Content generieren und ihn im selben Zug an einer echten Zielgruppe testen, direkt aus dem Agenten heraus: Genau das ermöglichen die neuen Entwickler-Produkte von neuroflash. Der neuroflash MCP-Server ist ein remote gehosteter HTTP-Server nach dem Model Context Protocol, über den jeder MCP-fähige Client wie Claude Desktop oder Cursor die Digital Twins, Brand Voices und Generierungs-Endpunkte von neuroflash direkt ansprechen kann. Parallel dazu steht die neuroflash API als eigenständiges Produkt bereit. Beide schließen die Feedback-Schleife, die bisher erst nach dem Launch zuschnappte, wenn das Budget schon ausgegeben war[1].
Für Entwickler und AI Engineers heißt das: Ihr baut den Create-and-Validate-Loop nicht mehr nach, ihr ruft ihn ab. Dieser Deep-Dive zeigt, wie Architektur, Authentifizierung und die drei Interaktions-Modi funktionieren, welche sieben Domains die API abdeckt und wie das Setup in Claude Desktop und Cursor konkret aussieht.
TL;DR
- neuroflash veröffentlicht zwei eigenständige Produkte: die neuroflash API und den neuroflash MCP-Server[1].
- Der MCP-Server ist ein Remote-HTTP-Server über Streamable HTTP. Es gibt nichts lokal zu installieren, die Authentifizierung läuft über OAuth 2.0 mit PKCE[2].
- Drei Interaktions-Modi: Traditional (ein Tool pro Endpoint), Plan (ein typisierter JSON-Plan, rund 80 Prozent weniger Tokens bei mehrstufigen Workflows) und Exploratory (discover, query, compare)[2].
- Die API deckt sieben Domains ab: Digital Twins, Brand Voices, Content Generation, Image Generation, Target Audiences, Usage/Quota und Workspaces[3].
- Herzstück sind die Digital Twins, kalibriert an 1.000.000+ realen Profilen mit einer Vorhersage-Parität von 85 bis 95 Prozent gegenüber echten Befragungspanels[4].
- DSGVO-konform, gehostet in Deutschland, ISO-27001-zertifiziert[2].
Was ist der neuroflash MCP-Server und wie unterscheidet er sich von der API?
Der neuroflash MCP-Server ist ein remote gehosteter HTTP-Endpunkt, der die Fähigkeiten von neuroflash als standardisierte Tools für jeden MCP-Client bereitstellt. Die API ist der klassische, direkt adressierbare Weg für eigene Backends und Pipelines. Beide sind eigenständige Produkte und greifen auf dieselbe Datenbasis zu. Der Unterschied: Der MCP-Server bringt die Endpunkte als Tools direkt in den Agenten, die API erfordert eigenen Integrations-Code[1].
Der strategische Punkt dahinter ist einfach. Eine API ist heute kein Nachgedanke mehr, sondern ein Produkt erster Klasse: dokumentiert, versioniert und auf Integration ausgelegt. Und das Model Context Protocol wird zur einheitlichen Werkzeug-Schnittstelle, über die Clients wie Claude, Cursor und eine wachsende Liste weiterer Tools externe Fähigkeiten entdecken und aufrufen[1]. neuroflash bedient beide Ebenen bewusst getrennt, damit ihr das Werkzeug wählen könnt, das zu eurem Stack passt.
Warum ist der Create-and-Validate-Loop das eigentliche Feature?
Weil er die Reihenfolge umkehrt. Statt Content zu veröffentlichen und danach zu messen, ob er ankommt, testet ihr ihn vor dem Launch an einer kalibrierten Zielgruppe. Der Loop läuft in vier Schritten und komplett bevor das Budget ausgegeben ist[1].
Der praktische Ablauf im Agenten: generate_text mit einer brand_voice_id erzeugt on-brand Content, chat_with_twin oder chat_with_twin_group holt das Feedback der Digital Twins ein, ihr verfeinert auf Basis der Ergebnisse und veröffentlicht erst dann[4]. Die vier Stufen:
- Generieren: on-brand Content über die API, in der hinterlegten Brand Voice.
- Validieren: Feedback der Digital Twins. Das ist der differenzierende Schritt.
- Verfeinern: auf Basis der Twin-Antworten nachschärfen.
- Veröffentlichen: mit Sicherheit statt Bauchgefühl.
Die Digital Twins sind dabei kein generischer LLM-Persona-Trick. Sie basieren auf über einer Million realer Befragungsprofile, die seit 2017 gesammelt wurden, mit bis zu 255 Datenpunkten pro Person, und erreichen eine Parität von 85 bis 95 Prozent gegenüber echten Panels[4]. Wer die nicht-technische, marketingseitige Perspektive auf diesen Loop sucht, findet sie in unserem Schwester-Artikel zu Digital Twins per API und MCP im Marketing.
Wie ist der MCP-Server technisch aufgebaut?
Der Server ist ein Remote-HTTP-Server über Streamable HTTP, es gibt also nichts lokal zu installieren oder zu warten. Die Authentifizierung läuft über OAuth 2.0 mit PKCE: Ihr meldet euch per Browser an eurem neuroflash-Konto an, es landen keine API-Keys in Config-Dateien, und es werden ausschließlich gescopte Tokens ausgestellt[2].
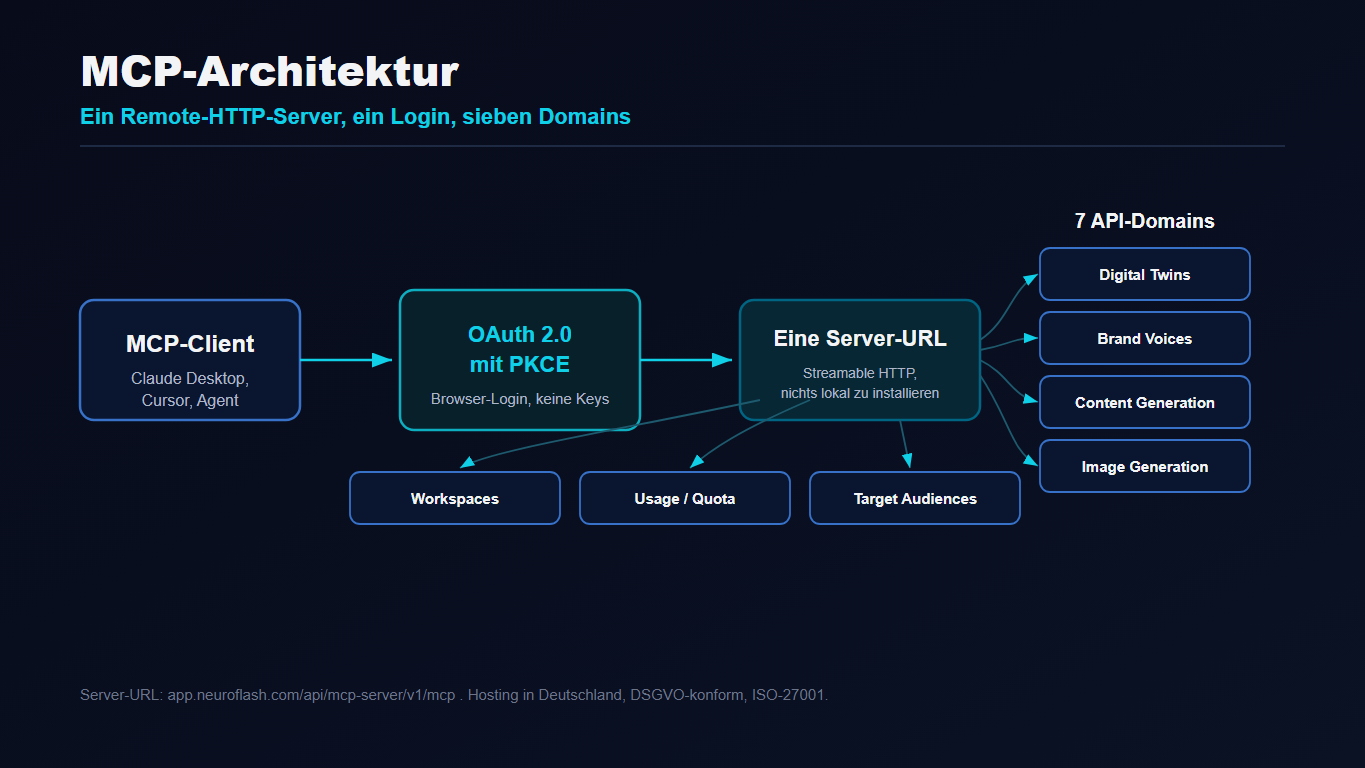
Ein Login, eine Server-URL, sieben Domains dahinter. Kompatibel ist der Server mit jedem MCP-Client, der Streamable HTTP sowie HTTPS- oder Loopback-Redirects unterstützt[2]. Wichtig für die Budgetplanung: API- und MCP-Nutzung ziehen aus demselben Workspace-Kontingent wie die Web-App. Es gibt keinen separaten Budget-Tier und keine versteckten Zähler, der Verbrauch ist über alle Zugriffswege hinweg vereinheitlicht[2].
Was leisten die drei Interaktions-Modi?
Sie bieten drei Wege, denselben Server anzusprechen, je nach Aufgabe. Traditional ist ein Tool pro Endpoint für einzelne Operationen. Plan bündelt mehrere Schritte in einen typisierten JSON-Plan und spart so rund 80 Prozent Tokens. Exploratory navigiert die API-Oberfläche schrittweise für offene Fragen[2].
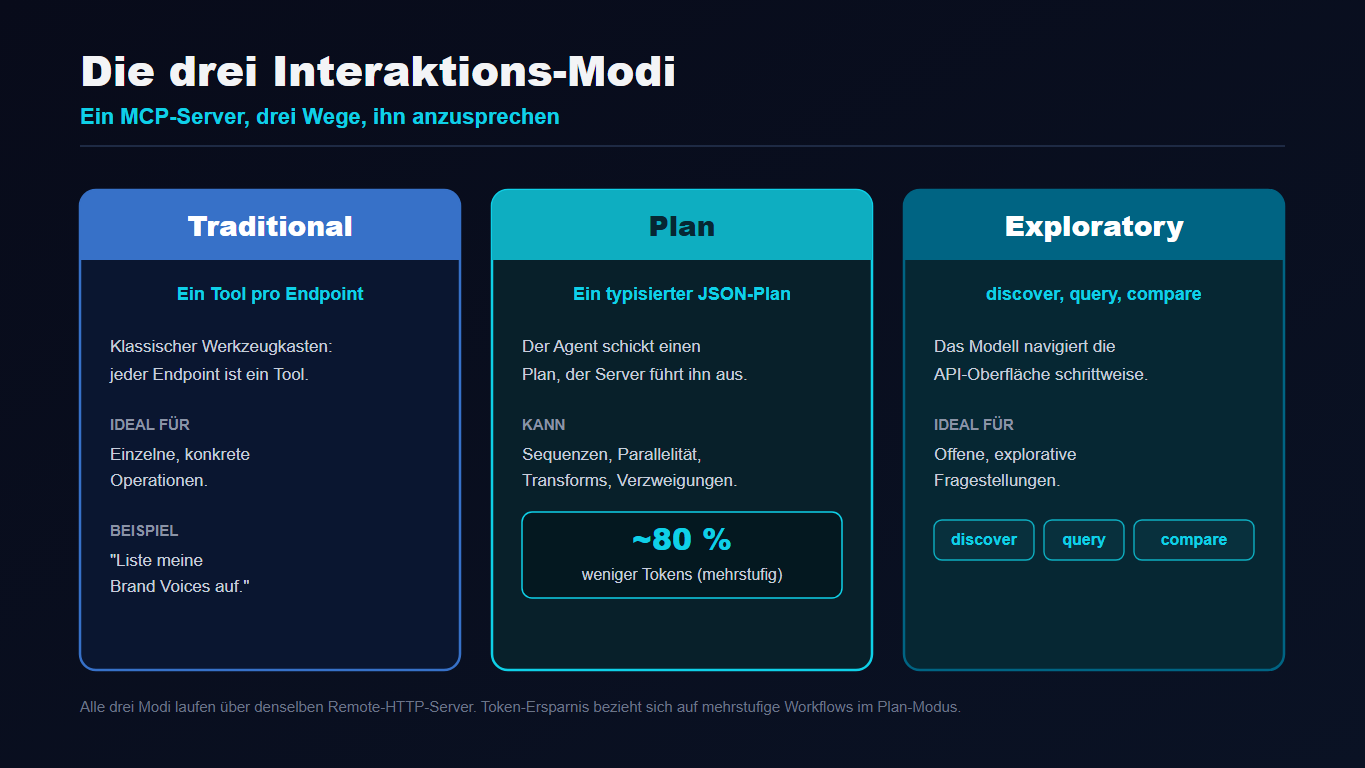
| Modus | Prinzip | Ideal für |
|---|---|---|
| Traditional | Ein Tool pro Endpoint | Einzelne, konkrete Operationen (etwa „Liste meine Brand Voices auf“) |
| Plan | Ein typisierter JSON-Plan, serverseitig ausgeführt (Sequenzen, Parallelität, Transforms, Verzweigungen, begrenzte Loops) | Mehrstufige Workflows, rund 80 Prozent weniger Tokens |
| Exploratory | discover, query, compare | Offene, explorative Fragestellungen |
Der Plan-Modus ist der interessanteste für produktive Agenten. Statt das Modell Schritt für Schritt Tool-Calls absetzen zu lassen, schickt der Agent einen einzigen typisierten Plan, den der Server ausführt. Ein minimales Beispiel, das die Kontingente eines Workspace abfragt:
{
"version": "1",
"steps": [
{ "id": "all", "call": { "method": "GET",
"path": "/api/usage-service/v1/workspaces/{workspace_id}/quotas" },
"args": { "workspace_id": "$ctx.workspace_id" } }
],
"return": { "all": "$all" }
}Der Platzhalter $ctx.workspace_id wird automatisch aus der authentifizierten Session aufgelöst[2]. Bei mehrstufigen Workflows spielt genau dieser Ansatz seinen Token-Vorteil aus, weil Zwischenergebnisse nicht durch das Modell-Kontext-Fenster wandern müssen.
Welche sieben Domains deckt die API ab?
Die API ist in sieben fachliche Domains gegliedert, von der Zielgruppen-Simulation bis zur Verbrauchsabrechnung. Jede Domain bündelt die Endpunkte eines Aufgabenbereichs, sodass ihr gezielt nur das anbindet, was euer Workflow braucht[3].
- Digital Twins: KI-Repräsentationen realer Zielgruppensegmente abfragen.
- Brand Voices: markenkonforme Tonalität anlegen, importieren und anwenden.
- Content Generation: Texte für alle Kanäle in eurer Brand Voice.
- Image Generation: markenkonforme Visuals direkt im Workflow.
- Target Audiences: Zielgruppen verwalten.
- Usage/Quota: Verbrauch nachverfolgen.
- Workspaces: Unterstützung für mehrere Workspaces.
Wie richte ich den Server in Claude Desktop und Cursor ein?
In Claude Desktop fügt ihr einen benutzerdefinierten Connector hinzu, in Cursor tragt ihr den Server in die mcp.json ein. In beiden Fällen genügt die eine Server-URL, den Rest erledigt der OAuth-Login im Browser[2].
Für Claude Desktop: unter Settings zu Connectors gehen, „Add custom connector“ wählen und die Server-URL https://app.neuroflash.com/api/mcp-server/v1/mcp einsetzen. Es öffnet sich ein Browser-Fenster, in dem ihr euch mit dem neuroflash-Konto anmeldet und autorisiert. Danach die Tool-Permissions auf „Allow All“ setzen, damit die Ausführung nicht bei jedem Aufruf unterbrochen wird[2].
Für Cursor tragt ihr den Server in ~/.cursor/mcp.json ein:
{
"mcpServers": {
"neuroflash": {
"command": "npx",
"args": ["mcp-remote", "https://app.neuroflash.com/api/mcp-server/v1/mcp"]
}
}
}Das funktioniert mit jedem MCP-Client, der Streamable HTTP und HTTPS- oder Loopback-Redirects unterstützt[2].
Loslegen
Der schnellste Weg in den Create-and-Validate-Loop: Server-URL in deinen MCP-Client eintragen oder die API direkt anbinden und in wenigen Minuten den ersten Twin-Call absetzen. Die folgenden Ressourcen bringen dich von der Übersicht bis zur fertigen Integration.
- neuroflash API im Überblick
- neuroflash MCP-Server im Überblick
- API-Dokumentation
- MCP-Server einrichten
Die nicht-technische, marketingseitige Perspektive auf denselben Loop findest du im Schwester-Artikel zu Digital Twins per API und MCP im Marketing.
FAQ
Muss ich für den neuroflash MCP-Server etwas lokal installieren?
Nein. Der Server ist ein Remote-HTTP-Server über Streamable HTTP. Ihr hinterlegt nur die Server-URL in eurem MCP-Client und meldet euch per Browser an. Es gibt keine lokale Server-Komponente und keine API-Keys in Config-Dateien[2].
Wie funktioniert die Authentifizierung?
Über OAuth 2.0 mit PKCE. Ihr autorisiert den Client einmalig per Browser-Login an eurem neuroflash-Konto, danach arbeitet der Server mit gescopten Tokens. Kompatibel ist jeder Client, der HTTPS- oder Loopback-Redirects unterstützt[2].
Wann lohnt sich der Plan-Modus gegenüber Traditional?
Sobald ein Workflow mehrere Schritte umfasst. Der Plan-Modus bündelt Sequenzen, Parallelität, Transforms und Verzweigungen in einen typisierten JSON-Plan, den der Server ausführt, und spart dabei rund 80 Prozent Tokens gegenüber einzelnen Tool-Calls. Für einzelne Operationen bleibt Traditional der direktere Weg[2].
Teilen sich API und MCP dasselbe Kontingent?
Ja. API- und MCP-Nutzung ziehen aus demselben Workspace-Kontingent wie die Web-App. Es gibt keinen separaten Budget-Tier und keine versteckten Zähler, der Verbrauch ist über alle Zugriffswege vereinheitlicht[2].
Wie belastbar sind die Digital Twins wirklich?
Sie basieren auf über 1.000.000 realen Befragungsprofilen mit bis zu 255 Datenpunkten pro Person und erreichen eine Vorhersage-Parität von 85 bis 95 Prozent gegenüber echten Panels. Generische LLM-Prompts liegen bei rund 55 Prozent. Das macht den Validierungsschritt im Loop belastbar genug für Entscheidungen vor dem Launch[4].
Fazit
Der eigentliche Fortschritt ist nicht, dass neuroflash jetzt eine API und einen MCP-Server hat. Es ist, dass die Validierung an einer kalibrierten Zielgruppe zu einem Tool-Call wird, den euer Agent selbst absetzt. Der Plan-Modus mit seiner Token-Ersparnis und die saubere OAuth-2.0-mit-PKCE-Anbindung zeigen, dass hier für Entwickler und nicht für Marketing-Demos gebaut wurde. Wer Agenten produktiv betreibt, sollte den Server einmal in Cursor hängen und den Create-and-Validate-Loop an einem echten Content-Stück durchspielen. Der Unterschied zwischen „klingt gut“ und „kommt bei der Zielgruppe an“ kostet danach einen Tool-Call statt einer Panel-Studie.
Quellenverzeichnis
[1] Vlahovic, Donald (2026): „Content erstellen und ihn direkt an einer echten Zielgruppe testen, aus deinem Agenten heraus.“ neuroflash. https://neuroflash.synaps.media/api-mcp-launch-de/
[2] neuroflash (2026): „MCP-Server: Übersicht und Dokumentation.“ https://neuroflash.com/digital-twins-mcp und https://neuro-flash.github.io/mcp-server/index.html
[3] neuroflash (2026): „API-Übersicht und API-Dokumentation.“ https://neuroflash.com/digital-twins-api und https://neuro-flash.github.io/api-docs/
[4] neuroflash (2026): „Digital Twins: Methodik und Datenbasis.“ https://neuroflash.com/digital-twins-api