Wer heute KI-gestützte Marktforschung einsetzt, bekommt Antworten schneller, günstiger und in größerem Umfang als je zuvor. Doch mit diesem Tempo wächst eine unbequeme Frage: Können Entscheider den Ergebnissen wirklich vertrauen, wenn sie nicht wissen, wie die KI zu ihnen gekommen ist? Transparenz ist dabei kein bürokratisches Anhängsel, sondern der entscheidende Faktor, der valide Insights von gut klingenden Zufallstreffern trennt.
Dieser Artikel zeigt, welche Offenlegungspflichten heute gelten, wie internationale Standards wie die ESOMAR 20 Questions funktionieren, was das Konzept des Nutrition Label für synthetische Daten in der Praxis bedeutet, und wie Unternehmen ein belastbares Audit-Framework aufbauen.
Zusammenfassung
- KI-Marktforschungsmethoden müssen transparent dokumentiert werden, damit Insights entscheidungsreif sind.
- Relevante Rahmenwerke umfassen die ESOMAR 20 Questions, das Nutrition-Label-Konzept für synthetische Panels sowie die Anforderungen des EU AI Act.
- Ein strukturiertes Audit-Framework hilft Unternehmen, Dokumentationslücken zu schließen und das Vertrauen in KI-generierte Erkenntnisse zu stärken.

Transparenz als Fundament nachvollziehbarer KI-Marktforschung
Warum Transparenz in der KI-Marktforschung kein Optional-Feature ist
Marktforschung hat immer von einem impliziten Vertrauensvertrag gelebt: Die Methode ist bekannt, die Stichprobe beschreibbar, die Fehlerquellen benennbar. Dieses Fundament bröckelt, sobald eine KI Antworten simuliert, Panels synthetisch erzeugt oder Insights aus riesigen Trainingsdaten destilliert – und niemand im Unternehmen genau erklären kann, was hinter der Haube passiert.
Das Ergebnis: Führungskräfte, die Budgetentscheidungen auf der Basis von KI-Marktforschung treffen, sitzen auf einem Informationsfundament, dessen Stabilität sie nicht beurteilen können. Laut einer Analyse von ESOMAR aus dem Jahr 2024 gaben 62 Prozent der befragten Research-Buyer an, dass fehlende Methodentransparenz ihr Vertrauen in KI-gestützte Insights „erheblich“ oder „vollständig“ untergräbt.[1]
Transparenz erfüllt dabei drei Funktionen gleichzeitig: Sie ermöglicht interne Qualitätskontrolle, sie schafft externe Nachvollziehbarkeit gegenüber Auftraggebern und Regulatoren, und sie zwingt Anbieter wie Nutzer dazu, methodische Schwächen explizit zu benennen, bevor daraus strategische Fehler werden.
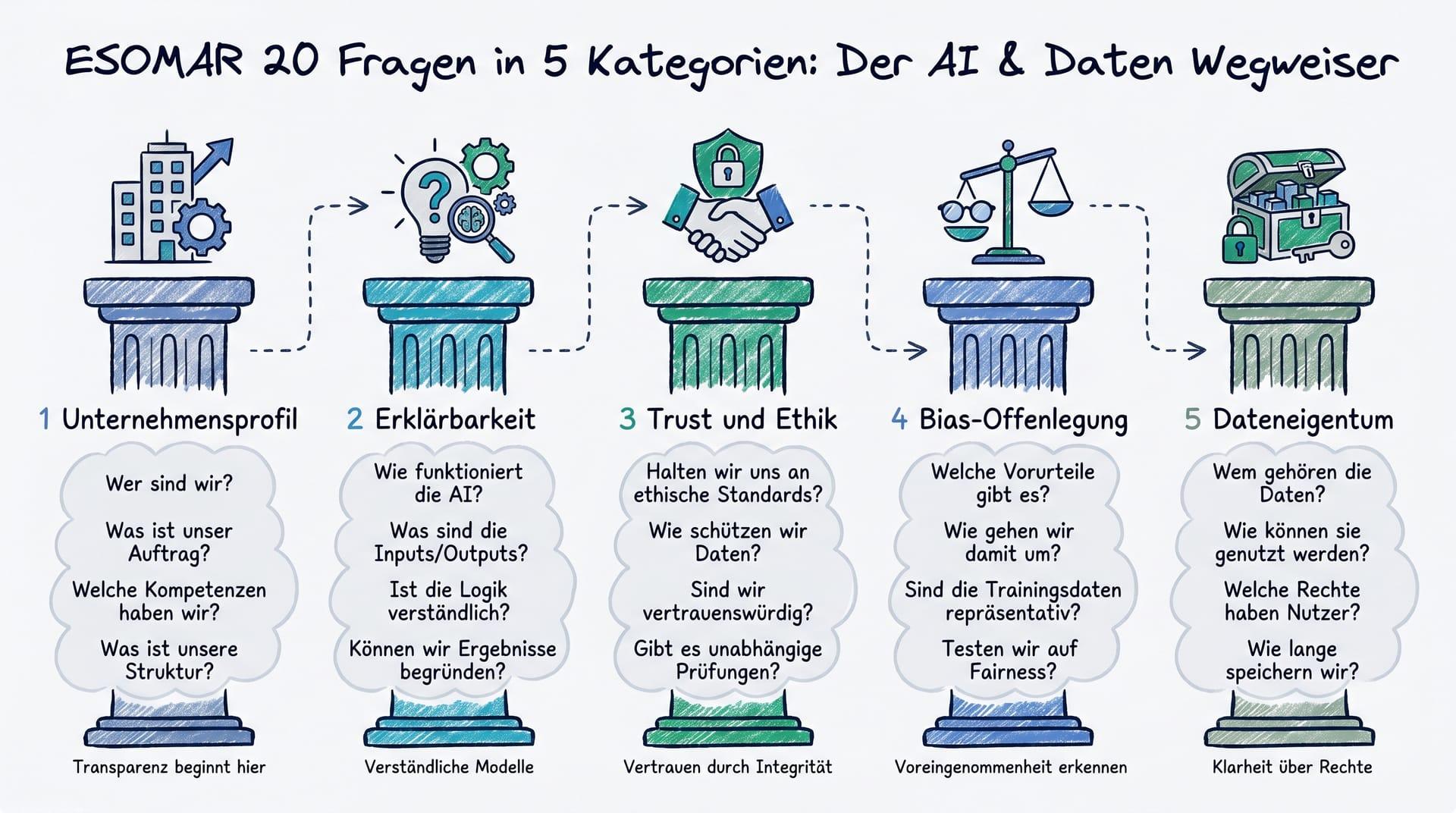
Die ESOMAR 20 Questions: Ein globaler Orientierungsrahmen
ESOMAR, die internationale Vereinigung für Marktforschung und Data Analytics, hat 2023 den Leitfaden „20 Questions to Help Research Buyers of Synthetic Respondents“ veröffentlicht.[2] Das Dokument adressiert direkt die Herausforderung synthetischer Panels und KI-generierter Antworten und liefert einen strukturierten Fragenkatalog, den Auftraggeber ihren Dienstleistern stellen sollten.
Die 20 Fragen gliedern sich in fünf Audit-Kategorien:
| Kategorie | Kernanliegen |
|---|---|
| 1. Datenherkunft & Trainingsgrundlage | Auf welchen Daten wurde trainiert? Wie aktuell sind sie? Sind demografische Gruppen gleichmäßig repräsentiert? |
| 2. Modellarchitektur & Validierung | Welche Modellart liegt zugrunde? Wurde gegen echte Umfragedaten validiert, mit welchen Metriken? |
| 3. Stichprobenlogik | Wie bilden synthetische Profile die Zielpopulation ab? Gibt es eine demografische Kontrollschicht? |
| 4. Uncertainty Quantification | Werden Konfidenzintervalle ausgegeben? Wie kommuniziert das Modell Out-of-Scope-Anfragen? |
| 5. Reproduzierbarkeit | Liefert das Modell bei gleicher Eingabe stabile Ergebnisse? Wie werden Versionsänderungen dokumentiert? |
Der Katalog ist bewusst als Fragenkatalog für Käufer konzipiert, nicht als Zertifizierungsschema. Er überträgt die Verantwortung zu einem erheblichen Teil auf die Einkaufsseite: Wer die Fragen nicht stellt, verzichtet implizit auf die Antworten.
Die fünf Audit-Kategorien der ESOMAR 20 Questions im Überblick
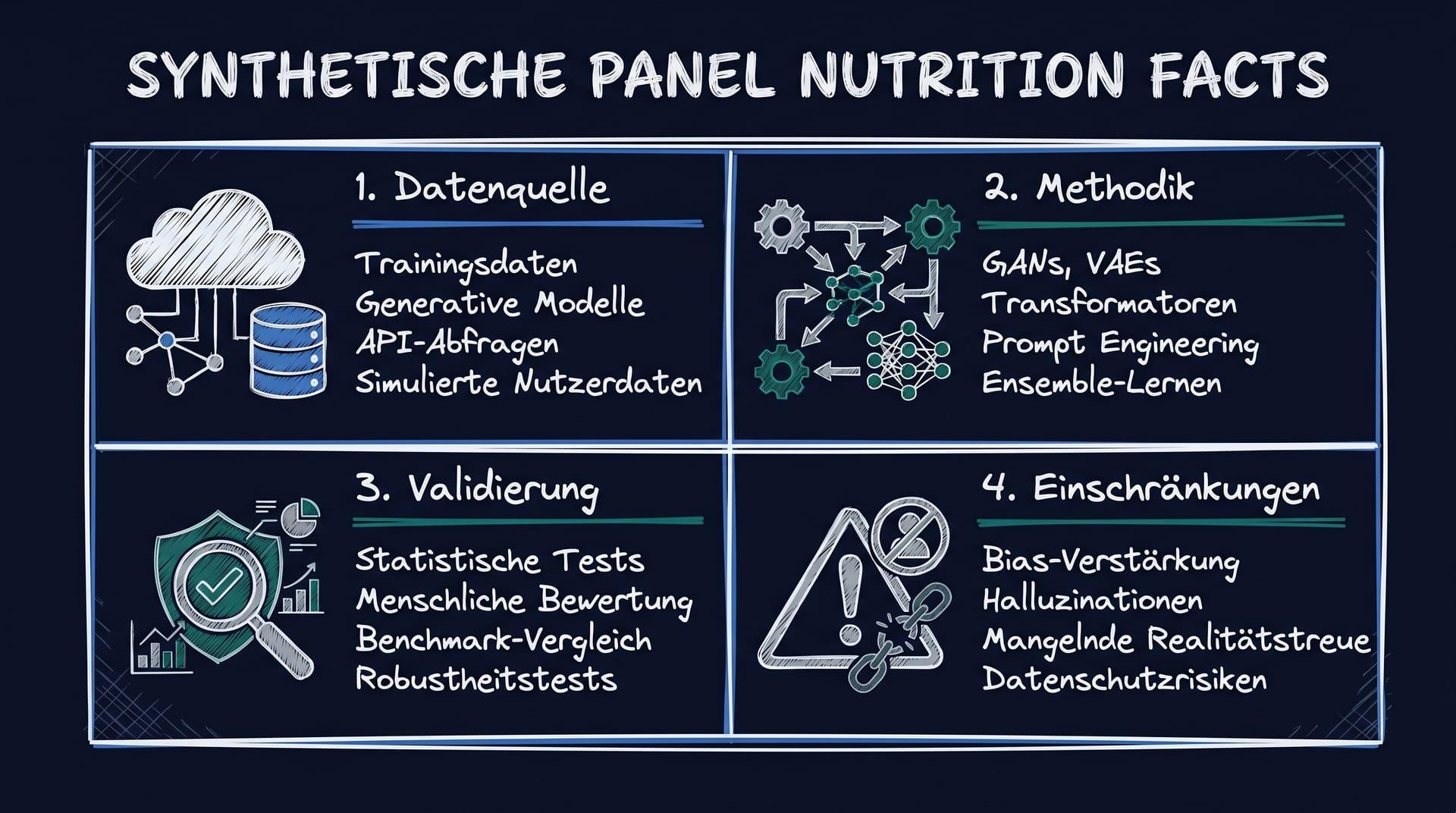
Das Nutrition Label für synthetische Daten
Parallel zu den ESOMAR-Leitlinien hat sich in der KI-Forschungsgemeinschaft das Konzept des „Nutrition Label“ für Datensätze und Modelle entwickelt.[3]. Ein standardisiertes Label soll auf einen Blick vermitteln, was in einem synthetischen Datensatz oder Modell steckt – und was nicht.
Ein Nutrition Label für synthetische Marktforschungsdaten enthält typischerweise folgende Felder:
| Label-Feld | Inhalt |
|---|---|
| Datenquelle | Art und Herkunft der Trainingsdaten (z.B. repräsentative Bevölkerungsumfragen, Online-Panels, Social-Media-Daten) |
| Trainingszeitraum | Von wann bis wann wurden Daten erhoben, auf denen das Modell basiert? |
| Geographischer Geltungsbereich | Für welche Märkte, Länder oder Kulturräume ist das Modell validiert? |
| Demografische Abdeckung | Welche Bevölkerungsgruppen sind stark vertreten, welche unterrepräsentiert? |
| Validierungsstatus | Externe Tests gegen reale Erhebungen mit Abweichungsmetriken |
| Bekannte Limitationen | Explizite Benennung von Themenbereichen oder Segmenten mit eingeschränkter Modellleistung |
| Versionsnummer & Änderungshistorie | Letztes Update, wesentliche Änderungen |
Das Nutrition-Label-Konzept ist noch kein verbindlicher Standard, gewinnt aber rasch an Akzeptanz. Anbieter wie das MIT Data Provenance Initiative-Projekt haben 2024 erste Implementierungen vorgestellt, die zeigen, wie eine maschinenlesbare Version solcher Labels in bestehende Forschungsworkflows integriert werden kann.[4]
Für Marktforscher bedeutet das konkret: Ein Anbieter, der kein Nutrition Label oder eine vergleichbare Dokumentation liefern kann, sollte erhöhte Skepsis auslösen – unabhängig davon, wie überzeugend die Demo-Resultate wirken.
Das Nutrition Label für synthetische Panels: Welche Felder es enthält und warum sie wichtig sind
EU AI Act: Welche Anforderungen ab 2025 gelten
Während ESOMAR-Leitlinien und Nutrition Labels auf freiwillige Adoption setzen, schafft der EU AI Act eine regulatorische Basis, die für in der EU tätige Unternehmen bindend ist.[5]
Der AI Act klassifiziert KI-Systeme nach Risikostufen. Für die Marktforschung relevant ist vor allem die Einstufung von Systemen, die zur „Einflussnahme auf Meinungsbildung“ oder zur „Verarbeitung biometrischer Daten“ eingesetzt werden. Synthetische Personas, die demografische Merkmale modellieren, können je nach Anwendungsfall in die Kategorie „hohes Risiko“ fallen.
Die wichtigsten Transparenzpflichten des AI Act für KI-Marktforschung umfassen:
| Pflicht | Was das in der Praxis bedeutet |
|---|---|
| Kennzeichnungspflicht | KI-generierte Inhalte müssen als solche gekennzeichnet sein. Berichte auf Basis synthetischer Paneldaten ohne Deklaration riskieren Compliance-Probleme. |
| Technische Dokumentation | Anbieter von Hochrisiko-KI-Systemen müssen umfassende technische Dokumentation für Aufsichtsbehörden vorhalten. |
| Menschliche Aufsicht | Bei Hochrisiko-Systemen ist sicherzustellen, dass menschliche Überprüfung in die Entscheidungskette integriert ist. |
| Protokollierungspflichten | Betreiber müssen Logs führen, die eine nachträgliche Überprüfung von Systemoutputs ermöglichen. |
Für Marktforschungsauftraggeber bedeutet das: Wer KI-Insights als Grundlage für Entscheidungen mit erheblichen Auswirkungen nutzt (z.B. Produkteinführungen, Preissetzung, Zielgruppensegmentierung), sollte bereits jetzt prüfen, ob die eingesetzten Systeme die kommenden Anforderungen erfüllen – und entsprechende vertragliche Garantien von Dienstleistern einfordern.
Ein praktisches Audit-Framework für nachvollziehbare KI-Insights
Die theoretischen Rahmenwerke sind hilfreich, aber Unternehmen brauchen auch einen pragmatischen Ansatz für die tägliche Praxis. Das folgende Framework gliedert sich in vier Prüfebenen:[6]
Ebene 1 – Methodendokumentation
Vor jeder KI-gestützten Forschungsstudie wird ein Methodensteckbrief erstellt. Er enthält: eingesetztes Modell und Version, Trainingsdatenbasis, geografischer und demografischer Geltungsbereich, bekannte Limitationen.
Ebene 2 – Validierungsprotokoll
Kritische Forschungsfragen werden mit einer Kontrollstichprobe aus echter Primärforschung gespiegelt. Abweichungen werden dokumentiert und bewertet. Schwellenwert für akzeptable Abweichung: in der Regel unter 10 Prozentpunkten bei Einstellungsfragen.
Ebene 3 – Interpretationsrahmen
Jeder Insight-Report enthält einen standardisierten Methodenkasten: Wie wurde die KI eingesetzt? Was kann aus den Ergebnissen sicher geschlossen werden, was nicht? Welche Folgefragen sollten mit echter Primärforschung beantwortet werden?
Ebene 4 – Regelmäßige Modellüberprüfung
Mindestens einmal jährlich wird geprüft, ob das eingesetzte Modell noch dem aktuellen Stand der Forschung entspricht und ob sich Validierungsmetriken verschlechtert haben. Modellupdates werden in der Forschungsdokumentation vermerkt.
Dieses Framework ist bewusst schlank gehalten. Es zielt nicht auf lückenlose Bürokratie, sondern auf die minimale Dokumentationstiefe, die Entscheider brauchen, um KI-Insights einordnen zu können.
Synthetische Panels und Transparenz: Was neuroflash anders macht
neuroflash hat mit seinen Digital-Twin-Panels eine Infrastruktur aufgebaut, die Transparenz als Designprinzip versteht, nicht als nachträglichen Compliance-Check.[7] Jedes synthetische Panel wird mit einer vollständigen Quelldokumentation ausgeliefert: demografische Zusammensetzung, Trainingsdatengrundlage, Validierungsstatus und bekannte Einschränkungen.
Darüber hinaus bietet die Plattform einen integrierten Methodenkasten für jeden Export, der Research-Teams die Dokumentationsarbeit abnimmt und sicherstellt, dass Insights-Reports von Anfang an die notwendigen Kontextinformationen tragen, die Entscheider für eine informierte Interpretation benötigen.
Transparenz als Wettbewerbsvorteil
Marktforscher, die Transparenz konsequent umsetzen, verschaffen sich einen strategischen Vorteil: Ihre Insights sind vertrauenswürdiger, ihre Empfehlungen besser begründet, und sie sind besser auf regulatorische Anforderungen vorbereitet, die in den nächsten Jahren an Schärfe zunehmen werden.
Die Frage ist nicht mehr, ob KI die Marktforschung verändert – sie tut es bereits. Die Frage ist, ob Unternehmen die methodische Reife mitbringen, diesen Wandel so zu gestalten, dass Insights auch unter Scrutiny bestehen. Transparenz ist dabei der entscheidende Enabler.
FAQ
Was versteht man unter Transparenz in der KI-Marktforschung?
Transparenz in der KI-Marktforschung bedeutet, dass Methoden, Datengrundlagen, Modellgrenzen und Validierungsschritte so dokumentiert und kommuniziert werden, dass Auftraggeber und Entscheider die Qualität und Belastbarkeit von Insights eigenständig beurteilen können. Sie umfasst die Offenlegung von Trainingsdaten, Modellversionen, bekannten Biases und Unsicherheitsmaßen.
Was sind die ESOMAR 20 Questions?
Die ESOMAR 20 Questions sind ein von der internationalen Marktforschungsvereinigung ESOMAR 2023 veröffentlichter Fragenkatalog für Käufer synthetischer Paneldaten und KI-generierter Forschungsoutputs. Sie gliedern sich in fünf Kategorien: Datenherkunft, Modellarchitektur, Stichprobenlogik, Uncertainty Quantification und Reproduzierbarkeit.
Was ist ein Nutrition Label für synthetische Daten?
Ein Nutrition Label für synthetische Daten ist eine standardisierte Dokumentationsform, die auf einen Blick vermittelt, was ein Datensatz oder Modell enthält: Datenquelle, Trainingszeitraum, geografischer Geltungsbereich, demografische Abdeckung, Validierungsstatus, bekannte Limitationen und Versionshistorie.
Welche Pflichten stellt der EU AI Act an KI-Marktforschungssysteme?
Der EU AI Act verpflichtet Betreiber von Hochrisiko-KI-Systemen zur Kennzeichnung KI-generierter Inhalte, zur Vorhaltung technischer Dokumentation, zur Integration menschlicher Aufsicht in Entscheidungsprozesse und zur Protokollierung von Systemoutputs. Die genaue Einstufung hängt vom konkreten Anwendungsfall ab.
Wie führe ich ein KI-Audit in der Marktforschung durch?
Ein KI-Audit in der Marktforschung umfasst vier Prüfebenen: Methodendokumentation vor der Studie, Validierungsprotokoll mit Kontrollstichproben, einen standardisierten Interpretationsrahmen in jedem Report sowie eine jährliche Überprüfung der eingesetzten Modelle auf Aktualität und Validierungsqualität.
Quellenverzeichnis
- ESOMAR (2024): Research Buyer Confidence in AI-Generated Insights. Annual Industry Survey. https://www.esomar.org/publications
- ESOMAR (2023): 20 Questions to Help Research Buyers of Synthetic Respondents. https://www.esomar.org/uploads/public/knowledge-and-standards/codes-and-guidelines/ESOMAR_20-Questions-Synthetic-Respondents.pdf
- Gebru, T. et al. (2018): Datasheets for Datasets. ACM Communications. https://dl.acm.org/doi/10.1145/3458723
- MIT Data Provenance Initiative (2024): Towards Standardized Data Nutrition Labels for AI Training Sets. https://dataprovenance.org
- Europäisches Parlament (2024): Verordnung (EU) 2024/1689 – Artificial Intelligence Act. https://eur-lex.europa.eu/legal-content/DE/TXT/?uri=CELEX:32024R1689
- Nielsen, J. & Landauer, T. (2023): Auditing AI Research Tools: A Practitioner’s Guide. Nielsen Norman Group. https://www.nngroup.com/articles/ai-audit-research
- neuroflash (2024): Digital Twin Panels – Methodik und Transparenzdokumentation. https://neuroflash.com/digital-twin-panels/methodik
- Mitchell, M. et al. (2019): Model Cards for Model Reporting. ACM FAccT Conference Proceedings. https://dl.acm.org/doi/10.1145/3287560.3287596
- ISO/IEC 42001 (2023): Artificial Intelligence Management System Standard. https://www.iso.org/standard/81230.html
- Bundesministerium für Justiz (2024): Umsetzung des EU AI Act in deutsches Recht – Konsultationspapier. https://www.bmj.de/DE/Themen/DigitalesTelekommunikation/KuenstlicheIntelligenz
- Holland, J. (2024): Synthetic Panels in Commercial Research: Validation Benchmarks and Disclosure Standards. IJMR Vol. 66, No. 2. https://journals.sagepub.com/home/mre
- Quirk’s Media (2024): The Transparency Imperative: How Disclosure Practices Shape AI Research Adoption. https://www.quirks.com/articles/the-transparency-imperative