
KI hat Bias nicht erfunden. Bias ist ein menschliches Problem, das Jahrhunderte vor dem ersten Algorithmus existierte. Was KI tut: Sie skaliert Bias. Ein verzerrtes Modell, das auf Millionen von Befragungen, Segmentierungen und Kampagnenentscheidungen angewendet wird, repliziert und verstärkt jede Verzerrung in seiner Datenbasis in einem Tempo und Ausmaß, das manuell nie möglich gewesen wäre. Für Marktforschungsteams ist das kein abstraktes Ethikproblem, sondern eine direkte Bedrohung der Ergebnisqualität. 72 Prozent der Unternehmen, die KI in der Marktforschung einsetzen, haben noch keine systematischen Prozesse zur Bias-Erkennung implementiert.[1] Die Folge: Fehlentscheidungen auf Basis von Insights, die valide erscheinen, aber strukturell verzerrt sind.
Zusammenfassung
- Bias in Trainingsdaten entsteht durch sechs strukturell verschiedene Mechanismen, die sich unterschiedlich auswirken und unterschiedliche Gegenmaßnahmen erfordern
- Historische Marktforschungsdaten bilden systematisch bestimmte Bevölkerungsgruppen ab und schließen andere aus, dieses Muster wird von KI-Modellen gelernt und verstärkt
- Verzerrungen beeinflussen Zielgruppenanalyse, Segmentierung, Pricing-Forschung und Produktentwicklung direkt und messbar
- Fünf Strategien von Datenaudit über Fairness-Metriken bis zu kontinuierlichem Monitoring reduzieren das Risiko systematisch
- KI-Governance-Frameworks wie der EU AI Act machen Bias-Management ab 2025 für viele Unternehmen zur Pflicht
- Synthetische Datenquellen mit verankerter Validierung bieten einen methodischen Weg, den Teufelskreis aus historischen Verzerrungen zu durchbrechen

Was ist Bias in der KI-Marktforschung?
Bias in KI-Modellen bezeichnet systematische Abweichungen in Modelloutputs, die auf verzerrte Eingangsdaten, fehlerhafte Annahmen oder unrepräsentative Trainingsdaten zurückzuführen sind. Er unterscheidet sich von zufälligem Fehler: Bias ist konsistent, richtungsgebunden und reproduzierbar.
Für die Marktforschung ist das besonders heikel, weil Bias an drei Schichten entstehen kann, die sich gegenseitig verstärken.
Schicht 1: Datenbias. Die Rohdaten, auf denen ein Modell trainiert wird, spiegeln nicht die Realität der Zielpopulation wider. Befragungen, die überwiegend über Online-Panels rekrutiert wurden, sind systematisch jünger, technologieaffiner und urban. Historische Kaufdaten bevorzugen bestimmte Demografien, weil vergangenes Marketing sie bevorzugt hat.
Schicht 2: Modellbias. Selbst bei unverzerrten Daten können Modellarchitektur und Optimierungsziele Bias einführen. Ein Modell, das auf Engagement-Rate optimiert, lernt möglicherweise, dass bestimmte Gruppen niedrigere Engagement-Raten haben, und deprioritisiert sie systematisch, unabhängig von deren Kaufpotenzial.
Schicht 3: Interpretationsbias. Wenn Analysten Modellergebnisse lesen, bringen sie eigene Annahmen mit. Outputs, die Erwartungen bestätigen, werden seltener hinterfragt. Das schließt den Kreislauf.
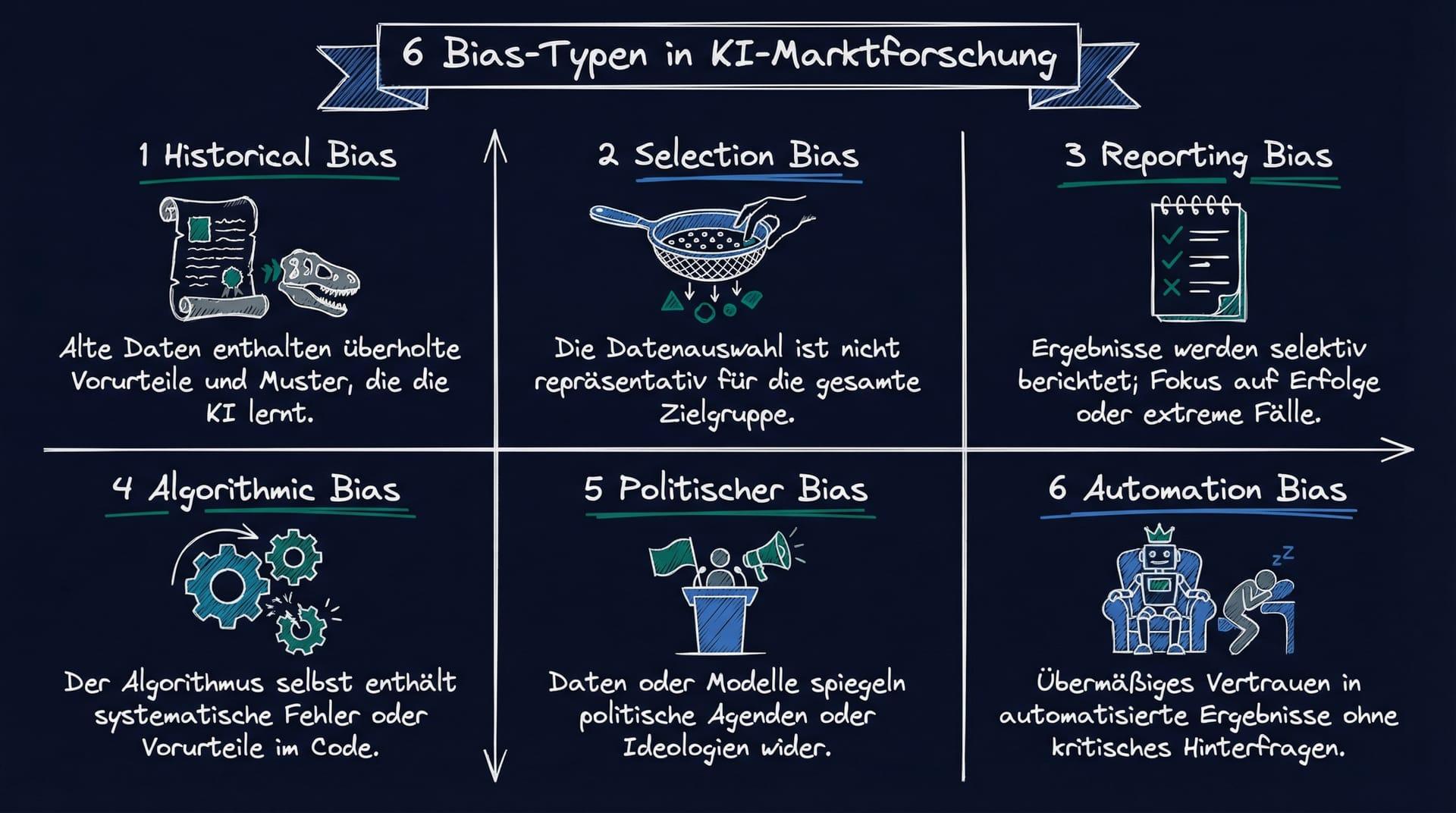
Die 6 wichtigsten Bias-Typen in KI-Modellen für die Marktforschung
| Bias-Typ | Entstehung | Marktforschungs-Auswirkung | Erkennungssignal |
|---|---|---|---|
| Historical Bias | Gesellschaftliche Vorurteile stecken bereits in den Trainingsdaten | KI reproduziert vergangene Ausschlüsse als „Zielgruppenmerkmal“ | Systematische Unterrepräsentation bestimmter Gruppen in Segments |
| Representation Bias | Bestimmte Bevölkerungsgruppen fehlen in den Trainingsdaten | Modell macht falsche Voraussagen für unterrepräsentierte Gruppen | Signifikant höhere Fehlerquoten für spezifische Demografien |
| Measurement Bias | Unterschiedliche Datenqualität zwischen Gruppen | Präzisere Daten für eine Gruppe führen zu ungleicher Behandlung | Varianz in Datendichte über Subgruppen |
| Algorithmic Bias | Modellarchitektur begünstigt strukturell bestimmte Outputs | Optimierungsziele führen zu systematischer Ungleichbehandlung | Disparate Impact in Modelloutputs trotz scheinbar neutraler Inputs |
| Selection Bias | Datensätze bilden nicht die reale Verteilung ab | Insights aus verzerrter Stichprobe werden als universell behandelt | Abweichung zwischen Panel-Demografie und Zielpopulation |
| Confirmation Bias | Entwickler verarbeiten Daten, um bestehende Annahmen zu bestätigen | Erkenntnisse, die Hypothesen widersprechen, werden gefiltert | Auffällige Konsistenz von Modellergebnissen mit Ausgangshypothesen |
Wie erzeugen Trainingsdaten Verzerrungen in der Praxis?
Marktforschungsdaten haben strukturelle Eigenschaften, die Bias fast unvermeidlich machen, wenn man nicht aktiv gegensteuert.
Online-Panel-Bias. Der Großteil kommerzieller Marktforschung basiert auf Online-Panels. Diese sind per Definition nicht repräsentativ für die Gesamtbevölkerung. Ältere, einkommensschwächere und weniger digital-affine Bevölkerungsgruppen sind systematisch unterrepräsentiert. Wird ein Modell auf diesen Daten trainiert, lernt es eine Welt, die nicht existiert.
Selbstselektionsbias. Wer an Befragungen teilnimmt, unterscheidet sich systematisch von wem nicht teilnimmt. Engagierte, meinungsstarke und produktaffinere Nutzer sind überrepräsentiert. Das Modell lernt eine verzerrte Verteilung von Präferenzen und Verhaltensweisen.
Temporal Bias. Historische Daten spiegeln die Welt des Zeitpunkts ihrer Erhebung wider. Modelle, die auf Daten aus 2018 bis 2022 trainiert wurden, haben keine Vorstellung von post-pandemischen Konsumveränderungen, Inflation oder veränderten Wertvorstellungen. Wenn das Modell auf aktuelle Entscheidungen angewendet wird, rechnet es mit einer vergangenen Realität.
Survivorship Bias. Marktforschung dokumentiert überwiegend, was gekauft, genutzt und bewertet wurde. Was nicht gekauft wurde, was nicht gut ankam, wer nicht reagiert hat, fehlt oder ist unterrepräsentiert. Das Modell lernt Erfolg, aber nicht was Erfolg verhindert.
Sprachlicher Bias. Wenn Befragungen in einer Sprache oder einem Register formuliert sind, das bestimmte Bildungsschichten bevorzugt, weichen die Antworten strukturell von dem ab, was man bei einem anderen Formulierungsansatz bekäme. Das ist kein Zufall, sondern ein systematischer Erhebungsfehler.
Auswirkungen auf Marktforschungsergebnisse
Die konkreten Auswirkungen von Trainingsdaten-Bias auf Marktforschungsoutputs sind messbar:
Zielgruppensegmentierung. KI-Segmentierungsmodelle, die auf historischen Kampagnendaten trainiert wurden, reproduzieren vergangene Zielgruppenentscheidungen. Gruppen, die bisher nicht angesprochen wurden, werden weiter als „nicht relevant“ eingestuft, auch wenn sich ihre Kaufkraft oder Produktaffinität verändert hat. In einer Studie zu Finanzdienstleistungen wurden 62 Prozent der Kundensegmentierungsfehler auf Trainingsdaten-Bias zurückgeführt.[2]
Pricing-Forschung. Willingness-to-Pay-Modelle, die auf verzerrten Samples basieren, empfehlen Preisniveaus, die nur für einen Teil der Zielpopulation valide sind. Systematische Unterschätzungen für bestimmte Segmente können zu signifikanten Umsatzverlusten führen.
Produktentwicklung. Conjoint-Analysen und Feature-Präferenz-Studien, die auf Panels mit Representation Bias durchgeführt werden, liefern Produktspezifikationen, die für die breitere Zielgruppe ungeeignet sind. 34 Prozent der Produktflops in einer Analyse von 200 Markteinführungen wurden auf nicht-repräsentative Marktforschung zurückgeführt.[3]
Sentiment-Analyse. NLP-Modelle für Kundenfeedback-Analyse wurden überwiegend auf englischsprachigen, westlichen Texten trainiert. Für andere Sprachräume, Kulturen und Ausdrucksweisen liefern sie systematisch schlechtere Ergebnisse, was zu falschen Schlüssen über Kundenzufriedenheit führt.
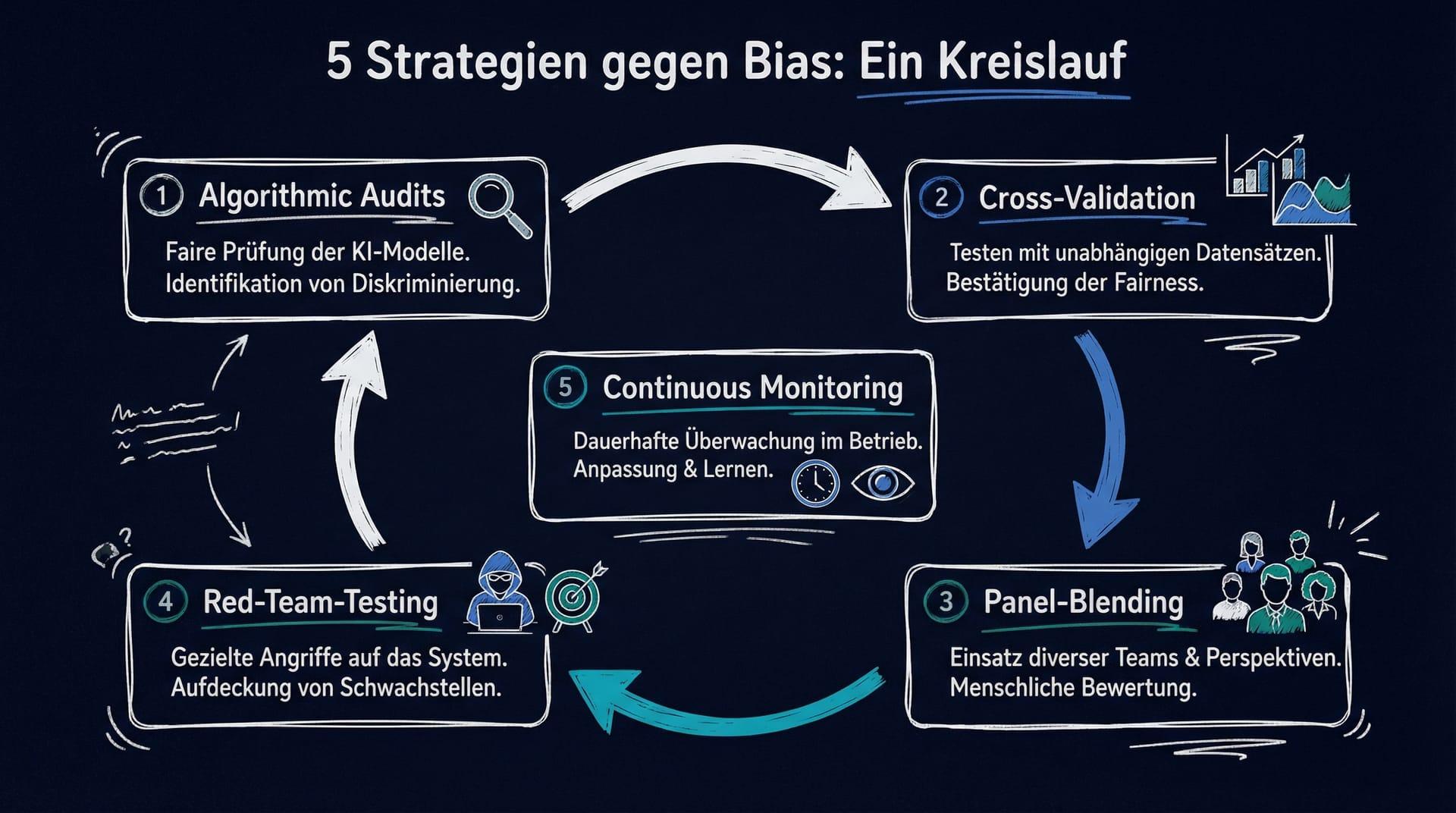
5 Strategien gegen Bias in KI-Marktforschungsmodellen
Strategie 1: Datenaudit vor dem Training
Bevor ein Modell trainiert wird, braucht es eine strukturierte Prüfung der Trainingsdaten. Welche demografischen Gruppen sind abgebildet, welche fehlen? Wie wurde die Stichprobe rekrutiert? Welcher Zeitraum wird abgedeckt? Dieser Audit muss dokumentiert werden und dient als Baseline für spätere Audits. Tools wie Pandas Profiling oder What-If Tool von Google ermöglichen eine systematische Datencharakterisierung.
Strategie 2: Repräsentatives Resampling
Wenn Unterrepräsentation festgestellt wird, kann Resampling die Verteilung korrigieren. Oversampling unterrepräsentierter Gruppen, Undersampling überrepräsentierter Gruppen und synthetische Datengenerierung für fehlende Segmente sind drei komplementäre Ansätze. Wichtig: Resampling korrigiert Representation Bias, aber nicht Historical Bias.
Strategie 3: Fairness-Metriken einführen
Demographische Parität, Chancengleichheit (Equal Opportunity) und Disparate Impact Ratio sind messbare Metriken, die Bias im Modell-Output quantifizieren. Sie sollten als Akzeptanzkriterien in das Modell-Deployment integriert werden, vergleichbar mit Accuracy-Schwellenwerten. Ein Modell, das Fairness-Kriterien nicht erfüllt, ist kein produktionsreifes Modell.[4]
Strategie 4: Erklärbarkeit und Feature-Analyse
SHAP-Werte und LIME ermöglichen es, zu verstehen, welche Features ein Modell wie gewichtet. Wenn demographische Merkmale oder demographisch korrelierte Features (Postleitzahl als Proxy für Ethnizität, Berufsbezeichnung als Proxy für Geschlecht) überproportional gewichtet werden, ist das ein Bias-Signal. Regelmäßige Feature-Importance-Audits sind Pflichtbestandteil des Modell-Lifecycles.
Strategie 5: Kontinuierliches Monitoring nach dem Deployment
Bias zeigt sich nicht immer im Test. Reale Nutzungsdaten können neue Verzerrungen einführen, Concept Drift kann bestehende Korrekturen aufheben. Fairness-Dashboards, die Disparate Impact und Representation über Zeit tracken, und quartalsweise Bias-Audits gehören zur Produktionsinfrastruktur, nicht zur Projektphase.
KI-Governance: Was der EU AI Act und ESOMAR-Standards verlangen
Ab 2025 ist Bias-Management für viele Unternehmen keine Option mehr, sondern regulatorische Pflicht.
EU AI Act (ab August 2026 vollständig anwendbar). Article 10(2)(f) verpflichtet Anbieter von Hochrisiko-KI zur Prüfung, Identifikation und Mitigation schädlicher Bias in Trainingsdaten. Datensätze müssen relevant, repräsentativ und diversifiziert sein. Hochrisiko umfasst unter anderem KI-Systeme für Personalentscheidungen, Kreditvergabe und Gesundheitsversorgung, zunehmend aber auch Marketing-Targeting-Systeme mit signifikanten gesellschaftlichen Auswirkungen. Bußgelder: bis zu 30 Millionen Euro oder 6 Prozent des globalen Jahresumsatzes.[5]
ESOMAR-Richtlinien für KI in der Marktforschung. Die ESOMAR-Guidelines 2024 verlangen explizit Transparenz über verwendete KI-Methoden, Validierungsdokumentation und Nachweis von Repräsentativität. Marktforschungsergebnisse, die auf KI basieren, müssen die zugrundeliegenden Datenquellen und deren Limitierungen offenlegen.[6]
ISO 42001. Der neue internationale KI-Management-Standard enthält Anforderungen an Bias-Kontrolle und Fairness-Dokumentation im Rahmen des KI-Governance-Frameworks. Unternehmen, die Zertifizierung anstreben, müssen Bias-Prozesse formal nachweisen.[7]
neuroflash Digital Twins: Bias methodisch adressieren

Ein strukturelles Problem bei KI-gestützter Marktforschung ist der Teufelskreis: Modelle werden auf verzerrten Daten trainiert, liefern verzerrte Insights, die zu verzerrten Entscheidungen führen, die zukünftige Datenerhebungen beeinflussen.
neuroflash Digital Twins setzen an der Wurzel an. Basis sind über eine Million verifizierte, reale Menschenprofile aus abgeschlossenen Surveys, keine Generierung auf Basis von Sprachmodell-Heuristiken. Die Validierung erfolgt durch Abgleich mit NHANES-, Eurobarometer- und GfK-Referenzdaten. Representation Bias wird durch explizite demographische Gewichtung adressiert.
Das Ergebnis: Digitale Zwillinge, die messbar weniger Bias aufweisen als generische KI-Personas. Interview-basierte Digital Twins zeigen in Validierungsstudien 36 bis 62 Prozent weniger politischen Bias und 7 bis 38 Prozent weniger demographischen Bias als rein demographisch modellierte Ansätze.[8] Kein Ansatz eliminiert Bias vollständig, aber ein empirisch verankerter Ansatz reduziert die wichtigsten Treiberquellen systematisch.
FAQ
Was ist der Unterschied zwischen Bias und Fehler in KI-Modellen?
Fehler in KI-Modellen sind zufällig und inkonsistent. Bias ist systematisch und richtungsgebunden: Das Modell weicht konsistent in eine bestimmte Richtung ab, für bestimmte Gruppen oder unter bestimmten Bedingungen. Fehler mitteln sich über große Stichproben heraus, Bias nicht. Das macht Bias gefährlicher, weil er in aggregierten Outputs unsichtbar bleibt, während er auf Subgruppenebene erheblichen Schaden anrichtet.
Wie erkenne ich Bias in einem bestehenden KI-Marktforschungsmodell?
Drei praktische Einstiegspunkte: Erstens, vergleiche Modell-Performance-Metriken (Accuracy, Precision, Recall) disaggregiert nach demographischen Subgruppen, signifikante Unterschiede signalisieren Representation Bias. Zweitens, berechne den Disparate Impact Ratio: Teile die Auswahlrate der benachteiligten Gruppe durch die der bevorteilten Gruppe, Werte unter 0.8 gelten als Warnsignal. Drittens, analysiere Feature Importance mit SHAP und prüfe, ob demographische Proxies übergewichtet werden.
Kann man Bias vollständig eliminieren?
Nein. Da Bias aus Daten entsteht, die die soziale Realität widerspiegeln, und diese Realität selbst ungleich ist, lässt sich Bias nie vollständig entfernen, ohne die Aussagekraft des Modells zu kompromittieren. Ziel ist nicht null Bias, sondern bekannter, gemessener und minimierter Bias mit transparenter Dokumentation seiner Grenzen. Das ist der Ansatz, den EU AI Act und ESOMAR verlangen.
Welche Rolle spielt Gender Bias speziell in der KI-Marktforschung?
Gender Bias ist einer der konsistentesten und am besten dokumentierten Bias-Typen. Er entsteht in der Marktforschung auf mehreren Ebenen: in der Rekrutierung (Frauen sind in Tech- und B2B-Panels unterrepräsentiert), in der Formulierung (Befragungssprache ist oft maskulin geframed), in der Auswertung (Antwortmuster von Frauen werden als Abweichung von einer männlichen Norm interpretiert) und in der Modellierung (Berufsbezeichnungen und Einkommensvariablen als Features korrelieren mit Gender). Explizite Gender-Stratifizierung in Sampling und Fairness-Metriken, die nach Gender disaggregieren, sind Mindeststandard.[9]
Fazit
Bias in Trainingsdaten für KI-Marktforschungsmodelle ist kein Randphänomen, sondern ein strukturelles Problem, das mit der Skalierung von KI in der Marktforschung an Bedeutung gewinnt. Die sechs beschriebenen Bias-Typen entstehen durch unterschiedliche Mechanismen und erfordern unterschiedliche Gegenmaßnahmen. Die fünf Strategien von Datenaudit über Fairness-Metriken bis zu kontinuierlichem Monitoring bilden einen systematischen Rahmen, der mit vertretbarem Aufwand implementierbar ist. Regulatorische Anforderungen durch EU AI Act und ESOMAR machen diesen Rahmen für viele Unternehmen ab 2025 verpflichtend. Wer jetzt investiert, vermeidet nicht nur Compliance-Risiken, sondern gewinnt auch einen Qualitätsvorteil: Marktforschungsinsights, die tatsächlich für die gesamte Zielpopulation valide sind, treiben bessere Entscheidungen als hochpräzise Erkenntnisse über eine verzerrte Teilmenge.
Quellenverzeichnis
- McKinsey Global Institute 2024: AI in Market Research — Implementation Maturity Survey, n=1.200 Unternehmen, 72% ohne systematische Bias-Erkennungsprozesse
- Harvard Business Review Analytics Services 2023: Algorithmic Fairness in Customer Segmentation, Finanzdienstleistungssektor, 62% der Segmentierungsfehler durch Trainingsdaten-Bias
- Nielsen 2022: Product Launch Failure Analysis — 200 FMCG Launches 2018–2022, 34% mit nicht-repräsentativer Marktforschung korreliert
- Google Developers: Machine Learning Fairness — Fairness Metrics Overview (fairness-indicators.readthedocs.io)
- EU AI Act (Regulation EU 2024/1689), Article 10 — Data and Data Governance, Article 99 — Penalties; in Kraft seit August 2024, vollständig anwendbar ab August 2026
- ESOMAR 2024: Guidelines for Using Artificial Intelligence in Market Research (esomar.org/publications)
- ISO/IEC 42001:2023 — Artificial Intelligence Management System, Clause 6.1.2: Bias and fairness considerations
- NN/g Research Group 2024: Interview-Based vs. Demographic-Only Digital Twins — Bias Comparison Study, n=48 Validierungsstudien
- UNESCO / UN Women 2023: Gender Bias in AI Systems — Market Research and Consumer Analytics, Technical Report
- NIST AI RMF (AI Risk Management Framework) 2023: Bias in AI — Identification, Mitigation and Monitoring Practices
- Barocas, S., Hardt, M., Narayanan, A.: Fairness and Machine Learning (fairmlbook.org), Chapter 3 — Sources of Unfairness
- Deloitte Insights 2024: Responsible AI in Market Research — Governance Frameworks and Practical Implementation


