





Pixtral Large ist die neueste Innovation in multimodalen Sprachmodellen, entwickelt von Mistral AI, um die Grenzen der künstlichen Intelligenz bei der gleichzeitigen Interpretation und Verarbeitung von Text- und Bilddaten zu erweitern. Dieser Leitfaden geht tief darauf ein, was Pixtral Large ist, wie es funktioniert, wie seine Struktur aussieht, welche Anwendungen es gibt und wie du es noch heute nutzen kannst.
Was ist Pixtral Large?
Pixtral Large ist ein multimodales Sprachmodell mit 124 Milliarden Parametern, das einen leistungsstarken Text-Decoder mit einem fortschrittlichen Bild-Encoder kombiniert. Dieses hochmoderne Modell überbrückt die Lücke zwischen textueller und visueller Verständnis, wodurch es zu einem idealen Werkzeug für die Verarbeitung komplexer Dateneingaben wird, die Bilder, Diagramme, Dokumente und natürlichen Text umfassen.
Auf der Grundlage von Mistral Large 2 baut Pixtral Large seine Stärken weiter aus und zeichnet sich durch eine beeindruckende Fähigkeit aus, umfangreiche Kontextfenster zu verarbeiten und hohe Genauigkeit bei verschiedenen Benchmarks zu liefern.

Wie Pixtral Large funktioniert
Pixtral Large integriert einen transformer-basierten Text-Decoder mit 123 Milliarden Parametern und einen Bild-Encoder mit 1 Milliarde Parametern. Diese Komponenten arbeiten Hand in Hand, um:
Text-Decoder: Große Mengen an Textdaten zu verarbeiten und erstklassige Leistung bei Aufgaben der natürlichen Sprachverarbeitung zu bieten.
Bild-Encoder: Eine Vielzahl visueller Eingaben zu analysieren und dabei wichtige Details zu bewahren, indem Techniken zur Beibehaltung des Seitenverhältnisses verwendet werden.
Die Synergie zwischen diesen beiden Modulen ermöglicht es Pixtral Large, sowohl Text- als auch Bilddaten nahtlos zu interpretieren, wodurch es in multimodalen Aufgaben wie Dokumentenanalyse, visueller Fragebeantwortung und optischer Zeichenerkennung (OCR) herausragend ist.
Key Features von Pixtral Large
- Umfassendes multimodales Verständnis
Pixtral Large interpretiert natürliche Bilder, Diagramme, Dokumente und andere Formen visueller Eingaben, während es gleichzeitig ein hohes Verständnis für textbasierte Daten bewahrt.
- Erweitertes Kontextfenster
Mit einem Kontextfenster von 128.000 Tokens kann das Modell große Datenmengen verarbeiten, was etwa einem 300-seitigen Buch oder bis zu 30 hochauflösenden Bildern entspricht, ohne dass eine Segmentierung erforderlich ist.
- Leistungsbenchmarks
Pixtral Large hat in mehreren multimodalen Benchmarks erstklassige Ergebnisse erzielt, darunter:
- MathVista für mathematische Denkaufgaben.
- DocVQA für dokumentenbasierte Fragebeantwortung.
- VQAv2 für visuelle Fragebeantwortung.
Leistung
Pixtral Large wurde mit führenden Modellen unter Verwendung eines standardisierten multimodalen Evaluierungsrahmens getestet. Auf MathVista, einem Benchmark, der sich auf komplexes mathematisches Denken über visuelle Daten konzentriert, erzielt das Modell eine Punktzahl von 69,4 %, was alle konkurrierenden Modelle übertrifft. Bei Denkaufgaben, die komplexe Diagramme und Dokumente betreffen, glänzt Pixtral Large sowohl bei ChartQA als auch bei DocVQA und übertrifft GPT-4o und Gemini-1.5 Pro.
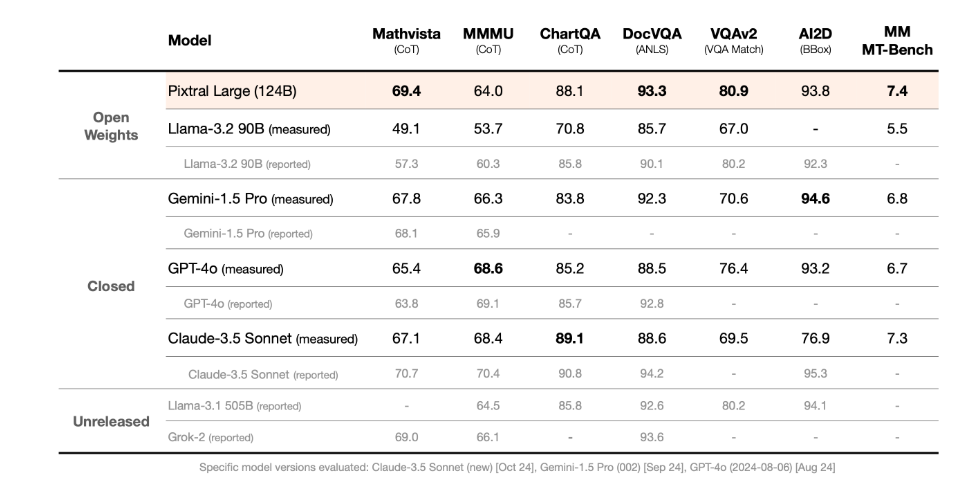
Zusätzlich zeigt Pixtral Large herausragende Leistungen auf MM-MT-Bench und übertrifft Claude-3.5 Sonnet (neu), Gemini-1.5 Pro und GPT-4o (neueste Version). MM-MT-Bench dient als Open-Source-Bewertung, die auf realistische Anwendungen multimodaler LLMs ausgerichtet ist (weitere Details sind im Pixtral 12B technischen Bericht zu finden).
Architektur:
Multimodaler Decoder
Der Decoder in Pixtral Large basiert auf der Architektur von Mistral Large 2. Er verwendet ein transformerbasiertes Framework, das für fortgeschrittenes Denken über Text- und visuelle Modalitäten hinweg entwickelt wurde. Der Decoder ist in der Lage, erweiterte Kontexte von bis zu 128K Tokens zu verarbeiten und glänzt darin, große Mengen an Text- und visuellen Informationen innerhalb eines einzigen Inferenzprozesses zu integrieren.
Vision-Encoder
Parameter:
config (PixtralVisionConfig): Eine Konfigurationsklasse, die alle Parameter für den Vision-Encoder enthält. Die Initialisierung mit einer Konfigurationsdatei richtet die Modellstruktur ein, lädt jedoch nicht die Gewichtungen. Um die Modellgewichtungen zu laden, kann die Methode from_pretrained() verwendet werden.
Der Pixtral Vision-Encoder liefert rohe versteckte Zustände ohne einen spezialisierten Kopf oben drauf. Er erbt von der Klasse PreTrainedModel, was den Zugriff auf allgemeine Methoden ermöglicht, die in allen Modellen der Bibliothek gemeinsam sind (z. B. Herunterladen oder Speichern von Modellen, Ändern der Eingabebetten, Kürzen von Köpfen usw.).
Dieses Modell ist ebenfalls eine Unterklasse von PyTorchs torch.nn.Module. Es kann wie jedes Standard-PyTorch-Modul verwendet werden, und die PyTorch-Dokumentation kann für allgemeine Nutzung und Verhalten herangezogen werden.

Anwendungsfälle von Pixtral Large
Die Fähigkeiten von Pixtral Large eröffnen eine Vielzahl von Anwendungsmöglichkeiten:
Dokumentenanalysen:
Pixtral Large ist für die Dokumentenanalyse optimiert, einschließlich PDFs, Rechnungen und gescannter Materialien. Es unterstützt Aufgaben wie:
- Optische Zeichenerkennung (OCR): Extrahiert Text aus mehrsprachigen Dokumenten.
- Inhaltszusammenfassung: Erzeugt prägnante Zusammenfassungen umfangreicher Dokumente mit eingebetteten Bildern.
- Semantische Suche: Ermöglicht das Abrufen relevanter Informationen aus Datensätzen, die Text- und visuelle Inhalte kombinieren.
Visuelles Frage-Antworten:
Pixtral Large ist in der Lage, visuelle Daten zu interpretieren und zu analysieren, einschließlich:
- Diagramme und Grafiken: Erfasst Trends und identifiziert Anomalien in visualisierten Datensätzen.
- Training Loss Kurven: Bewertet die Leistung von Machine-Learning-Modellen im Zeitverlauf und hilft dabei, Probleme wie Instabilität oder Überanpassung zu erkennen.
Mehrsprachige OCR:
Das Modell unterstützt Konversationssysteme mit mehreren Interaktionen, die Text und Bilder kombinieren. Anwendungsfälle umfassen:
- Kundensupport: Beantwortet Nutzeranfragen durch Analyse von Screenshots und zugehörigem Text.
- Wissensexploration: Bietet detaillierte Erklärungen von Dokumenten, Diagrammen oder Grafiken während interaktiver Sitzungen.
Bild-zu-Code-Konvertierung:
Pixtral Large wandelt Bilder von handgezeichneten oder entworfenen Schnittstellen in ausführbaren HTML- oder Code-Snippets um. Diese Funktion verbindet Design- und Entwicklungsworkflows und steigert die Effizienz bei der Prototypenerstellung.
Zugriff auf Pixtral Large
Lizenzierung:
- Pixtral Large ist unter zwei Lizenzmodellen erhältlich:
- Mistral Research License (MRL): Für Forschungs- und Bildungszwecke.
- Mistral Commercial License: Für kommerzielle Anwendungen.
Verfügbarkeit:
- Pixtral Large wird unter zwei Lizenzen angeboten:
- Mistral Research License: Für akademische Forschung und Bildungszwecke.
- Mistral Commercial License: Für Experimente, Tests und den produktiven Einsatz in kommerziellen Umgebungen.
Zugriffsoptionen:
- Chatbot: Mistrals Chatbot zum Experimentieren mit dem Modell. Klicke hier, um darauf zuzugreifen.
- API: Verfügbar als pixtral-large-latest zur Integration in Anwendungen. Klicke hier, um auf die API zuzugreifen.
- HuggingFace Repository: Offene Gewichte für Self-Hosting und weiteres Fine-Tuning. Klicke hier, um es herunterzuladen.
Lese mehr über Pixtral Large auf der offiziellen Webseite.
Fazit:
Pixtral Large stellt einen bedeutenden Meilenstein im Bereich der KI dar und bietet robuste multimodale Fähigkeiten, die neue Möglichkeiten für das Verstehen und Verarbeiten komplexer Daten eröffnen. Egal, ob du ein Forscher, Entwickler oder Geschäftsleiter bist, Pixtral Large bietet ein unvergleichliches Werkzeug zur Weiterentwicklung deiner Projekte in der Dokumentenanalyse, visuellen Intelligenz und mehr. Mit seinem erweiterten Kontextfenster, hoher Leistung und einfacher Zugänglichkeit ist Pixtral Large darauf vorbereitet, ein Eckpfeiler der KI-gesteuerten Innovation zu werden.












