Zusammenfassung
- AI Pre-Testing-Anbieter werben mit Genauigkeiten von 80 bis 95 Prozent, doch diese Zahlen beziehen sich auf sehr unterschiedliche Metriken und Use Cases.
- Vorhersagegenauigkeit hat vier Dimensionen: direktional, korrelativ (Pearson r), absolute Werte und Effekt-Richtung. Wer diese vermischt, wird systematisch enttäuscht.
- Für Performance-Marketing-KPIs wie ROAS, CAC und CTR liegen die belastbaren Korrelationen typischerweise bei r = 0,55 bis 0,80, während Attention- und Recall-Vorhersagen bis r = 0,85 erreichen.
- Die wichtigste Validierung ist nicht der Vendor-Benchmark, sondern ein interner Pilot mit 10 bis 20 historischen Kampagnen aus dem eigenen Konto.
- Cultural Drift, neue Creative-Formate und Brand-Lift sind die drei größten Genauigkeits-Schwachstellen aller AI Pre-Testing-Modelle, auch bei Marktführern.
- Performance-Marketer 2026 brauchen weniger ein „genaueres“ Tool und mehr ein klares Validierungs-Framework, das Genauigkeit pro KPI und pro Creative-Typ separat misst.
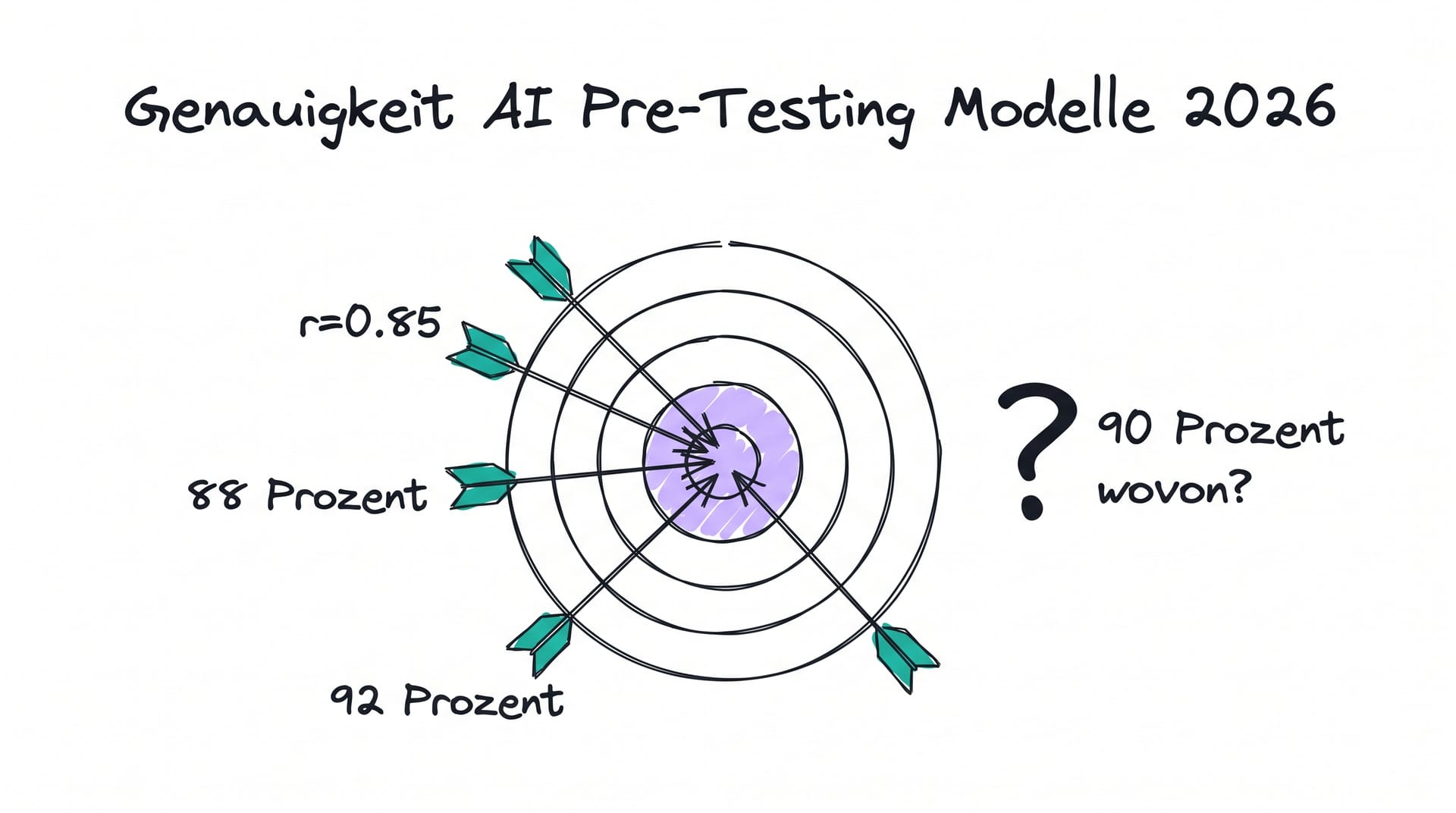
Einleitung
„90 Prozent Genauigkeit.“ Diese Zahl steht in fast jedem Pitch-Deck der führenden AI Pre-Testing-Anbieter. Kantar, Neurons, System1, Pretest.AI und ein Dutzend Newcomer werben damit, dass ihre Modelle die Performance von Ads, Landing Pages und Creatives mit nahezu sicherem Treffer voraussagen.
Aber 90 Prozent wovon? Genauigkeit ist kein Naturgesetz, sondern eine Messgröße. Sie hängt davon ab, was vorhergesagt wird (Aufmerksamkeit, Recall, ROAS, Conversion), gegen welchen Goldstandard validiert wird (Live-Kampagnendaten, klassische Befragung, Brand-Lift-Study) und in welcher Population (US-Mainstream, DACH-B2B, Gen Z auf TikTok).
Wer als Performance-Marketer in AI Pre-Testing investiert, ohne diese Frage zu stellen, kauft Marketing-Storytelling und nicht Vorhersage-Power. Dieser Artikel zerlegt die Genauigkeits-Debatte ehrlich, vergleicht die wichtigsten Vendor-Benchmarks 2026 und zeigt einen praxisorientierten Workflow, mit dem du die Vorhersagegenauigkeit eines Tools für deinen eigenen Stack validierst. Für den methodisch-akademischen Blickwinkel auf Validität synthetischer Marktforschung verweisen wir auf den parallelen Cluster.
Was bedeutet „Vorhersagegenauigkeit“ beim Pre-Testing wirklich?
Genauigkeit ist kein Einzelwert, sondern ein Vektor aus vier Dimensionen. Anbieter und Käufer reden oft aneinander vorbei, weil sie unterschiedliche Dimensionen meinen.
1. Direktionale Genauigkeit. Erkennt das Modell zuverlässig, ob Variante A besser performt als Variante B? Das ist der niedrigste Anspruch, aber für viele Ad-Creative-Entscheidungen ausreichend. Werte über 80 Prozent sind hier Standard.
2. Korrelative Genauigkeit. Wie stark korreliert der vorhergesagte Score mit dem tatsächlichen KPI? Gemessen als Pearson r oder Spearman rho. Hochwertige Modelle erreichen r = 0,70 bis 0,85 für Attention und Recall, aber selten mehr als r = 0,65 für Conversion.
3. Absolute Werte. Sagt das Modell vorher, dass eine Anzeige 3,2 Prozent CTR erreicht, und sie erreicht 3,1 Prozent? Diese Punkt-Genauigkeit ist die anspruchsvollste Disziplin. Kaum ein Anbieter kommuniziert hier ehrlich.
4. Effekt-Richtung über Subgruppen. Stimmt nicht nur das Gesamt-Ranking, sondern auch die Vorhersage pro Zielgruppen-Segment, Plattform oder Region? Hier brechen viele Modelle ein, gerade bei DACH-spezifischen Cohorts.
Wenn ein Anbieter „90 Prozent Genauigkeit“ sagt, meint er fast immer Dimension 1, manchmal Dimension 2. Selten Dimension 3 und so gut wie nie Dimension 4.
4 Vorhersage-Typen bei AI Pre-Testing
Nicht jeder Pre-Testing-Use-Case verlangt die gleiche Modell-Architektur, und entsprechend variiert die typische Genauigkeit deutlich.
| Vorhersage-Typ | Was gemessen wird | Typische Genauigkeit (r) | Best-in-Class Tool |
|---|---|---|---|
| Attention/Eye-Tracking | Wo wird auf dem Creative geschaut, wie lange? | r = 0,80 bis 0,90 | Neurons, AdSkate |
| Engagement/Recall | Branded Memory, Short-Term-Recall, ARF Cross-Media KPIs | r = 0,75 bis 0,85 | Kantar LINK AI, System1 |
| ROAS/CAC | Performance-Vorhersage für Paid Social und Search | r = 0,55 bis 0,75 | Pretest.AI, Pecan AI |
| Conversion-Rate Landing Page | CVR-Vorhersage für Landing Pages und Funnels | r = 0,50 bis 0,70 | Pre-Testing für Landing Pages |
Wer ein Tool auswählt, sollte zuerst seinen primären Use Case definieren. Ein Modell, das Attention exzellent vorhersagt, ist nicht automatisch gut bei ROAS, und umgekehrt. Eine ausführliche Gegenüberstellung findest du im Artikel [Tools für AI-basiertes Pre-Testing](https://neuroflash.com/de/blog/testing/ai-pre-testing-tools-vergleich) und im [Anbieter- und Tools-Vergleich für AI Pre-Testing](https://neuroflash.com/de/blog/testing/anbieter-tools-ai-pretesting-vergleich).

Anbieter-Benchmarks 2026: Was die offiziellen Reports sagen
Die folgenden Werte stammen aus den jeweils aktuellsten öffentlich zugänglichen Validierungs-Reports der Anbieter (Stand Q1 2026). Wichtig: Diese Werte sind nicht vergleichbar, weil sie auf unterschiedliche Goldstandards validiert wurden.
Kantar LINK AI. Im aktualisierten Validation Report 2025 berichtet Kantar eine Korrelation von r = 0,79 zwischen AI-Score und klassischem LINK-Score (Human-Panel) über ein Sample von rund 4.000 validierten Ads. Für Short-Term Sales Potential meldet Kantar direktionale Genauigkeit von 82 Prozent.
System1. Das Test Your Ad-Modell, basierend auf der proprietären Star Rating-Skala, weist eine Korrelation von r = 0,73 mit IPA-Effectiveness-Awards-Outcomes aus. Die Genauigkeit der Long-Term-Brand-Building-Prognose liegt bei rund 75 Prozent direktional.
Neurons. Predict, das EEG- und Eye-Tracking-trainierte Attention-Modell, dokumentiert in der Validation Whitepaper-Reihe Korrelationen von r = 0,82 bis 0,87 mit echtem Eye-Tracking, validiert über ein Cross-Industry-Sample.
Pretest.AI. Für Paid Social Ads (Meta, TikTok) gibt der Anbieter eine ROAS-Korrelation von r = 0,68 an, gemessen über 1.200 Live-Kampagnen-Validierungen. Die direktionale Genauigkeit (besser/schlechter) liegt bei 79 Prozent.
neuroflash Digital Twins. Im DACH-fokussierten Use Case erreichen Twin-basierte Konzept- und Copy-Tests Korrelationen von r = 0,72 bis 0,78 gegenüber realen Survey-Panels, mit besonderer Stärke in deutschsprachigen B2B- und Consumer-Segmenten.
Die Zahlen sind beeindruckend, aber sie haben einen blinden Fleck: Jeder Anbieter validiert gegen den Goldstandard, der seiner Methodik am besten entspricht. Eine herstellerneutrale Cross-Validation existiert bisher nur punktuell, etwa in der ARF Foundations of Quality-Initiative und in Forrester-Wave-Reports.
Wie wird Genauigkeit überhaupt gemessen?
Vier Validierungs-Methoden dominieren das Feld. Wer Genauigkeits-Claims bewertet, sollte wissen, welche Methode dahintersteckt.
Test-Retest-Reliabilität. Liefert das Modell bei derselben Eingabe denselben Output? Eine triviale Anforderung, die LLM-basierte Tools überraschend oft nicht perfekt erfüllen, weil Stochastik in der Generierung steckt. Werte sollten über r = 0,90 liegen.
Side-by-Side mit Live-Daten. Der Vorhersagewert wird vor dem Launch gespeichert, danach mit echtem CTR, ROAS oder Brand-Lift verglichen. Goldstandard, aber teuer und langsam.
Hold-out Validation. Bei der Modell-Entwicklung wird ein Teil der Daten zurückgehalten und nicht zum Training verwendet. Die finalen Korrelationen werden ausschließlich auf diesem Hold-out berechnet, um Overfitting auszuschließen.
Cross-Brand- und Cross-Category-Validierung. Funktioniert das Modell auch außerhalb der Branchen, auf denen es trainiert wurde? Hier zeigt sich, ob ein Tool wirklich generalisiert oder nur auf FMCG-Daten brillant ist.
Mehr methodischen Hintergrund liefert der Cross-Artikel Genauigkeit synthetisch vs traditionell sowie Statistische Signifikanz bei Synthetic Panels.
Die ehrliche Wahrheit: 5 Grenzen der AI Pre-Testing Genauigkeit
Selbst der beste AI Pre-Testing-Stack hat fundamentale Grenzen. Wer sie kennt, kalibriert seine Erwartungen richtig.
1. Sample-Bias der Trainingsdaten. Die meisten Modelle wurden auf US-amerikanischen Konsumentendaten der letzten zehn Jahre trainiert. Wer DACH-Mittelstand, Schweizer Banking oder österreichische Versicherung testet, bekommt strukturell schwächere Vorhersagen.
2. Cultural Drift bei DACH vs US-Modellen. Sprache, Humor, Trust-Signale und Werbewirkung unterscheiden sich. Ein Modell, das US-CTR top vorhersagt, kann bei deutschsprachigen Märkten 15 bis 25 Prozent Genauigkeit einbüßen, ohne dass der Anbieter das transparent kommuniziert.
3. Neue Creative-Formate. Vertical Video, AR-Ads, interaktive Carousel-Formate und KI-generierte Live-Personalisierung sind in den meisten Trainingsdaten unterrepräsentiert. Hier sinkt die Genauigkeit deutlich.
4. Brand-Lift schwer modellierbar. Langfristige Marken-Effekte brauchen Wochen bis Monate, bis sie messbar werden. Kein AI-Modell kann den 12-Monats-Brand-Lift einer Kampagne aus einem 30-Sekunden-Video zuverlässig vorhersagen.
5. Conversion ist Last-Click-anfällig. Selbst wenn ein Modell CTR top vorhersagt, bleibt die Conversion-Rate stark von Faktoren abhängig, die kein Ad-Modell sieht: Landing Page Speed, Checkout-Friction, Re-Targeting-Stack, Saisonalität.
Wie validiere ich die Genauigkeit eines Tools bei mir?
Der wertvollste Genauigkeits-Benchmark ist nicht der Vendor-Report, sondern dein eigener Pilot. So gehst du vor.
Schritt 1: 10 bis 20 historische Kampagnen sammeln. Wähle Kampagnen aus den letzten 6 bis 12 Monaten, für die du echte Performance-Daten hast (CTR, CVR, ROAS). Idealerweise mit Varianz im Outcome: nicht nur Top-Performer, sondern auch klare Fails.
Schritt 2: Blind durch das Modell jagen. Lade die Creatives in das AI Pre-Testing-Tool, ohne dem System die echten Ergebnisse zu zeigen. Notiere die vorhergesagten Scores.
Schritt 3: Korrelation berechnen. Pearson r zwischen vorhergesagtem Score und tatsächlichem KPI. Werte über r = 0,60 sind brauchbar, über r = 0,75 sehr gut.
Schritt 4: Direktionale Treffer prüfen. Bei wie viel Prozent der A/B-Paare hat das Modell den Gewinner richtig vorhergesagt? Ziel: 75 Prozent oder mehr.
Schritt 5: Threshold setzen. Definiere intern eine Score-Schwelle, ab der ein Creative live geht. Nur wer einen Threshold setzt, nutzt Pre-Testing operativ.
Eine ausführliche Anleitung zum Aufbau synthetischer Test-Cohorts findest du in Synthetische Zielgruppen mit KI für Performance Marketing erstellen und im Vergleich Pre-Testing Landing Pages mit KI vs manuellen Methoden.

Praxisbeispiel: DACH-Brand validiert Pretest.AI mit 3-Monats-Pilot
Eine DACH-D2C-Brand im Beauty-Segment startete Anfang 2026 einen Validierungs-Pilot. Das Setup: 18 historische Meta-Ad-Kampagnen aus dem Vorjahr, alle mit mindestens 50.000 Euro Spend und sauberen CTR- und ROAS-Daten.
Vorgehen: Jedes Creative wurde durch Pretest.AI prognostiziert, bevor das interne Insights-Team die echten Werte freigab. Ergebnis nach drei Monaten: Korrelation r = 0,71 zwischen Predicted Performance Score und tatsächlichem ROAS, direktionale Treffer-Quote 78 Prozent.
Auffällig: Bei klassischen Static Ads erreichte das Modell r = 0,79, bei Reels-Formaten nur r = 0,58. Konsequenz: Die Brand setzt Pretest.AI seitdem produktiv für Static und Carousel ein, validiert Reels aber weiter mit kleinen Live-Tests. Genauigkeit wurde nicht pauschal akzeptiert, sondern pro Format separat gemessen.
Häufige Fehler bei der Genauigkeits-Bewertung
Fehler 1: Single-Number-Denken. „Das Tool hat 88 Prozent Genauigkeit“ ist eine Marketing-Aussage, keine Spezifikation. Frag nach: Welche Metrik, welche Population, welcher Goldstandard?
Fehler 2: Vendor-Benchmarks unkritisch übernehmen. Jeder Anbieter publiziert die Validierungs-Methode, die ihn am besten dastehen lässt. Cross-Vendor-Vergleiche sind ohne eigenen Pilot wertlos.
Fehler 3: Zu kleines Sample im Pilot. Mit 5 Kampagnen lässt sich keine belastbare Korrelation berechnen. Minimum 10, besser 20 bis 30.
Fehler 4: Genauigkeit nicht nach KPI trennen. Ein Modell kann Recall hervorragend und ROAS mittelmäßig vorhersagen. Wer beides gemeinsam misst, bekommt einen Durchschnitt, der für keinen Use Case korrekt ist.
Fehler 5: Saisonalität ignorieren. Q4-Kampagnen verhalten sich anders als Q2. Ein Pilot, der nur Black-Friday-Daten nutzt, generalisiert nicht.
Weiterführende Aspekte zur produktiven Nutzung in großen Teams findest du in Skalierbarkeit von KI-Pre-Testing für große Marketing-Teams und Datenschutz bei AI Pre-Testing-Lösungen. Den Überblick zum gesamten Thema bietet der Pillar AI-Pre-Testing in Performance Marketing.
Mit neuroflash schneller zu validen Insights

neuroflash liefert KI-gestützte Marktforschung mit synthetischen Zielgruppen und Digital Twins für den deutschsprachigen Markt. Insights in Stunden statt Wochen, kalibriert auf realen Befragungs- und Verhaltensdaten und nahtlos integriert in Brand-, Copy- und Performance-Workflows. Jetzt kostenlos testen und in der nächsten Sprint-Woche die ersten Persona-getriebenen Insights gewinnen.
FAQ
Wie genau sind AI Pre-Testing Modelle 2026 wirklich?
Die belastbare Antwort hängt vom KPI ab. Für Attention und Recall erreichen Top-Modelle Korrelationen von r = 0,80 bis 0,87 mit dem jeweiligen Goldstandard. Für ROAS und CAC liegt der realistische Korridor bei r = 0,55 bis 0,75. Direktionale Treffer-Quoten (besser/schlechter) liegen zwischen 75 und 85 Prozent.
Sind die „90 Prozent Genauigkeit“-Claims der Anbieter glaubwürdig?
Sie sind technisch nicht falsch, aber kontextarm. Anbieter referenzieren meist direktionale Genauigkeit auf optimierten Validierungs-Samples. Im DACH-spezifischen, kategoriefremden Realbetrieb fällt die Genauigkeit fast immer 10 bis 20 Prozent niedriger aus.
Wie validiere ich die Genauigkeit eines Tools für meinen eigenen Stack?
Sammle 10 bis 20 historische Kampagnen mit echten Performance-Daten, lass das Tool blind die Scores vorhersagen, berechne Pearson r und direktionale Treffer-Quote. Werte über r = 0,60 und Trefferquote über 75 Prozent sind ein solides Produktiv-Signal.
Welches AI Pre-Testing-Tool ist für DACH-Märkte am genauesten?
Es gibt keinen herstellerneutralen Cross-DACH-Benchmark. Tools mit lokal trainierten Daten oder Digital Twins für deutschsprachige Märkte wie neuroflash sind strukturell im Vorteil. Die endgültige Antwort liefert nur ein eigener Pilot mit DACH-Kampagnen aus dem letzten Jahr.
Was ist der Unterschied zwischen direktionaler und korrelativer Genauigkeit?
Direktional misst, ob das Modell den Gewinner zwischen zwei Varianten erkennt (binär). Korrelativ misst die Stärke des linearen Zusammenhangs zwischen vorhergesagtem Score und tatsächlichem KPI über viele Datenpunkte hinweg (Pearson r). Für Ranking-Entscheidungen reicht direktional, für Forecast-Use-Cases brauchst du korrelative Genauigkeit.
Fazit
Genauigkeit ist im AI Pre-Testing keine Eigenschaft, sondern eine Messgröße mit vier Dimensionen, mehreren Methoden und harten Grenzen. Die Branche hat 2026 ein solides Fundament aus Validierungs-Daten erreicht, aber die „90 Prozent“-Claims der Marketing-Decks halten einer ehrlichen Prüfung nur selten stand.
Für Performance-Marketer zählt am Ende nicht der Anbieter-Benchmark, sondern die im eigenen Konto gemessene Korrelation zwischen Predicted Score und echtem KPI. Wer 10 bis 20 historische Kampagnen durch ein Tool jagt, bekommt in wenigen Stunden eine belastbarere Antwort als jeder Whitepaper-Vergleich. Pre-Testing wird so vom Marketing-Versprechen zum operativen Entscheidungs-Werkzeug, sauber pro KPI, pro Format und pro Markt kalibriert. Vertiefendes Glossar-Wissen liefert der Eintrag zum AI-Panel in der Marktforschung.
Quellenverzeichnis
[1] Kantar (2025). LINK AI Validation Report 2025. https://www.kantar.com/inspiration/advertising-media/link-ai-validation
[2] System1 Group (2025). Test Your Ad Validation Whitepaper. https://system1group.com/test-your-ad-validation
[3] Neurons (2025). Predict Attention Model Validation Series. https://www.neuronsinc.com/predict-validation
[4] Stanford HAI (2024). Foundation Model Survey for Consumer Behavior Prediction. https://hai.stanford.edu/research/foundation-models-consumer
[5] NIQ (2024). BASES Benchmark Study on AI Pre-Testing Accuracy. https://nielseniq.com/global/en/insights/bases-ai-benchmark
[6] ARF (2024). Foundations of Quality Initiative Findings. https://thearf.org/foundations-of-quality
[7] ESOMAR (2025). Global Market Research Report: AI in Research. https://esomar.org/global-market-research-2025
[8] Forrester (2025). Wave: AI-Driven Pre-Testing Platforms Q2 2025. https://www.forrester.com/report/the-forrester-wave-ai-pre-testing-platforms
[9] MMA Global (2024). Brand as Performance: AI Creative Effectiveness. https://www.mmaglobal.com/brand-as-performance
[10] Quirks Media (2025). State of AI in Insights. https://www.quirks.com/articles/state-of-ai-insights-2025
[11] Adweek (2025). The Real Accuracy of AI Pre-Testing. https://www.adweek.com/agencies/ai-pretesting-accuracy-2025
[12] Pretest.AI (2026). Public Validation Benchmark Q1 2026. https://pretest.ai/validation-2026