

Was sind Synthetic Respondents? Kurz gesagt: KI-generierte virtuelle Befragte, die auf Basis von Large Language Models menschliches Antwortverhalten in Umfragen und Interviews simulieren. Sie sollen Marktforschung schneller, günstiger und skalierbarer machen. Qualtrics prognostiziert, dass innerhalb von drei Jahren mehr als die Hälfte der Marktforschung mit KI-erstellten synthetischen Personas durchgeführt werden könnte [5]. Gleichzeitig zeigen aktuelle Studien erhebliche Abweichungen zu echten menschlichen Antworten [1][3]. Die Technologie ist also weder Wundermittel noch Spielerei. Sie ist ein Werkzeug mit klarem Einsatzbereich und ebenso klaren Grenzen. Einen umfassenden Überblick über das Thema findest du in unserem Artikel Digital Twins in der Marktforschung.
Zusammenfassung
- Synthetic Respondents sind KI-generierte Befragte, die menschliches Antwortverhalten simulieren, basierend auf Large Language Models und demografischen Profilen.
- Sie liefern Ergebnisse in Stunden statt Wochen und können tausende Personas gleichzeitig befragen.
- Aktuelle Studien zeigen: Bei 75 bis 80% der Fragen weichen KI-Antworten von menschlichen ab [1]. Sie sind also kein Ersatz, sondern eine Ergänzung.
- Der größte Mehrwert liegt in der Ideenfindung, Hypothesenbildung und Vorab-Validierung, nicht in der finalen Entscheidungsgrundlage.
- Synthetische Daten gelten nach DSGVO als anonym und unterliegen nicht den Regelungen für personenbezogene Daten [10].
- Best Practice ist der Hybrid-Ansatz: Synthetische Daten für Geschwindigkeit, echte Befragte für Validierung.
Definition: Was genau sind Synthetic Respondents?
Synthetic Respondents sind virtuelle Teilnehmer an Marktforschungsstudien. Sie werden von KI-Systemen erzeugt, typischerweise von Large Language Models (LLMs) wie GPT-4 oder vergleichbaren Modellen. Diese KI-Befragten antworten auf Umfragen, bewerten Konzepte oder reagieren auf Werbebotschaften, als wären sie echte Konsumenten.
Doch: Sie sind keine echten Menschen. Sie simulieren consumer behavior auf Basis von Trainingsdaten, die aus Milliarden von Texten, Umfrageergebnissen und Online-Verhalten stammen.
Der entscheidende Unterschied zu klassischen survey responses: Synthetic Respondents geben keine persönlichen Erfahrungen wieder. Sie rekonstruieren wahrscheinliche Antwortmuster aus statistischen Zusammenhängen. NielsenIQ beschreibt sie deshalb treffend als Ergänzung zum Ideenfindungsprozess, die Kalibrierung und kontextuelle Daten erfordert [2].
Im Kontext der Digital-Twin-Technologie bilden Synthetic Respondents die Grundlage für AI-Panels. Diese Panels bestehen aus hunderten oder tausenden virtueller Personas, die jeweils ein spezifisches Konsumentenprofil abbilden.
Wie funktionieren Synthetic Respondents?
Der Prozess lässt sich in vier Schritte unterteilen:
Schritt 1: Persona-Definition. Researchers definieren demografische und psychografische Profile. Alter, Geschlecht, Einkommen, Werte, Kaufverhalten, Mediennutzung. Je detaillierter das Profil, desto brauchbarer der Output. Bellomy betont: Die Persona ist das wichtigste Element. Ohne vollständig akkurates, umfassendes Profil liefert der KI-Output keine brauchbaren Daten [11].
Schritt 2: Prompt-Engineering. Die Umfrage oder Interviewfragen werden zusammen mit dem Persona-Profil als Prompt an das Language Model übergeben. Das Modell erhält die Anweisung, aus der Perspektive dieser spezifischen Person zu antworten.
Schritt 3: Antwortgenerierung. Das LLM generiert Antworten, die zum definierten Profil passen. Bei quantitativen Fragen werden Skalen-Bewertungen erzeugt, bei qualitativen Fragen Freitext-Antworten.
Schritt 4: Aggregation und Analyse. Die synthetischen Antworten werden gesammelt, aggregiert und analysiert, genau wie bei einer klassischen Befragung. Die Ergebnisse fließen in Dashboards, Reports und business decisions ein.
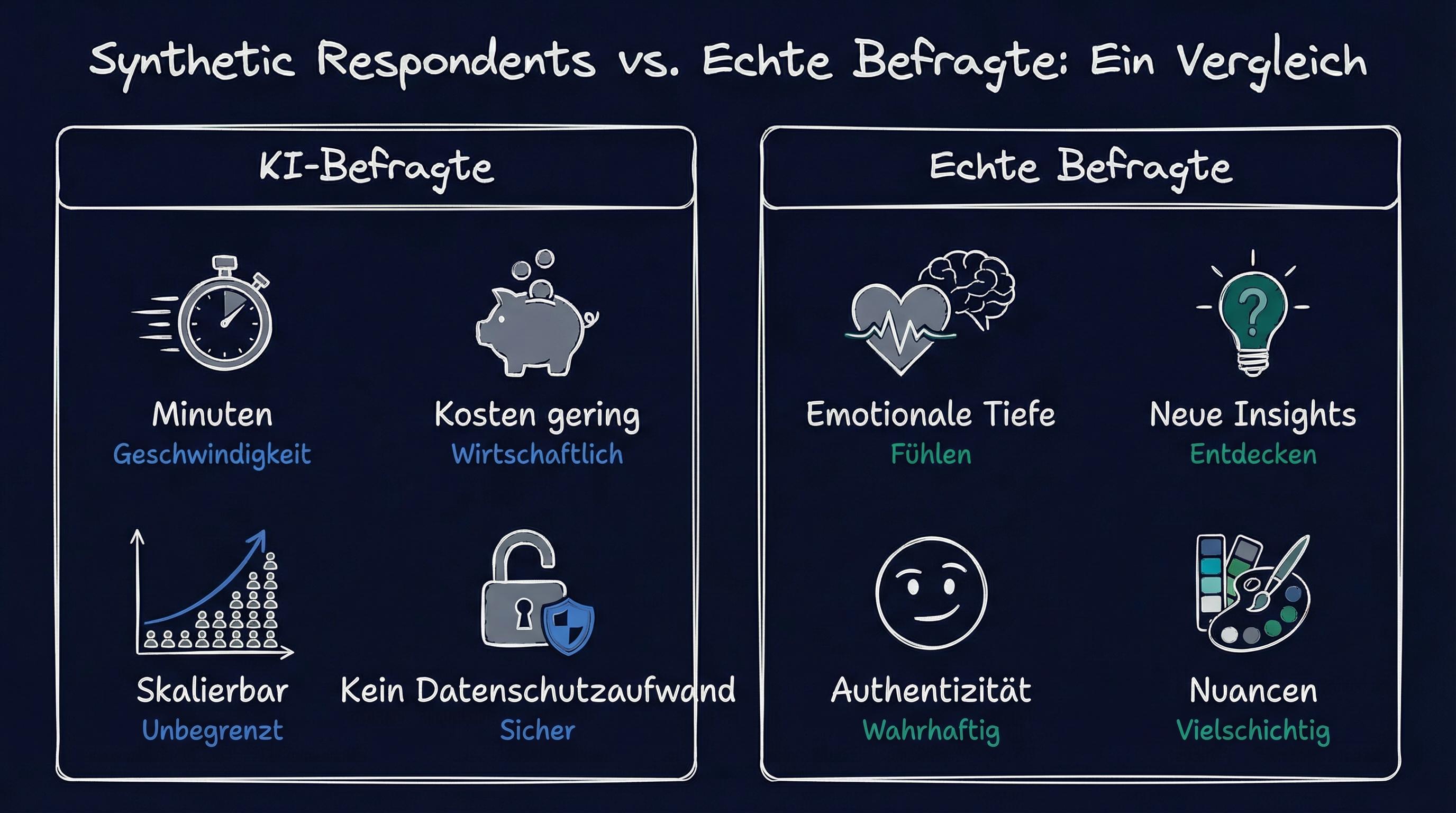
Synthetic Respondents vs. echte Befragte
| Kriterium | Synthetic Respondents | Human Respondents |
|---|---|---|
| Geschwindigkeit | Ergebnisse in Minuten bis Stunden | Tage bis Wochen für Rekrutierung und Feldphase |
| Kosten | Gering, nach initialer Einrichtung skalierbar | Hoch, pro Teilnehmer und pro Frage |
| Skalierbarkeit | Tausende Personas parallel | Begrenzt durch Rekrutierung und Budget |
| Emotionale Tiefe | Eingeschränkt, keine echten Erfahrungen | Authentische Emotionen und Erlebnisse |
| Bias-Risiko | Systematische Verzerrungen aus Trainingsdaten [9] | Individuelle Verzerrungen, aber reale Meinungsvielfalt |
| Neue Insights | Kann nur reproduzieren, was in Daten existiert [6] | Kann genuinely neue Perspektiven liefern |
| Qualitative Tiefe | Kein echtes Gespräch, kein Tonfall, keine Aha-Momente [8] | Tiefe Interviews mit Nachfragen und Kontextwechseln |
| Datenschutz | DSGVO-konform, da keine personenbezogenen Daten [10] | Einwilligungen und Datenschutzkonzepte erforderlich |
Use Cases: Wann Synthetic Respondents echten Mehrwert liefern
Nicht jede Forschungsfrage eignet sich für synthetische Befragte. Aber es gibt klare Szenarien, in denen sie echten Mehrwert schaffen:
Konzept-Screening in der Frühphase. Dein Team hat zehn Produktideen. Statt alle zehn in einer teuren Befragung zu testen, lässt du sie zuerst durch ein AI-Panel laufen. Die drei vielversprechendsten gehen dann in die echte Validierung. Das spart Wochen und Tausende Euro.
Nischenzielgruppen erreichen. Bestimmte Zielgruppen sind schwer rekrutierbar: B2B-Entscheider in spezialisierten Branchen, seltene demografische Kombinationen oder internationale Märkte ohne lokales Panel. Synthetic Respondents können hier erste Richtungsindikatoren liefern. Mehr dazu in unserem Artikel über AI-Panels für Nischenzielgruppen.
GTM-Validierung vor dem Launch. Bevor ein Produkt in den Markt geht, können synthetische Panels Positionierung, Messaging und Pricing vorab testen. Das reduziert das Risiko teurer Fehlentscheidungen. Details zur Methodik findest du unter GTM-Validierung mit AI-Panels.
Iteratives Testing. Werbetexte, Verpackungsdesigns oder Landing Pages lassen sich in schnellen Feedback-Schleifen optimieren. Statt drei Wochen auf Ergebnisse zu warten, bekommt dein Team innerhalb von Stunden eine Einschätzung.
Hypothesenbildung für qualitative Forschung. Synthetic Respondents können helfen, die richtigen Fragen für anschließende focus groups oder Tiefeninterviews zu identifizieren.
Was bedeutet das für dein Team?Synthetic Respondents ersetzen keine echte Forschung. Aber sie beschleunigen den Weg dorthin. Wenn dein Team regelmäßig Konzepte testet oder Zielgruppen-Feedback braucht, können synthetische Panels die Zeit von der Frage bis zur ersten Antwort von Wochen auf Stunden verkürzen.
Grenzen und Risiken
Die Forschungslage ist eindeutig: Synthetic Respondents haben substanzielle Einschränkungen, die jedes Unternehmen kennen muss.
Abweichungen von echtem Verhalten. Die NIM-Studie zeigt, dass KI-Antworten bei 75 bis 80% der Fragen von menschlichen Antworten abwichen. GPT überschätzte bekannte Marken und unterschätzte weniger bekannte [1]. Cambridge-Forscher fanden heraus, dass 48% der Regressionskoeffizienten signifikant abwichen und sich bei 32% sogar die Wirkungsrichtung umkehrte [3].
Bias aus Trainingsdaten. Verian Group warnt: KI-Modelle lernen aus dem Internet und übernehmen Verzerrungen des Online-Diskurses. Synthetische Daten überrepräsentieren dominante Gruppen [9]. Das bedeutet: Bestimmte Meinungen, Kulturen und Lebenswelten sind systematisch unterrepräsentiert.
Fehlende Innovationskraft. Produkt+Markt bringt es auf den Punkt: Synthetische Daten können nur reproduzieren, was in den zugrundeliegenden Informationen bereits existiert. Genuinely neuartige Insights sind nicht möglich [6].
Prompt-Sensitivität. Kantar-Forschung ergab, dass LLMs nur 1% (r-squared) der Muster menschlicher Einstellungsbewertungen reproduzierten. Noch besorgniserregender: Ergebnisse variieren dramatisch bei einfachen Prompt-Umformulierungen [7].
Kontamination echter Umfragen. Ein wachsendes Problem, das die Grenzen zwischen synthetischen und echten Daten verwischt: Stanford-Forscher berichten, dass bereits ein Drittel der Online-Befragten KI-Tools zum Beantworten von Umfragen nutzt [4]. NORC beziffert den Anteil auf 30 bis 46% [12]. Das bedeutet: Auch vermeintlich echte survey responses können KI-generiert sein.
Best Practices für den Einsatz
Wer Synthetic Respondents einsetzen will, sollte diese Prinzipien beachten:
- Hybrid-Ansatz wählen. Synthetische Daten für Geschwindigkeit und Skalierung. Echte Befragte für Validierung und Tiefe. Nie ausschließlich auf KI-generierte Daten vertrauen [2][11].
- Personas präzise definieren. Je detaillierter das Profil, desto brauchbarer die Ergebnisse. Demografische Daten allein reichen nicht. Psychografie, Kaufhistorie und Medienkonsumverhalten machen den Unterschied [11].
- Ergebnisse kalibrieren. Synthetische Daten immer gegen bekannte Benchmarks oder historische Daten abgleichen. Nur so lassen sich systematische Abweichungen erkennen und korrigieren.
- Transparenz gegenüber Stakeholdern. Kommuniziere klar, welche Daten synthetisch und welche menschlich generiert sind. Vertrauen entsteht durch Offenheit, nicht durch Verschleierung.
- Anbieter sorgfältig evaluieren. Nicht alle AI-Panels liefern die gleiche Qualität. Einen Überblick über die wichtigsten Anbieter findest du in unserem Anbieter-Vergleich für AI-Marktforschung.
- Einsatzbereich klar eingrenzen. Synthetische Befragte eignen sich für Screening, Ideation und Vorab-Tests. Für finale Kaufentscheidungen, regulatorische Anforderungen oder emotionale Tiefe bleiben human respondents unverzichtbar.
DSGVO und Datenschutz
Für Unternehmen im DACH-Raum ist die regulatorische Einordnung zentral. Die gute Nachricht: Synthetische Daten gelten nach DSGVO als anonym und unterliegen nicht den Regelungen für personenbezogene Daten, sofern keine Re-Identifizierung möglich ist [10].
Das bedeutet in der Praxis: Kein Einwilligungsmanagement, keine Datenschutz-Folgenabschätzung, keine Löschfristen für die generierten Antworten selbst. Das reduziert den organisatorischen Aufwand erheblich.
Aber: Die Trainingsdaten der Modelle können personenbezogene Informationen enthalten. Unternehmen sollten prüfen, ob der gewählte Anbieter die Anforderungen des EU AI Act erfüllt und transparent dokumentiert, welche Datenquellen verwendet werden. Data integrity beginnt bei der Auswahl des richtigen Partners.
Was bedeutet das für dein Team? Synthetische Daten vereinfachen den Datenschutz erheblich. Kein Einwilligungsmanagement, keine Löschfristen, keine Re-Identifizierungsrisiken. Für Teams, die regelmäßig Marktforschung betreiben, kann das den organisatorischen Aufwand spürbar reduzieren.
Wie neuroflash Digital Twins die Marktforschung verändert

neuroflash hat mit seiner Digital-Twin-Plattform einen Ansatz entwickelt, der über einfache Synthetic Respondents hinausgeht. Statt generische LLM-Antworten zu generieren, setzt neuroflash auf kalibrierte Personas, die auf über einer Million realer Konsumentenprofile basieren.
Der Unterschied zeigt sich in den Zahlen: In mehr als 80 Studien erreichten die neuroflash Digital Twins eine Übereinstimmung von 85 bis 98% mit echten Befragungsergebnissen. Das Konzept dahinter heißt „Decision Security“. Unternehmen sollen nicht nur schnelle Ergebnisse bekommen, sondern Ergebnisse, auf deren Basis sie tatsächlich Entscheidungen treffen können.
Die Plattform ermöglicht es, innerhalb von Stunden tausende kalibrierte Personas zu befragen, Segmente zu vergleichen und Hypothesen zu validieren. Für researchers bedeutet das: Weniger Wartezeit, mehr Iterationen, bessere Entscheidungen. Für Stakeholder bedeutet es: Transparente Methodik und nachprüfbare Genauigkeit.
FAQ
Können Synthetic Respondents echte Befragte komplett ersetzen?
Nein. Die aktuelle Forschung zeigt, dass KI-generierte Antworten bei einem Großteil der Fragen von menschlichen Antworten abweichen [1][3]. Synthetic Respondents sind am wirkungsvollsten als Ergänzung in einem Hybrid-Ansatz [2][11].
Sind synthetische Daten DSGVO-konform?
Ja, grundsätzlich schon. Synthetische Daten gelten als anonym und fallen nicht unter die Regelungen für personenbezogene Daten, sofern keine Re-Identifizierung möglich ist [10]. Dennoch sollte die Herkunft der Trainingsdaten geprüft werden.
Welche Verzerrungen haben Synthetic Respondents?
LLMs übernehmen Verzerrungen aus ihren Trainingsdaten. Dazu gehört die Überrepräsentation dominanter Online-Gruppen, die Überschätzung bekannter Marken und eine systematische Neigung zu bestimmten politischen Positionen [1][9].
Für welche Forschungsfragen eignen sich Synthetic Respondents am besten?
Am besten für Konzept-Screening, Hypothesenbildung, Nischenzielgruppen-Exploration und iteratives Testing. Weniger geeignet sind sie für emotionale Tiefenforschung, finale Kaufentscheidungen und Bereiche, in denen genuinely neue Insights gefragt sind [6][8].
Wie erkenne ich einen guten Anbieter für AI-Marktforschung?
Achte auf Transparenz der Methodik, nachweisbare Validierungsstudien, Kalibrierung gegen echte Daten und DSGVO-Konformität.
Fazit:
Synthetic Respondents sind eine der spannendsten Entwicklungen in der Marktforschung. Sie machen Forschung schneller, günstiger und zugänglicher. Gleichzeitig zeigen die Daten klar: Sie sind kein Ersatz für echte Menschen. Die Abweichungen sind real, die Verzerrungen dokumentiert, die Grenzen definiert.
Der kluge Einsatz liegt im Hybrid-Ansatz. Synthetische Befragte für Geschwindigkeit, Skalierung und Ideation. Echte Befragte für Validierung, emotionale Tiefe und finale Entscheidungen. Wer beides kombiniert, bekommt das Beste aus zwei Welten: Die Effizienz der KI und die Authentizität menschlicher Erfahrung.
Für Unternehmen im DACH-Raum kommt ein weiterer Vorteil hinzu: Synthetische Daten sind datenschutzrechtlich unkompliziert. Keine Einwilligungen, keine Löschfristen, keine Re-Identifizierungsrisiken. In einer Welt, in der DSGVO-Compliance immer aufwändiger wird, ist das ein echtes Argument.
Mein Rat: Starte mit einem klar eingegrenzten Use Case. Teste synthetische Ergebnisse gegen bekannte Benchmarks. Und kommuniziere transparent, welche Daten wie entstanden sind. So baust du Vertrauen bei Stakeholdern auf und nutzt die Technologie dort, wo sie wirklich Mehrwert liefert.
Quellenverzeichnis
[1] NIM (2024): „AI wich bei 75-80% der Fragen von menschlichen Antworten ab.“ https://www.nim.org/en/research/projects-overview/detail-research-project/synthetische-befragte
[2] NIQ/NielsenIQ (2024): „Synthetic respondents sind keine Ersatz für echte Konsumenten, sondern eine Ergänzung.“ https://nielseniq.com/global/en/insights/education/2024/the-rise-of-synthetic-respondents/
[3] Bisbee et al./Cambridge (2024): „48% der Regressionskoeffizienten wichen signifikant von menschlichen ab.“ https://www.cambridge.org/core/journals/political-analysis/article/synthetic-replacements-for-human-survey-data-the-perils-of-large-language-models/B92267DC26195C7F36E63EA04A47D2FE
[4] Stanford GSB (2025): „Etwa ein Drittel der Online-Befragten nutzt bereits KI-Tools zum Beantworten von Umfragen.“ https://www.gsb.stanford.edu/insights/ai-generated-survey-responses-could-make-research-less-accurate-lot-less-interesting
[5] Qualtrics (2025): „Innerhalb von drei Jahren könnte mehr als die Hälfte der Marktforschung mit KI-erstellten synthetischen Personas durchgeführt werden.“ https://www.qualtrics.com/articles/strategy-research/synthetic-responses-101-for-researchers/
[6] Produkt+Markt/marktforschung.de (2025): „Synthetische Daten können nur reproduzieren, was in den zugrundeliegenden Informationen bereits existiert.“ https://www.marktforschung.de/marktforschung/a/synthetische-daten-im-praxistest-methode-mit-zukunft-oder-ueberschaetzt/
[7] Kantar (2024): „LLMs reproduzierten median nur 1% (r-squared) der Muster menschlicher Einstellungsbewertungen.“ https://www.kantar.com/inspiration/analytics/what-is-synthetic-sample-and-is-it-all-its-cracked-up-to-be
[8] MRS/Market Research Society (2024): „Virtuelle Befragte können kein echtes Gespräch führen.“ https://www.mrs.org.uk/blog/operations/synthetic-respondents-in-market-research-risk-or-reward
[9] Verian Group (2024): „KI-Modelle lernen aus dem Internet und übernehmen Verzerrungen des Online-Diskurses.“ https://www.veriangroup.com/news-and-insights/synthetic-sample-in-social-research
[10] Resonio/dr-datenschutz.de (2024): „Synthetische Daten gelten nach DSGVO als anonym.“ https://www.resonio.com/blog/synthetic-data/
[11] Bellomy (2025): „Die Persona ist das wichtigste Element.“ https://www.bellomy.com/insights/right-synthetics-right-time-best-practices-effectively-using-synthetic-respondents
[12] NORC/University of Chicago (2025): „Bis zu 30-46% der Befragten nutzen Chatbots zur Textproduktion in Online-Umfragen.“ https://www.norc.org/research/library/detecting-ai-responses-survey-data-norcs-next-leap-data-quality.html


