Die Entwicklung von mehrsprachiger KI hat mit Teuken 7B, dem neuesten Sprachmodell der OpenGPT-X-Initiative, einen neuen Meilenstein erreicht. Teuken 7B wurde entwickelt, um die sprachliche Vielfalt Europas anzugehen und hebt sich als innovative Lösung hervor, die auf die einzigartigen Herausforderungen der mehrsprachigen Kommunikation und des KI-Einsatzes auf dem gesamten Kontinent zugeschnitten ist. In diesem Artikel werden wir die wichtigsten Merkmale untersuchen, einschließlich der Vorab-Trainingsdaten, der mehrsprachigen Tokenisierung, der Modellarchitektur, des Trainingsprozesses, der Zugriffsarten und der Einschränkungen.
Einführung von Teuken 7B: Eine mehrsprachige KI für Europa
Teuken 7B ist ein großes Sprachmodell (LLM), das speziell entwickelt wurde, um die 24 Amtssprachen Europas zu verarbeiten. Im Gegensatz zu den meisten KI-Modellen, die stark auf Englisch fokussiert sind, bietet Teuken 7B eine robuste Unterstützung für eine Vielzahl von Sprachen, von weit verbreiteten wie Deutsch und Französisch bis hin zu weniger häufig genutzten Sprachen wie Finnisch und Maltesisch. Durch die Priorisierung sprachlicher Inklusivität und mehrsprachiger Effizienz positioniert es sich als ein Game-Changer für Regierungen, Unternehmen und Forscher in ganz Europa.
Key Features
Europäen-zentriertes Training: Im Gegensatz zu vielen bestehenden Sprachmodellen, die überwiegend auf Englisch oder Chinesisch fokussiert sind, ist Teuken 7B auf die sprachliche Vielfalt Europas zugeschnitten und sorgt für eine robuste Leistung in mehreren europäischen Sprachen.
Benutzerdefinierter mehrsprachiger Tokenizer: Um die Effizienz zu steigern, wurde ein spezialisierter Tokenizer für die 24 EU-Sprachen entwickelt. Dieser Ansatz verringert die Fragmentierung in nicht-englischen Texten, was zu effizienteren Trainings- und Inferenzprozessen führt.
Open-Source-Kollaboration: Das Modell ist Open Source, was die Zusammenarbeit zwischen Forschern, Entwicklern und KI-Enthusiasten fördert, um die KI-Landschaft Europas weiter voranzutreiben.
Anweisungsoptimiert: Teuken 7B wurde mit einer Anweisungstuning-Methode versehen, die seine Fähigkeit verbessert, menschliche Anweisungen effektiv über verschiedene Aufgaben und Sprachen hinweg zu befolgen.
Die Entwicklung von Teuken 7B unterstreicht Europas Engagement für die Weiterentwicklung von KI-Technologien, die seine kulturelle und sprachliche Vielfalt widerspiegeln und Inklusivität sowie Repräsentation im digitalen Raum fördern.
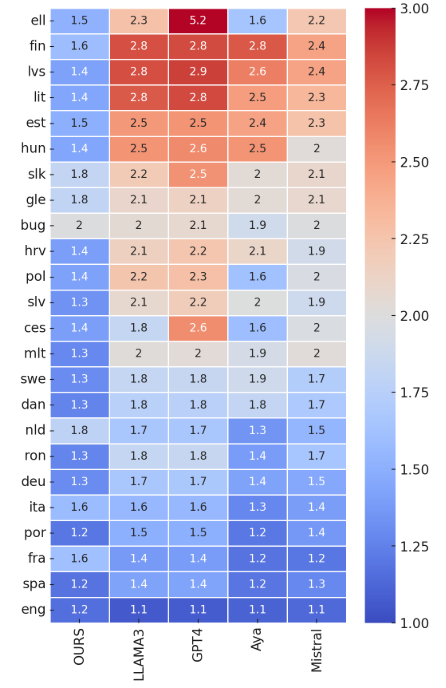
Teuken 7B : Daten vor dem Training
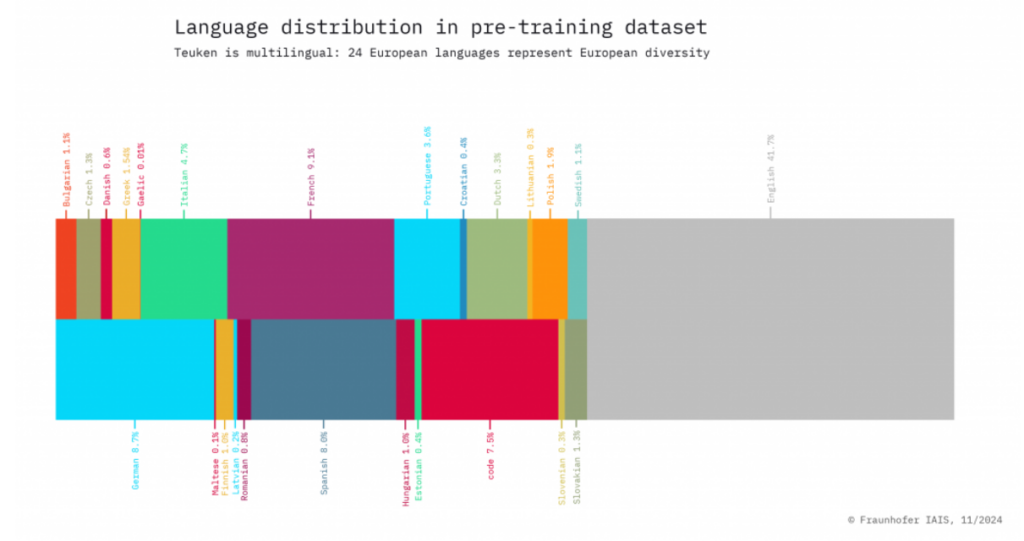
Ein Eckpfeiler der Fähigkeiten von Teuken 7B ist seine qualitativ hochwertige Vorab-Trainingsdatenbasis. Etwa 60 % des Datensatzes bestehen aus nicht-englischen Inhalten, wodurch das Modell in europäischen Sprachen besonders leistungsfähig ist. Die Vorab-Training-Pipeline setzte auf strenge Qualitätskontrollen, bei denen über 90 % des ursprünglichen Datensatzes herausgefiltert wurden, um Relevanz und Zuverlässigkeit zu gewährleisten. Dieser sorgfältige Ansatz stellt sicher, dass die Antworten des Modells genau, kontextuell angemessen und sprachlich nuanciert sind, was es besonders wertvoll für Anwendungen wie Übersetzungen, Sentiment-Analyse und Inhaltserstellung macht.
Mehrsprachige Tokenisierung und Effizienz
Eine der herausragenden Innovationen von Teuken 7B ist sein benutzerdefinierter mehrsprachiger Tokenizer. Tokenisierung, der Prozess, Texte in kleinere Einheiten zu zerlegen, ist entscheidend für Sprachmodelle. Generische Tokenizer haben oft Schwierigkeiten mit europäischen Sprachen, insbesondere solchen mit zusammengesetzten Wörtern (z.B. Deutsch: Lebensmittelgeschäft) oder agglutinativen Strukturen (z.B. Finnisch: taloissammekaan).
Der Tokenizer von Teuken 7B minimiert die Fragmentierung, bewahrt die semantische Bedeutung und verbessert die Effizienz des Modells. Diese Optimierung reduziert den Rechenaufwand und steigert gleichzeitig die Fähigkeit des Modells, Texte in verschiedenen Sprachen zu verstehen und zu generieren.
Modell der Architektur
Teuken 7B verfügt über eine sorgfältig gestaltete Architektur mit 7 Milliarden Parametern. Diese Größe stellt eine Balance zwischen rechnerischer Effizienz und Leistung dar, wodurch es in der Lage ist, komplexe linguistische Aufgaben zu bewältigen und gleichzeitig für Forschung und Anwendungen zugänglich zu bleiben. Das Modell nutzt moderne transformer-basierte Techniken, um qualitativ hochwertige Ergebnisse in einer Vielzahl von Aufgaben zu liefern, darunter Textzusammenfassung, Fragebeantwortung und Übersetzung.
Trainingsprozess von Teuken 7B
Teuken 7B wurde mit dem JUWELS-Supercomputer am Forschungszentrum Jülich, einer der führenden Recheneinrichtungen Europas, trainiert. Dieses Training nutzte fortschrittliche Techniken, um Effizienz und Skalierbarkeit zu maximieren. Die Zusammenarbeit zwischen OpenGPT-X und europäischer Recheninfrastruktur unterstreicht das Engagement, KI-Lösungen zu schaffen, die regionale Bedürfnisse und Herausforderungen effektiv adressieren.
Der benutzerdefinierte mehrsprachige Tokenizer
Der benutzerdefinierte mehrsprachige Tokenizer in Teuken 7B ist eine entscheidende Innovation, die Herausforderungen bei der Verarbeitung von Texten aus verschiedenen Sprachen adressiert. Hier ist, warum er wichtig ist:
- Minimierung der Textfragmentierung: Ein Tokenizer zerlegt Texte in kleinere Einheiten, sogenannte Tokens. Generische Tokenizer, die oft für Englisch entwickelt wurden, können Wörter in anderen Sprachen unangemessen fragmentieren. Zum Beispiel:
- Im Deutschen sind zusammengesetzte Wörter (z.B. Lebensmittelgeschäft) üblich. Ein generischer Tokenizer könnte es in nicht zusammenhängende Teile zerlegen, was zu einem Verlust des Kontexts führt.
- Im Finnischen können agglutinative Wörter wie taloissammekaan (was „nicht einmal in unseren Häusern“ bedeutet) von generischen Tokenizern missverstanden werden. Der benutzerdefinierte Tokenizer für Teuken 7B minimiert eine solche Fragmentierung und sorgt dafür, dass die Tokens semantisch sinnvoll bleiben.
- Optimiert für 24 EU-Sprachen: Durch die Anpassung des Tokenizers an die Nuancen europäischer Sprachen kann Teuken 7B Texte effizienter verarbeiten und seine Genauigkeit in Aufgaben wie Übersetzung, Sentiment-Analyse und Zusammenfassung verbessern.
- Effizienzsteigerungen: Ein effektiverer Tokenizer reduziert die Rechenkosten für Training und Inferenz. Dies ist besonders wertvoll in mehrsprachigen Umgebungen, in denen die Handhabung unterschiedlicher Schriftsysteme und grammatikalischer Strukturen ansonsten ressourcenintensiv sein kann.
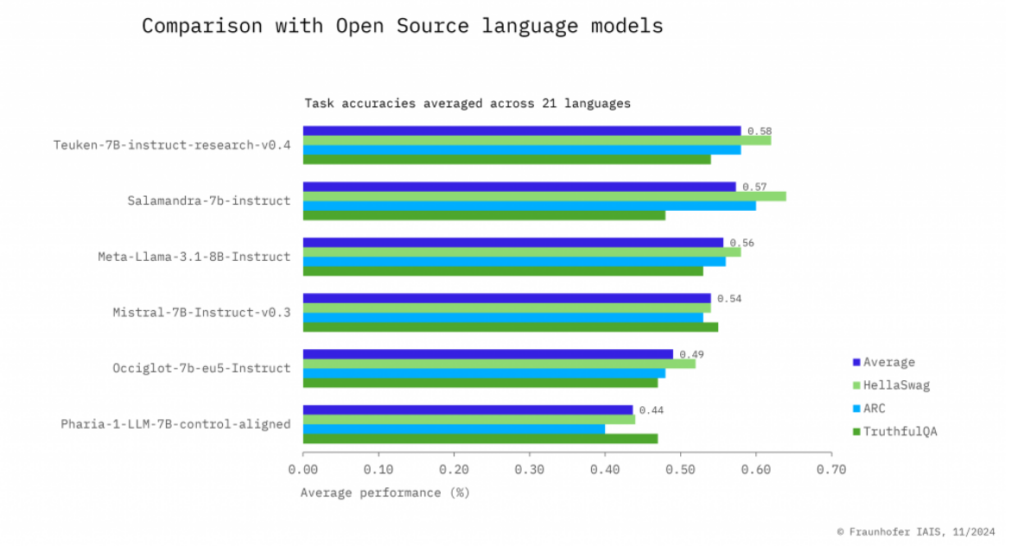
Wie unterscheidet sich Teuken 7B von anderen Sprachmodellen?
Teuken 7B hebt sich durch seinen mehrsprachigen Fokus und das europazentrierte Design hervor, was es in folgenden Aspekten unterscheidet:
- Priorisierung von Nicht-Englischen Sprachen: Im Gegensatz zu den meisten großen Sprachmodellen (LLMs), die einen erheblichen Großteil ihrer Trainingsdaten auf Englisch ausrichten (z.B. GPT-3, BERT), stellt Teuken 7B sicher, dass über 50 % seiner Trainingsdaten in nicht-englischen europäischen Sprachen vorliegen. Dies verbessert seine Leistung in Sprachen wie Deutsch, Französisch, Italienisch und sogar weniger weit verbreiteten Sprachen wie Finnisch oder Maltesisch.
- Speziell für europäische Sprachen entwickelt: Es verwendet Datensätze, die speziell aus europäischen Quellen zusammengestellt wurden, und erfasst die einzigartige Grammatik, Syntax und idiomatische Ausdrücke dieser Sprachen. Dies ist entscheidend für Aufgaben wie Übersetzungen oder die Erstellung lokalisierter Inhalte.
- Open Source und Ethik in der KI: Viele andere fortschrittliche LLMs sind proprietär, was bedeutet, dass sie nicht öffentlich zugänglich sind. Teuken 7B ist Open Source, fördert Transparenz und Zusammenarbeit und steht im Einklang mit Europas ethischen KI-Initiativen.
- Effizienz durch Anweisungstuning: Teuken 7B wurde mit Benutzeranweisungen im Hinterkopf entwickelt, wodurch es geschickt darin ist, Aufgaben in verschiedenen Sprachen zu verstehen und darauf zu reagieren. Das anweisungstuned Training unterscheidet es von älteren Modellen, die oft für jede neue Aufgabe feinabgestimmt werden mussten.
Was ist Instruktionstuning?
Typischerweise werden LLMs mit großen Mengen an Text trainiert, um das nächste Wort in einer Sequenz vorherzusagen, was ihnen hilft, die Sprachstruktur zu lernen. Anweisungstuning geht einen Schritt weiter, indem es das Modell darauf trainiert, gezielt auf strukturierte Anweisungen von Benutzern zu reagieren.
Beispielsweise kann ein anweisungstuned Modell auf Aufforderungen wie „Fasse diesen Artikel auf Französisch zusammen“ oder „Übersetze diesen Text ins Deutsche“ reagieren, anstatt einfach einen Satz zu vervollständigen.
Warum ist das wichtig für Teuken 7B?
Mehrsprachige Komplexität: Die Verarbeitung strukturierter Anweisungen in mehreren Sprachen erfordert ein nuanciertes Verständnis. Anweisungstuning stellt sicher, dass Teuken 7B nicht nur in der Lage ist, eine einzelne Sprache zu verstehen, sondern auch zwischen Sprachen zu wechseln, je nach den Anfragen der Benutzer.
Aufgabenanpassungsfähigkeit: Teuken 7B kann verschiedene Aufgaben (Übersetzungen, Zusammenfassungen, Beantwortung von Fragen usw.) bewältigen, ohne dass für jede Aufgabe umfangreiches Nachtraining erforderlich ist. Diese Flexibilität verringert die Bereitstellungszeit und die Kosten für Benutzer.
Vergleich zu nicht getunten Modellen: Modelle ohne Anweisungstuning erfordern oft manuelle Eingriffe oder zusätzliche aufgabenspezifische Feinabstimmungen, um ähnliche Ergebnisse zu erzielen. Das Anweisungstuning von Teuken 7B macht es effizient und sofort einsatzbereit für eine Vielzahl von Anwendungen.
Zugang zu Teuken 7B
Als Open-Source-Modell ist Teuken 7B für Forscher, Entwickler und Organisationen kostenlos zugänglich. Es wird auf Plattformen wie Hugging Face gehostet, was die Integration in verschiedene Anwendungen erleichtert. Durch die Priorisierung von Offenheit und Zusammenarbeit steht Teuken 7B im Einklang mit Europas ethischen KI-Initiativen und fördert Innovationen in der Entwicklung mehrsprachiger KI.
Für den direkten Zugriff besuche das Hugging Face-Repository für Teuken 7B oder buche eine Demo beim Fraunhofer IAIS.
Teuken 7B Beschränkungen:
- Sprachrepräsentation: Die Leistung des Modells kann je nach Sprache variieren, insbesondere bei Sprachen, die im Trainingsdatensatz weniger vertreten sind.
- Vorurteile in den Trainingsdaten: Wie bei vielen KI-Modellen können Vorurteile in den Trainingsdaten die Ergebnisse beeinflussen. Es werden weiterhin Anstrengungen unternommen, um diese Probleme zu mindern und die Fairness zu verbessern.
- Rechenanforderungen: Obwohl optimiert, benötigt das Modell weiterhin erhebliche Rechenressourcen für Feinabstimmungen und groß angelegte Bereitstellungen.
Diese Herausforderungen heben Bereiche für zukünftige Forschung und Entwicklung hervor, um die Fähigkeiten von Teuken 7B weiter zu verbessern.
Nutzen Sie die beste GPT-Alternative für mehrsprachige Ergebnisse: neuroflash!
neuroflash nutzt die Leistung von GPT-3.5 und GPT-4, um hochwertige Inhalte in mehreren Sprachen zu erzeugen, wodurch Sprachbarrieren überwunden und neue Möglichkeiten für Kommunikation und Interaktion eröffnet werden. Derzeit ist neuroflash in der Lage, Texte in Deutsch, Englisch, Spanisch, Katalanisch, Französisch, Polnisch, Italienisch, Niederländisch, Kroatisch, Ungarisch, Portugiesisch, Tschechisch, Schwedisch, Türkisch und Chinesisch zu erstellen. Diese umfangreiche sprachliche Fähigkeit stellt sicher, dass deine Inhalte ein breites und vielfältiges Publikum erreichen können, das verschiedene Regionen und kulturelle Nuancen berücksichtigt.

Stell dir vor, du könntest nahtlos ansprechende, relevante und kontextuell angemessene Inhalte für eine so große Anzahl an Sprachen erstellen. Ob für Marketingtexte, akademische Artikel, Kundenservice-Antworten oder kreative Texte – neuroflash hebt sich als das beste KI-Content-Tool mit der Leistung der GPT-4-Technologie hervor. Die Fähigkeit, qualitativ hochwertige Inhalte in verschiedenen Sprachen zu generieren, verbessert nicht nur die Kommunikation, sondern fördert auch erheblich Inklusivität und Zugänglichkeit.
Fazit
Teuken 7B ist ein Beispiel für einen engagierten Versuch, ein mehrsprachiges KI-Modell zu schaffen, das Europas reiche sprachliche Vielfalt widerspiegelt und bedient. Seine Entwicklung zeigt das Potenzial kollaborativer, Open-Source-KI-Initiativen, regionale Bedürfnisse zu adressieren. Während sich Teuken 7B weiterentwickelt, bietet es vielversprechende Möglichkeiten, um inklusivere und effektivere KI-Anwendungen in ganz Europa zu ermöglichen.