





Introducción a GPT-3
GPT-3 (Generative Pre-trained Transformer 3) es un modelo lingüístico avanzado desarrollado por OpenAI. Construido sobre la arquitectura Transformer, GPT-3 es la tercera iteración de la serie GPT y fue lanzado en 2020. El término «generativo» indica que estos modelos son capaces de generar texto, y «preentrenado» sugiere que se entrenan con grandes cantidades de datos antes de perfeccionarlos para tareas específicas. Con su impresionante capacidad para comprender y generar texto similar al humano, GPT-3 se ha convertido en uno de los generadores de lenguaje de inteligencia artificial más potentes hasta la fecha.
GPT-3 cuenta con un extenso modelo de red neuronal con la asombrosa cifra de 175.000 millones de parámetros, lo que supone un aumento sustancial respecto a su predecesor, GPT-2. El amplio espacio de parámetros permite al modelo discernir patrones complejos en extensos conjuntos de datos y captar mejor las estructuras subyacentes de los textos.
Especificaciones técnicas de GPT-3
Parámetro
Arquitectura
Parámetros
Datos previos al entrenamiento
Ajuste de datos
Longitud máxima de la secuencia
Velocidad de inferencia
Año de publicación
Valor
Transformador
175.000 millones
Corpus de textos diversos
Personalizable por tareas
2048 fichas
Varía según el hardware
2020
Desarrollo de GPT-3
GPT hace referencia a una familia de modelos lingüísticos de inteligencia artificial desarrollados por OpenAI. La arquitectura Transformer, introducida en el artículo «Attention Is All You Need» de Vaswani et al. en 2017, constituye la base de los modelos GPT. Los transformadores utilizan un mecanismo de autoatención para procesar los datos de entrada en paralelo, lo que los hace muy eficientes para tareas que implican datos secuenciales, como el procesamiento del lenguaje natural.
La tecnología GPT ha evolucionado con el tiempo y, desde la última actualización de marzo de 2023, existen cuatro iteraciones principales: GPT, GPT-2, GPT-3 y GPT-4.
- GPT: El modelo GPT original, lanzado en 2018, supuso un gran avance en el procesamiento del lenguaje natural. Constaba de 117 millones de parámetros y se entrenó con una amplia gama de datos de texto de Internet.
- GPT-2: Lanzado en 2019, el GPT-2 era una versión más grande y potente del GPT original. Contaba con 1.500 millones de parámetros, lo que la hacía más capaz de generar textos coherentes y contextualmente relevantes. Debido a la preocupación por un posible uso indebido para generar noticias falsas, OpenAI limitó inicialmente el acceso al modelo completo, pero más tarde lo puso a disposición del público.
- GPT-3: Introducido en 2020, el GPT-3 llevó las capacidades de sus predecesores a un nivel completamente nuevo. Con la asombrosa cifra de 175.000 millones de parámetros, se convirtió en uno de los mayores modelos lingüísticos jamás creados. El GPT-3 demostró una comprensión lingüística sin precedentes, generando respuestas muy realistas y adecuadas al contexto a diversas preguntas.
- GPT-4: GPT-4 es el último modelo de lenguaje desarrollado por OpenAI, publicado el 14 de marzo de 2023. Como cuarta versión de la serie GPT, se trata de un gran modelo de lenguaje multimodal capaz de comprender tanto texto como imágenes. GPT-4 se entrena mediante «preentrenamiento», prediciendo la siguiente palabra en frases a partir de fuentes de datos amplias y diversas. Además, utiliza el aprendizaje por refuerzo, aprendiendo de las reacciones humanas y de la IA para ajustar sus respuestas a las expectativas y directrices humanas. Aunque está disponible para el público a través de ChatGPT Plus, el acceso completo a GPT-4 a través de la API de OpenAI está actualmente limitado y se ofrece a través de una lista de espera. Aunque representa una mejora con respecto a GPT-3.5 en la aplicación ChatGPT, GPT-4 sigue enfrentándose a algunos problemas similares, y aún no se han revelado detalles técnicos específicos sobre el tamaño de su modelo.
Estos modelos GPT son ejemplos de aprendizaje no supervisado, en el que los modelos aprenden a partir de grandes cantidades de datos de texto sin etiquetas ni anotaciones explícitas. Durante la fase de preentrenamiento, los modelos desarrollan una comprensión del lenguaje y el contexto, y durante la fase de perfeccionamiento se adaptan a tareas específicas como la traducción, el resumen o la respuesta a preguntas, entre otras.
Cómo funciona la GPT-3
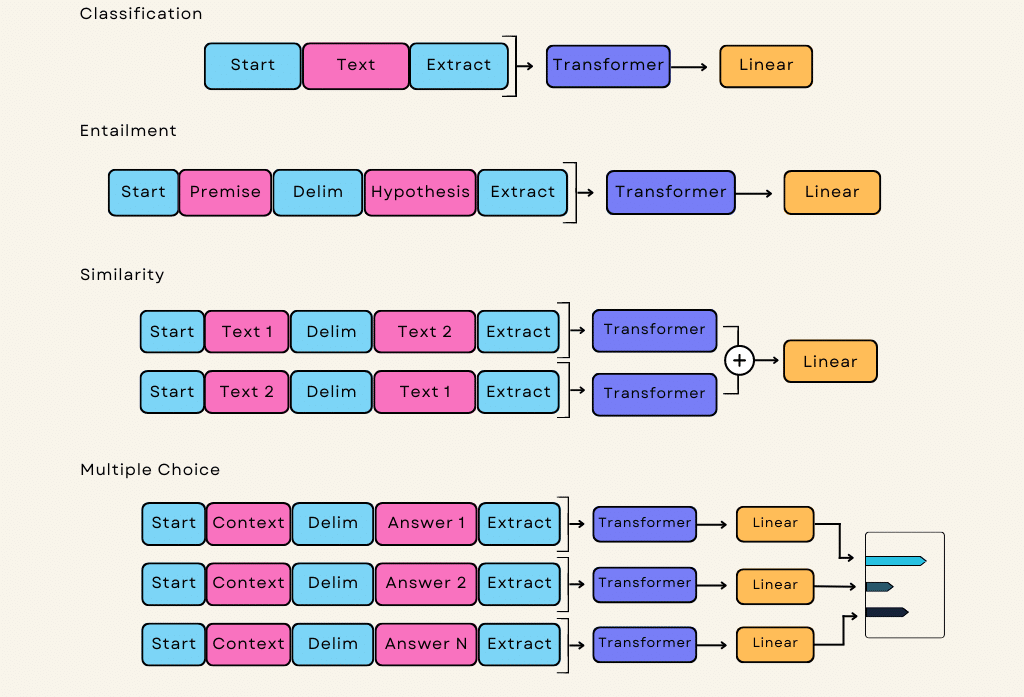
Aprovechando la arquitectura Transformer, GPT-3 destaca en el reconocimiento de dependencias de largo alcance entre palabras y frases dentro de un texto. Esta mejor comprensión del contexto permite al modelo generar respuestas semánticamente coherentes. Además, la inteligencia artificial adopta un enfoque de «aprendizaje no supervisado», lo que elimina la necesidad de un entrenamiento previo específico para cada tarea. A continuación le explicamos en detalle cómo funciona todo:
- Arquitectura: GPT-3 se basa en la arquitectura Transformer, que se presentó en el artículo «Attention Is All You Need» de Vaswani et al. en 2017. La arquitectura Transformer utiliza un novedoso mecanismo de autoatención que permite al modelo procesar los datos de entrada en paralelo, lo que lo hace muy eficaz para manejar secuencias, como el lenguaje natural.
- Preentrenamiento: GPT-3 se «preentrena» en un conjunto de datos masivo compuesto por texto diverso procedente de varias fuentes, como libros, artículos y páginas web. Durante el preentrenamiento, el modelo aprende a predecir la siguiente palabra de una secuencia a partir de las palabras precedentes. Este proceso expone al modelo a una amplia comprensión de la gramática, el contexto y las relaciones entre las palabras.
- Parámetros: GPT-3 es un modelo masivo con 175.000 millones de parámetros. Los parámetros son los pesos aprendibles que el modelo utiliza para hacer predicciones durante el entrenamiento y la inferencia. El gran número de parámetros permite a GPT-3 captar patrones y matices complejos en los datos.
- Puesta a punto: Tras el preentrenamiento en el gran corpus de texto, GPT-3 se ajusta para tareas específicas. El perfeccionamiento consiste en entrenar el modelo en conjuntos de datos más especializados para tareas como la traducción, el resumen o la respuesta a preguntas, entre otras. Este proceso adapta las capacidades del modelo para que sean más pertinentes y precisas para aplicaciones específicas.
- Aprendizaje de «cero disparos» y «pocos disparos»: Un aspecto destacable de GPT-3 es su capacidad para realizar un aprendizaje de «cero disparos» y «pocos disparos». El aprendizaje cero permite que el modelo genere respuestas plausibles para tareas en las que no se ha afinado explícitamente, basándose en una descripción de la tarea. El aprendizaje con pocos ejemplos permite al modelo adaptarse a nuevas tareas con sólo unos pocos ejemplos o demostraciones, sin necesidad de un reentrenamiento exhaustivo.
- Generación y compleción de textos: Dada una indicación o un contexto, GPT-3 puede generar textos coherentes y apropiados al contexto, ya sea completando una frase, escribiendo párrafos o incluso componiendo historias creativas o poemas.
- Comprensión del lenguaje natural: GPT-3 puede comprender y procesar el lenguaje natural, lo que le permite responder a preguntas, proporcionar explicaciones y entablar conversaciones con los usuarios.
- Limitaciones: Aunque GPT-3 es un modelo lingüístico muy avanzado, no está exento de limitaciones. A veces puede generar respuestas que parezcan verosímiles, pero que carezcan de precisión factual o muestren sesgos presentes en los datos de entrenamiento. Además, controlar la producción para garantizar que cumple los requisitos específicos puede resultar complicado.
Aplicaciones de GPT-3
GPT-3 encuentra aplicación en diversos ámbitos, lo que lo convierte en un modelo lingüístico versátil:

- Programación: GPT-3 puede generar fragmentos de código y ayudar a comprender y mejorar el código en múltiples lenguajes de programación.
- Aplicaciones creativas: GPT-3 puede generar textos creativos como poemas, cuentos y letras de canciones, inspirando a los artistas en sus esfuerzos creativos.
- Investigación y análisis: Su capacidad para procesar grandes cantidades de datos textuales ayuda en la investigación y el análisis de corpus textuales y bibliográficos.
- Generación de lenguaje: GPT-3 puede producir textos de alta calidad, desde frases sencillas hasta artículos y narraciones completas.
- Chatbots y asistentes virtuales: Sus capacidades sirven de base para desarrollar chatbots y asistentes virtuales avanzados que faciliten interacciones similares a las humanas.
- Automatización de tareas textuales: El modelo puede automatizar tareas repetitivas, como el resumen de textos, la traducción y las respuestas por correo electrónico.
Uso de GPT-3 con el sistema de tokens OpenAI
El sistema de tokens es un concepto fundamental en GPT-3 y otros modelos lingüísticos basados en la arquitectura Transformer. Las fichas son las unidades individuales de texto que procesa el modelo. En el contexto del lenguaje natural, los tokens pueden ser tan cortos como un carácter o tan largos como una palabra.
En GPT-3, el texto de entrada se descompone en tokens antes de introducirse en el modelo para su procesamiento. Asimismo, la salida del modelo se produce en forma de tokens, que se vuelven a convertir en texto legible.

Estos son algunos puntos clave que hay que entender sobre el sistema de fichas que hay detrás de GPT-3:
- Tokenización: La tokenización es el proceso de descomponer un texto continuo en tokens individuales. Por ejemplo, la frase «Hola, ¿cómo estás?» podría tokenizarse en [«Hola», «,», «cómo», «estás», «tú», «?»].
- Tamaño de los tokens: El tamaño de los tokens en GPT-3 puede variar, pero normalmente utiliza un método de tokenización de subpalabras. En lugar de representar cada palabra como un token único, GPT-3 puede dividir las palabras en unidades más pequeñas, denominadas subpalabras. Por ejemplo, la palabra «increíble» podría tokenizarse en [«increíble», «##increíble»]. Esta tokenización de subpalabras permite al modelo manejar con eficacia las palabras raras y las variaciones morfológicas.
- Limitación de tokens: GPT-3 tiene un límite máximo de tokens, lo que significa que sólo puede procesar un número fijo de tokens en una sola llamada a la API. En mi última actualización, el límite máximo de tokens era de 4096 tokens para GPT-3.
- Recuento de to kens en el coste: Tanto los tokens de entrada como los de salida cuentan en el coste cuando se utiliza GPT-3 a través de la API OpenAI. Esto significa que usted paga en función del número total de tokens utilizados en su solicitud de API y la respuesta generada por el modelo.
- Restricciones de tokens: Para garantizar que una entrada de texto determinada se ajusta al límite de tokens del modelo, es posible que tenga que truncar u omitir partes del texto, en función de su longitud.
- Economización de tokens: Dado que el coste de utilizar GPT-3 se basa en el número de tokens, los desarrolladores suelen intentar optimizar sus llamadas a la API para minimizar el uso de tokens sin dejar de obtener los resultados deseados.
Comprender el sistema de fichas es esencial para utilizar GPT-3 con eficacia, ya que influye no sólo en la capacidad de procesamiento del modelo, sino también en el coste asociado a su uso. Los desarrolladores deben tener en cuenta el uso de tokens y adaptar sus entradas de texto para que se ajusten a los límites de los tokens, a fin de aprovechar al máximo las capacidades de GPT-3 de forma eficiente.
Retos y consideraciones éticas de la GPT-3
A pesar de los impresionantes logros de GPT-3, se enfrenta a retos y problemas éticos típicos de la tecnología avanzada de inteligencia artificial:
- Sesgo e imparcialidad: GPT-3 es susceptible de sesgo, ya que aprende de grandes conjuntos de datos que pueden no estar perfectamente equilibrados, dando lugar a respuestas injustas o discriminatorias.
- Uso indebido: La tecnología puede utilizarse indebidamente con fines fraudulentos o manipuladores, como difundir información errónea o generar contenidos falsos.
- Control de las salidas: Puede ser difícil controlar la salida de GPT-3, dando lugar a respuestas no deseadas o inapropiadas.
- Seguridad y protección: GPT-3, al ser una potente tecnología de inteligencia artificial, tiene el potencial de generar contenidos nocivos, como incitación al odio, acoso o lenguaje violento. Garantizar medidas de seguridad para evitar que el modelo genere resultados perjudiciales es una preocupación importante.
- Sobreajuste y memorización: En ocasiones, GPT-3 puede memorizar patrones de datos específicos durante el preentrenamiento, lo que provoca un ajuste excesivo en determinados conjuntos de datos. Esto puede dar lugar a que el modelo proporcione información aparentemente exacta, pero falsa o poco fiable.
- Explicabilidad e interpretabilidad: El proceso de toma de decisiones de GPT-3 suele considerarse una «caja negra» debido a su compleja arquitectura de red neuronal. Esta falta de transparencia puede suscitar dudas sobre la toma de decisiones del modelo y la posibilidad de respuestas sesgadas o inexplicables.
- Impacto medioambiental: El entrenamiento de grandes modelos lingüísticos como GPT-3 requiere una potencia de cálculo y un consumo de energía considerables. Hay que tener en cuenta el impacto medioambiental de la formación y el funcionamiento a escala de estos modelos.
- Derechos de autor y propiedad intelectual: Los datos utilizados para el preentrenamiento de GPT-3 suelen incluir contenidos protegidos por derechos de autor de diversas fuentes. El uso de material protegido por derechos de autor en el proceso de formación puede tener implicaciones jurídicas y éticas.
- Inclusividad y accesibilidad: Los modelos lingüísticos como el GPT-3 pueden no satisfacer plenamente las necesidades de los usuarios de diversos orígenes lingüísticos o de las personas con discapacidad. Garantizar la inclusión y la accesibilidad es vital a la hora de desplegar modelos de IA para un uso más amplio.
- Consecuencias imprevistas: El despliegue de GPT-3 y tecnologías de IA similares puede tener consecuencias imprevistas en la sociedad, como trastornos económicos, cambios en los modelos de empleo y dependencia social de la IA para la toma de decisiones.
- Dependencia de la IA: A medida que tecnologías de IA como la GPT-3 se generalizan, existe el riesgo de que se dependa excesivamente de ellas, lo que podría provocar una pérdida de las capacidades humanas y del pensamiento crítico.
- Privacidad y propiedad de los datos: La utilización de la GPT-3 puede implicar compartir datos sensibles de los usuarios con el proveedor de IA, lo que plantea dudas sobre la privacidad de los datos, la propiedad y el potencial de explotación de los datos.
- Retos normativos y jurídicos: El despliegue de potentes modelos de IA como GPT-3 puede plantear retos normativos y jurídicos relacionados con la responsabilidad, la rendición de cuentas y el cumplimiento de las leyes y normativas vigentes.
Abordar estos retos y problemas éticos es crucial para garantizar un uso responsable y beneficioso de la GPT-3 y otras tecnologías avanzadas de IA, fomentando la confianza y la transparencia en las aplicaciones de IA.
Enlaces relacionados
Tenga en cuenta que los datos de este artículo están sujetos a cambios, ya que en el futuro pueden aparecer nuevas versiones o mejoras de GPT-3.


