall zu unterscheiden. Korrelationen schwanken dann je nach Stichprobenziehung um bis zu 0,3 Punkte.
- Ungleiche Demografie. Wenn das synthetische Panel 18- bis 65-Jährige umfasst und das reale 25- bis 54-Jährige, ist jeder Vergleich verzerrt. Quotenplan immer 1:1 spiegeln.
- Question-Order-Bias. Reihenfolge-Effekte sind in beiden Datenquellen real. Wenn die Fragen in unterschiedlicher Reihenfolge gestellt werden, vergleicht man Äpfel mit Birnen.
- Fehlendes Quality-Gate. Ohne klare Pass-Fail-Schwellen werden auch schlechte Studien freigegeben. Der Quality-Score muss vor jeder Studie definiert sein, nicht erst nach Sicht der Ergebnisse.
- Cherry-Picking der KPIs. Wenn Pearson schlecht aussieht, wird auf Spearman umgeschwenkt. Wenn das auch nicht passt, wird die Vorzeichen-Match-Rate hervorgehoben. Disziplin: Alle KPIs werden vor der Analyse festgelegt und alle berichtet. Verwandte Themen behandelt der Artikel Ethik und Datenschutz bei synthetischen Daten.
Tools für den Abgleich
Der Markt für synthetische Daten und Validierungs-Tools wächst schnell. Vier Anbieter sind aktuell relevant, jeder mit klarem Use-Case-Profil:
- neuroflash. Insights-orientierte Plattform mit Digital Twins, integriertem Fragebogen-Tool und nativem Abgleich gegen reale Anchor-Stichproben. Ideal für Marktforschungs- und Insights-Teams, die ohne Coding-Aufwand arbeiten wollen. Vertiefung im Wiki-Eintrag AI-Panel Marktforschung und Synthetische Zielgruppe.
- Mostly AI. Spezialist für synthetische Tabellendaten mit starkem Fokus auf Datenschutz und Privacy-Preserving-Generation. Ideal für Banken, Versicherungen und Healthcare. Weniger geeignet für offene Marktforschungs-Insights.
- Gretel. Entwickler-orientierte Plattform für synthetische Daten via API, stark in tabularen und Zeitreihen-Daten. Ideal für Data-Science-Teams mit Engineering-Kapazität.
- SDV (Synthetic Data Vault). Open-Source-Bibliothek aus dem MIT, ideal für Forschung und Prototyping, aber ohne SLA und Enterprise-Support.
Faustregel: Wer Insights-Tiefe und schnellen Praxiseinsatz braucht, geht zu neuroflash. Wer rein synthetische Tabellendaten unter strengen Datenschutzauflagen braucht, zu Mostly AI. Wer Engineering-Power hat, zu Gretel oder SDV.
Mit neuroflash schneller zu validen Insights

neuroflash liefert KI-gestützte Marktforschung mit synthetischen Zielgruppen und Digital Twins für den deutschsprachigen Markt. Insights in Stunden statt Wochen, kalibriert auf realen Befragungs- und Verhaltensdaten und nahtlos integriert in Brand-, Copy- und Performance-Workflows. Jetzt kostenlos testen und in der nächsten Sprint-Woche die ersten Persona-getriebenen Insights gewinnen.
FAQ
Wie viele reale Befragte braucht es für einen aussagekräftigen Abgleich?
Mindestens 300, ideal 500 bis 800. Bei kleineren Stichproben sind die Konfidenzintervalle zu breit, um synthetische Werte sauber zu validieren.
Wie oft sollte ein Abgleich wiederholt werden?
Bei aktiven Trackern quartalsweise. Bei Ad-hoc-Studien einmal pro Welle und zusätzlich einmal pro Jahr ein großer Methodik-Audit. Drift kann jederzeit auftreten, regelmäßiges Re-Calibration ist Pflicht.
Was tun, wenn der Abgleich scheitert?
Erst die Ursache identifizieren: Datenquelle, Modellfit oder Fragebogenformulierung. Dann gezielt nachjustieren, etwa durch zusätzliche Trainingsdaten oder Anpassung der Twin-Profile, und erneut validieren. Niemals Ergebnisse veröffentlichen, die das Quality-Gate gerissen haben.
Reicht es, einmalig zu validieren und dann zu vertrauen?
Nein. Konsumentenpräferenzen, Sprachgebrauch und Marktumfeld ändern sich. Ein einmaliger Abgleich ist Startpunkt, kein Endpunkt. Validierung ist ein Prozess, kein Projekt.
Fazit
Der Abgleich synthetischer Daten mit realen Kundendaten ist die Trennlinie zwischen seriöser AI-Marktforschung und teurer Schätzung. Wer den 6-Schritte-Workflow diszipliniert anwendet, klare KPIs reportet und harte Quality-Gates setzt, macht synthetische Studien defendable, reproduzierbar und ESOMAR-konform. Die FMCG-Cases von Coca-Cola, Pepsi und dem DACH-Mittelständler zeigen, dass der Aufwand sich lohnt: 35 bis 60 Prozent Budget-Einsparung bei stabiler Vorhersagegenauigkeit. Wer 2026 noch ohne systematischen Abgleich arbeitet, hat schlicht ein Methodenproblem. Mit neuroflash kannst du diesen Workflow direkt in deinem Insights-Setup operationalisieren.
Quellenverzeichnis
[1] NIQ (2024): „AI-Augmented Insights: Methodology Validation Whitepaper.“ https://nielseniq.com
[2] Quirks Media (2024): „Validating Synthetic Data in Market Research: A KPI Framework.“ https://www.quirks.com
[3] Cohen, J. (1988): „Statistical Power Analysis for the Behavioral Sciences.“ https://doi.org/10.4324/9780203771587
[4] Coca-Cola Company (2023): „Annual Report 2023, Innovation in Consumer Insights.“ https://www.coca-colacompany.com
[5] PepsiCo (2024): „PepsiCo Annual Report 2024, Marketing Effectiveness.“ https://www.pepsico.com
[6] ESOMAR (2024): „AI in Market Research: Guideline and Best Practices.“ https://esomar.org
[7] Mostly AI (2024): „Synthetic Data Quality Assurance Whitepaper.“ https://mostly.ai
[8] Gretel.ai (2024): „Evaluating Synthetic Data Quality.“ https://gretel.ai
[9] DataCebo / SDV (2024): „Synthetic Data Vault: Documentation and Benchmarks.“ https://sdv.dev
[10] GreenBook (2024): „GRIT Report 2024, AI in Market Research.“ https://www.greenbook.org
[11] Forrester Research (2024): „The State of Synthetic Data in Enterprise Insights.“ https://www.forrester.com
[12] marktforschung.de (2024): „Synthetische Daten in der DACH-Marktforschung: Status quo.“ https://www.marktforschung.de


